客快物流大数据项目(四十四):Spark操作Kudu创建表

【摘要】
Spark操作Kudu创建表
Spark与KUDU集成支持:
DDL操作(创建/删除)本地Kudu RDDNative Kudu数据源,用于DataFrame集成从kudu读取数据从Kudu执行插入/更新/ upsert /删除谓词下推Kudu和Spark SQL之间的模式映射到目前为止,我们已经听说过几个上下文,例如Spark...
Spark操作Kudu创建表
- Spark与KUDU集成支持:
- DDL操作(创建/删除)
- 本地Kudu RDD
- Native Kudu数据源,用于DataFrame集成
- 从kudu读取数据
- 从Kudu执行插入/更新/ upsert /删除
- 谓词下推
- Kudu和Spark SQL之间的模式映射
- 到目前为止,我们已经听说过几个上下文,例如SparkContext,SQLContext,HiveContext, SparkSession,现在,我们将使用Kudu引入一个KuduContext。这是可以在Spark应用程序中广播的主要可序列化对象。此类代表在Spark执行程序中与Kudu Java客户端进行交互。
- KuduContext提供执行DDL操作所需的方法,与本机Kudu RDD的接口,对数据执行更新/插入/删除,将数据类型从Kudu转换为Spark等。
创建表
- 定义kudu的表需要分成5个步骤:
- 提供表名
- 提供schema
- 提供主键
- 定义重要选项;例如:定义分区的schema
- 调用create Table api
- 代码开发
-
package cn.it
-
-
import java.util
-
import cn.it.SparkKuduDemo.TABLE_NAME
-
import org.apache.kudu.client.CreateTableOptions
-
import org.apache.kudu.spark.kudu.KuduContext
-
import org.apache.spark.{SparkConf, SparkContext}
-
import org.apache.spark.sql.SparkSession
-
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
-
-
object SparkKuduTest {
-
def main(args: Array[String]): Unit = {
-
//构建sparkConf对象
-
val sparkConf: SparkConf = new SparkConf().setAppName("SparkKuduTest").setMaster("local[2]")
-
-
//构建SparkSession对象
-
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
-
-
//获取sparkContext对象
-
val sc: SparkContext = sparkSession.sparkContext
-
sc.setLogLevel("warn")
-
-
//构建KuduContext对象
-
val kuduContext = new KuduContext("node2:7051", sc)
-
-
//1.创建表操作
-
createTable(kuduContext)
-
-
/**
-
* 创建表
-
*
-
* @param kuduContext
-
* @return
-
*/
-
def createTable(kuduContext: KuduContext) = {
-
//如果表不存在就去创建
-
if (!kuduContext.tableExists(TABLE_NAME)) {
-
-
//构建创建表的表结构信息,就是定义表的字段和类型
-
val schema: StructType = StructType(
-
StructField("userId", StringType, false) ::
-
StructField("name", StringType, false) ::
-
StructField("age", IntegerType, false) ::
-
StructField("sex", StringType, false) :: Nil)
-
-
//指定表的主键字段
-
val keys = List("userId")
-
-
//指定创建表所需要的相关属性
-
val options: CreateTableOptions = new CreateTableOptions
-
//定义分区的字段
-
val partitionList = new util.ArrayList[String]
-
partitionList.add("userId")
-
//添加分区方式为hash分区
-
options.addHashPartitions(partitionList, 6)
-
-
//创建表
-
kuduContext.createTable(TABLE_NAME, schema, keys, options)
-
}
-
}
-
}
-
}
定义表时要注意的是Kudu表选项值。你会注意到在指定组成范围分区列的列名列表时我们调用“asJava”方 法。这是因为在这里,我们调用了Kudu Java客户端本身,它需要Java对象(即java.util.List)而不是Scala的List对 象;(要使“asJava”方法可用,请记住导入JavaConverters库。) 创建表后,通过将浏览器指向http//master主机名:8051/tables
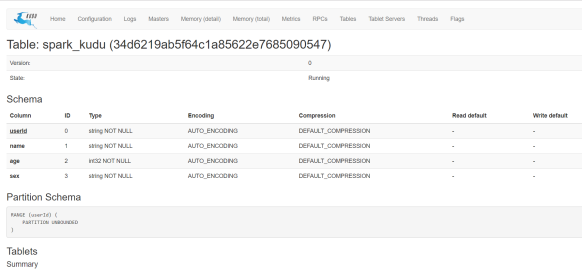
- 来查看Kudu主UI可以找到创建的表,通过单击表ID,能够看到表模式和分区信息。
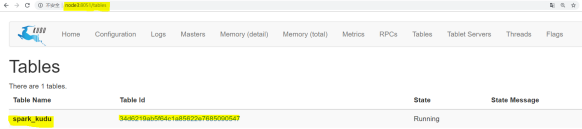
点击Table id 可以观察到表的schema等信息:
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/123030460

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)