华为云ModelArts结合AnimeGANv2,让照片在云上动漫化 丨【华为云AI贺新年】

其实早在接触华为云的ModelArts之前,我就试过在一些科技公众号上传照片玩过动漫化,甚至也试过在本地IDE上自己编码看着程序帮我给照片动漫化;但是前者是个“黑盒子”,我不知道里面发生了啥(程序做了什么操作?会不会背着我把照片上传到服务端?);而后者限定在了自己的开发环境里,如果离开了我那台开发电脑,在别的电脑上我又得重新搭环境重新编码,费时费力。
这时候,我接触到了华为云的ModelArts,作为一款“是面向AI开发者的一站式开发平台,能够支撑开发者从数据到AI应用的全流程开发过程;提供海量数据预处理及半自动化标注、大规模分布式训练、自动化模型生成及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流”【1】,它帮助我解决了上面的两个难题。即我又可以看到代码都是怎么样的,又可以在云上进行操作,代码对用户而言透明,安全隐私有保障。
我又去了解了下ModelArts的对标产品谷歌的AutoML;在后面整个流程摸索下来之后结合网上的评论【2】,我觉得华为云的ModelArts产品更适合不会代码的小白,可以助力小白零代码实现模型从数据集标注到部署的全部流程;而谷歌的AutoML还得用户自己配置Docker容器和Kubernetes,相对来说更难以上手。
那么接下去我们步入正题,跟着华为云社区给出的指南文章“AnimeGANv2照片动漫化”,一起去玩一下怎么让我们本地上传的照片在云上动漫化吧。
介绍一下AnimeGANv2
其实先前自己在本地开发环境礼搭建搭建程序的时候,就用的python和AnimeGANv2;python语言简单易懂,代码不需要过多解释就可以了解其意图,且可以调用的包种类繁多;而AnimeGANv2“可以将现实场景的图片处理为动漫画分,目前支持宫崎骏、新海诚和今敏的三种风格”【3】。
感兴趣的小伙伴可以看下AnimeGANv2 这篇论文《AnimeGAN: A Novel Lightweight GAN for Photo Animation》。论文的简介我翻译一下如下:
“本文提出了一种将真实场景照片转换成动画风格图像的新方法,这在计算机视觉和艺术风格转换方面是一项有意义且具有挑战性的任务。我们提出的方法结合了神经风格传递和生成式对抗网络(gan)来实现这一任务。对于这个任务,(论文之前)现有的一些方法并没有取得令人满意的动画效果。现有的方法通常存在一些问题,其中比较突出的问题主要有:1)生成的图像没有明显的动画风格纹理; 2)生成的图像丢失了原始图像的内容; 3)网络参数要求较大的内存容量。 在本文中,我们提出了一种新颖的轻量级生成式对抗网络,称为AnimeGAN,以实现动画风格的快速转换。此外,我们进一步提出了三种新颖的损失函数,使生成的图像具有更好的动画视觉效果。这些损失函数分别是灰度样式损失、灰度对抗损失和颜色重建损失。提出的AnimeGAN可以很容易地用未配对的训练数据进行端到端训练。AnimeGAN参数对内存的要求较低。实验结果表明,我们的方法可以快速地将真实世界的照片转换成高质量的动画图像,并优于目前最先进的方法。”
ModelArts云上动漫化
我们可以直接在AnimeGANv2照片动漫化网页这,点击"Run in ModelArts"的按钮进入ModelArts页面:
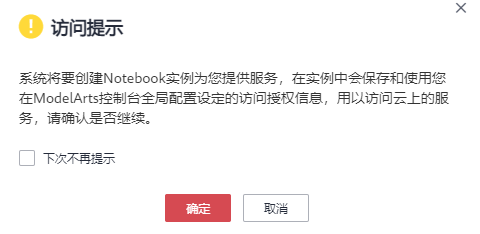
进入页面之后,会跳出一个访问提示,告诉我们“系统将要创建Notebook实例为您提供服务”,点击确定即可:
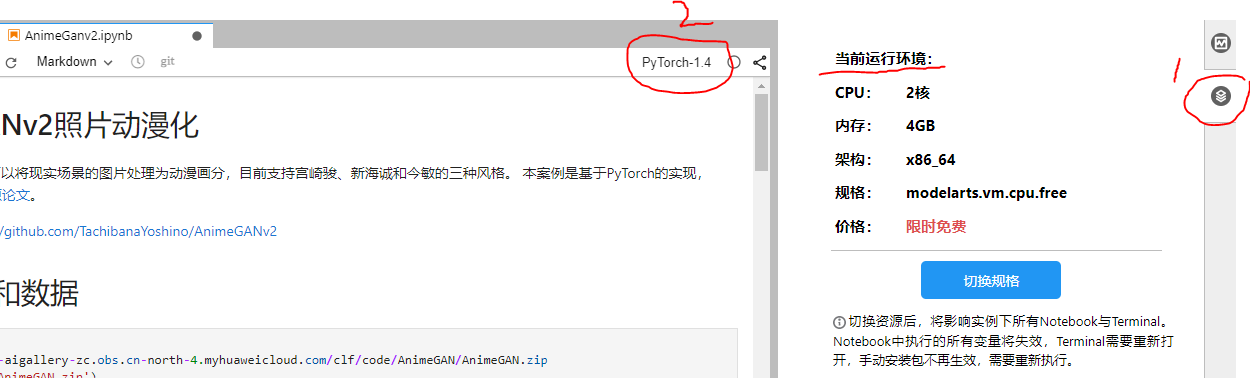
等待页面加载成功之后,会在页面显示“资源管理器”(resource manager)里关于当前运行环境的内容(下图1中的内容);我们还需要选择一下当前实例里需要的kernel(因为指南文档里写的是“基于PyTorch的实现”,因此kernel里我们就选择PyTorch即可):
1. 获取代码和数据
我们可以把鼠标放在import这一代码框里点击选择,然后到下图我画红圈的地方点击运行代码:
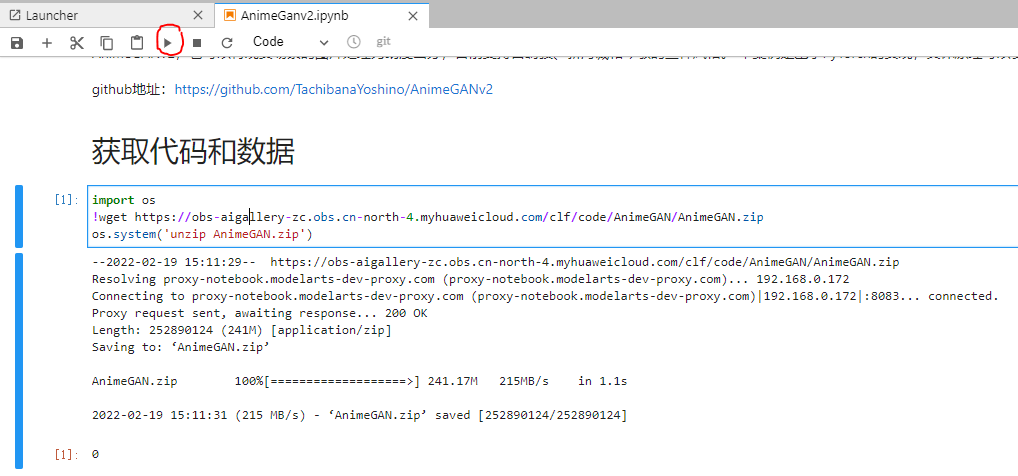
这一步的下载安装非常快。上述的代码会把os包导入到实例中(os包包含普遍的操作系统功能),然后通过wget的方式从网络中下载下来AnimeGAN.zip这个资源压缩包,再通过os的命令把压缩包解压。
2. 安装依赖库
第二步,我们去安装PyTorch需要的各个依赖包;和1中一样的方法,鼠标先选择!pip install dlib这一代码框,然后点击运行代码:
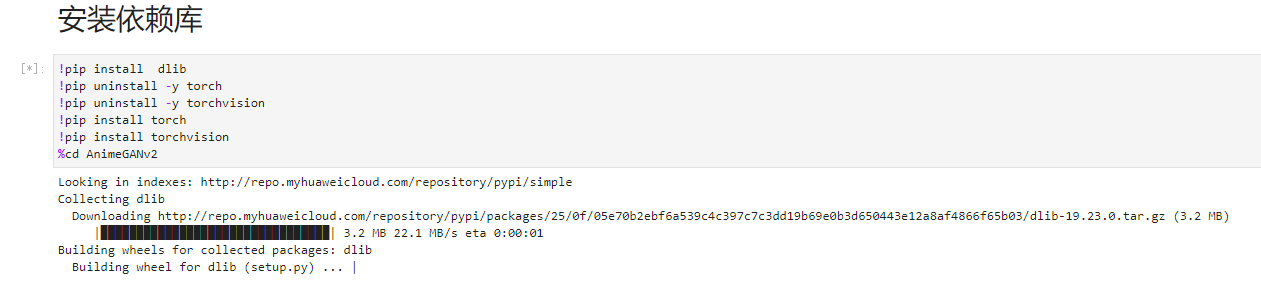
我在这一步被卡着了,状态界面会卡在“Building wheels for collected packages: dlib;Building wheel for dlib (setup.py) … /”并有弹窗提醒“Invalid response: 503 Service Unavailable”,显示为服务器出错的返回状态:
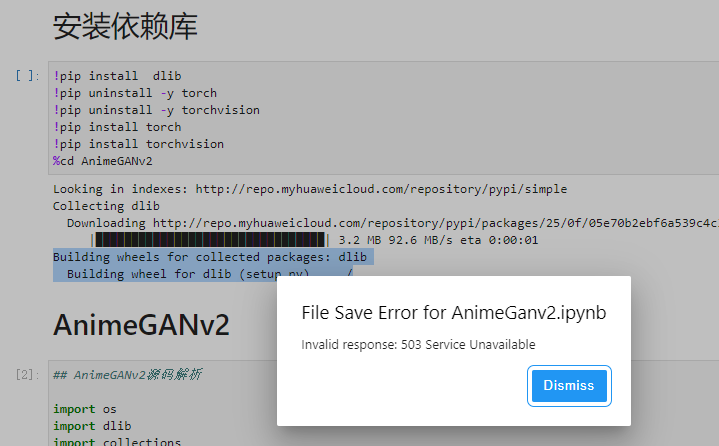
虽然下载失败,但我们可以看下具体下载了哪些依赖库。
- dlib是一个使用现代C++技术编写的跨平台的通用库,遵守Boost Software licence。是一个机器学习的开源库,包含了机器学习的很多算法。
- torach,又称为python torch,是一个以Python优先的深度学习框架,一个开源的Python机器学习库,用于自然语言处理等应用程序,不仅能够实现强大的GPU加速,同时还支持动态神经网络,这是现在很多主流框架比如Tensorflow等都不支持的。
- torchvision,该包由流行的数据集、模型架构和常见的计算机视觉图像转换组成。
下载玩依赖库之后,进入AnimeGANv2这个文件夹。
3. AnimeGANv2源码解析
因为我在第二步中的依赖包没有下载成功,因此就只能对下面的源代码进行学习分析,看看都执行了哪些操作。
首先,我们去下载模型文件“shape_predictor_68_face_landmarks.dat”,获取到dlib里的前脸检测器和形状检测器,再创建一个脸部标志检测函数
def get_dlib_face_detector(predictor_path: str = "shape_predictor_68_face_landmarks.dat"):
// XXXXXX
return detect_face_landmarks
接着,我们创建一个展示脸部标志的函数,通过一个Python的2D绘图库Matplotlib来绘图展示:
def display_facial_landmarks(
img: Image,
landmarks: List[np.ndarray],
fig_size=[15, 15]
):
// XXXXXX
plt.show()
然后,按照https://github.com/NVlabs/ffhq-dataset/blob/master/download_ffhq.py 文件里开发好的方法,利用Python图像处理的PIL模块,用来存储和处理大型矩阵的numpy库 和 多维图像处理包的scipy.ndimage模块在函数align_and_crop_face里,将五官数据转为数组,计算辅助向量,提取矩形框,缩放,裁剪,填充数据,转化图片;最后返回这个image:
def align_and_crop_face(
img: Image.Image,
landmarks: np.ndarray,
expand: float = 1.0,
output_size: int = 1024,
transform_size: int = 4096,
enable_padding: bool = True,
):
// XXXXXX
return img
然后是怎么用PyTorch去实现AnimeGANv2。Github代码仓地址:https://github.com/bryandlee/animegan2-pytorch 。
需要导入sys.path.append("animegan2-pytorch"),然后在函数face2paint里,得到图片的尺寸,进行裁剪,尺寸变化,最后返回使用了torchvision里toPILImage函数来输出。
def face2paint(
img: Image.Image,
size: int,
side_by_side: bool = True,
) -> Image.Image:
// XXXXXX
return to_pil_image(output)
最后通过函数inference_from_file,把图片所在的路径输入进去,最后返回出动漫化图片。
def inference_from_file(filepath):
img = Image.open(filepath).convert("RGB")
face_detector = get_dlib_face_detector()
landmarks = face_detector(img)
display_facial_landmarks(img, landmarks, fig_size=[5, 5])
for landmark in landmarks:
face = align_and_crop_face(img, landmark, expand=1.3)
display(face2paint(face, 512))
inference_from_file('4.jpg')
当然,还有一种方式就是不是本地上传图片,而是通过线上url的方式传递图片:
import requests
def inference_from_url(url):
img = Image.open(requests.get(url, stream=True).raw).convert("RGB")
face_detector = get_dlib_face_detector()
landmarks = face_detector(img)
display_facial_landmarks(img, landmarks, fig_size=[5, 5])
for landmark in landmarks:
face = align_and_crop_face(img, landmark, expand=1.3)
display(face2paint(face, 512))
inference_from_url("https://obs-aigallery-zc.obs.cn-north-4.myhuaweicloud.com/clf/code/AnimeGAN/6.jpg")
animegan2-pytorch Github里的示例图如下:




体会及建议:
首先,作为一名程序员,可以感受到华为云ModelArts想做出一款好产品好平台的良苦用心。打开平台链接到开启实例,用户需要等待的准备时间并不长,这点很让人满意。下载小的依赖库速度很快,但是在下载多个比较大的依赖库的时候,会有503错误显示是我没想到的。这里华为云作为国内领先的云服务商,确实不太应该(当然我也不排除可能是因为我这网络的原因,但是我这1没开proxy,2本地下载都没问题,本地网络问题的几率不太大)。
我感觉到了华为云想做好产品的决心,但因为下载的失败让我没感受到华为云AI的强大实属有点遗憾。整个案例如果能感受下来全流程,这对于用户零门槛入门AI或则对AI产生兴趣确实帮助很大。
还有一点要吐槽的是,我在点击进入ModelArts之后,并没有什么指导文档或则引导,让刚开始接触ModelArts的用户会丈二和尚摸不着头脑。特别是需要我们自己去选择kernel这一步,我这次就是折腾了一些时间去摸索各个按钮都是什么,我才搞清怎么把代码运行起来。希望华为云可以多一点指南文档和引导,有更多的提示,多站在用户的角度,才能让用户花更少的时间去了解这款产品,喜欢上这款产品。
参考资料
- https://support.huaweicloud.cn/productdesc-modelarts/modelarts_01_0001.html
- https://bbs.huaweicloud.cn/forum/forum/thread-84731-1-1.html
- https://developer.huaweicloud.cn/develop/aigallery/notebook/detail?id=6473b148-f59d-4064-84b6-2b6d78ec546c
活动宣传
【华为云AI贺新年】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/325842

- 点赞
- 收藏
- 关注作者
评论(0)