语义级代码克隆检测数据集的评估与改进

一、背景介绍
代码克隆检测[1]是软件工程领域一个很重要的研究方向。代码克隆不必要地增加了软件系统的大小。一个系统越大,需要维护的开销就越高。为了检测和管理代码克隆,研究者把代码克隆分为四类[2]:
- 类型一是除了注释、空格、换行之外,完全相同的代码片段;
- 类型二是在类型一的基础上,除了类型名、变量名以及常量名之外,完全相同的代码片段;
- 类型三是在类型二的基础上,有少量语句的增加、删除、修改;
- 类型四是指实现的功能相同,但实现的方法完全不同。
在代码克隆成为一个软件工程的研究方向以来,许多非深度学习的方法都专注在检测类型一、二、三的克隆,但是在检测语义代码克隆(中等类型三、弱类型三以及类型四)上取得的进展很有限。这是因为非深度学习的方法没有识别在词法以及语法级别实现很不相同,但属于语义代码克隆的代码对(例如冒泡排序和快速排序)。
基于一个带标记的数据集(如BigCloneBench[3]),研究者提出许多基于深度学习的方法来检测语义代码克隆[4][5]。他们的实验结果展示了他们的方法可以有效的检测语义代码克隆。基于深度学习的方法可以有效的检测语义代码克隆是因为这些方法可以从训练集中学习到语义代码克隆的语义信息。
然而目前还尚未有工作研究BigCloneBench数据集是否真的能够用来验证语义代码克隆检测方法的有效性。在本篇文章中[6],我们首先发现BigCloneBench数据集的语义代码克隆对使用相似的标识符,而非语义代码克隆对的标识符不相似。接着文章提出了一个不合理(undesirable-by-design)的克隆检测模型(名为Linear-Model),通过只考虑那些标识符在代码克隆片段中出现来检测代码语义代码克隆。这个不合理的模型可以达到跟其他被验证有效的方法一样的效果。为了减轻这个问题,我们通过抽象BigCloneBench数据集中的一部分标识符(类型名、变量名以及方法名)得到AbsBigCloneBench数据集。实验结果表明AbsBigCloneBench数据集能够更好的验证语义代码克隆检测方法的有效性,同时使用AbsBigCloneBench数据集训练的模型在BigCloneBench数据集测试依然有效,而使用BigCloneBench数据集训练的模型在AbsBigCloneBench数据集测试却无效。
二、BigCloneBench数据集分析
BigCloneBench数据集由Svajlenko等人[3]提出,它是从IJaDataset[7]中挖掘而来,并且由三个专家手动确认。IJaDataset包含25000个项目,3.65亿行代码。BigCloneBench包含10类问题以及600万克隆对和26万非克隆对。BigCloneBench将类型三的代码克隆分为弱、中、强和非常强四类。表1展示了BigCloneBench数据集中每个类型的代码克隆对占比,超过98%的代码克隆对属于语义代码克隆。
表1:BigCloneBench数据集中每个克隆类型的占比

1. BigCloneBench不同问题之间标识符的Jaccard相似系数分析
算法1展示了我们统计BigCloneBench数据集的不同问题之间标识符的Jaccard相似系数分析的流程图。我们首先得到每一个问题出现频率最高的20个标识符。然后我们计算两两问题之间的标识符的Jaccard相似系数,由于BigCloneBench数据集中包含10个问题,因此我们最终会得到45个相似系数。最后我们对这45个相似系数取平均作为数据集的不同问题之间的Jaccard相似系数。BigCloneBench数据集不同问题之间的标识符的Jaccard相似系数为0.038,它表明BigCloneBench数据集不同问题之间的标识符很不相同。

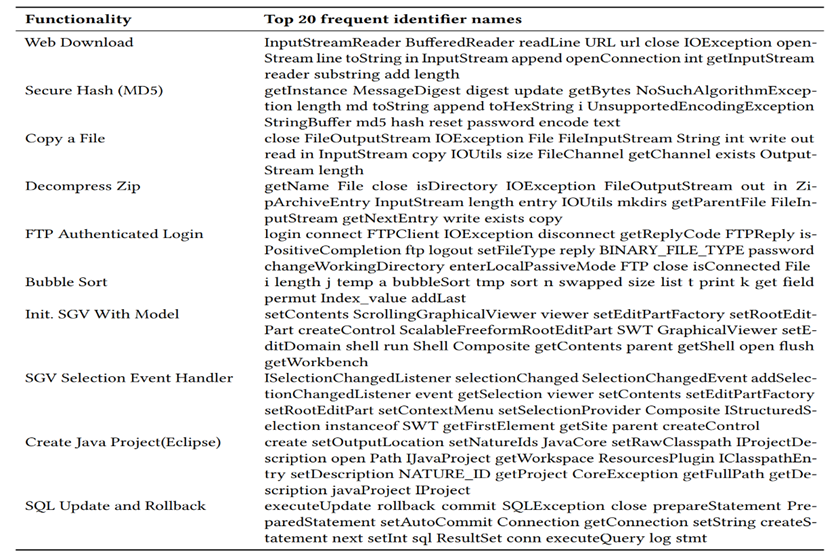
表2详细展示了BigCloneBench数据集中每类问题的前20个标识符名字。我们用同样的方法分析了OJClone数据集[11](另一个被广泛使用的语义代码克隆检测数据集)的不同问题之间的标识符的Jaccard相似系数为0.469,它表明OJClone数据集的不同问题之间的标识符比较相同。导致差异的原因是BigCloneBench数据集是从真实项目中挖掘到的,实现同一个问题时,往往会用到相同的第三方库的类以及Java基础类。而OJClone是通过学生提交的编程题构造而来,这些编程题往往是基础的算法,学生一般很少引用第三方库,在定义变量名时,一般都会定义i、j、k、n等。
表2:BigCloneBench数据集中每类问题的前20个标识符名字
2. BigCloneBench数据集和现实世界中的语义代码克隆示例
图1和图2展示了一个BigCloneBench数据集中的语义代码克隆包含相似的标识符的例子和Stack Overflow中的一个语义代码克隆包含不相似的标识符的例子。这两个例子可以说明现实世界中确实存在不依赖标识符的语义代码克隆,而BigCloneBench数据集中的语义代码克隆依赖标识符的问题应该需要被重视和提升。

图1:BigCloneBench数据集中具有相似标识符的语义代码克隆示例

图2:Stack Overflow具有不相似标识符的语义代码克隆示例
三、不合理的克隆检测模型
本节展示了我们设计的不合理的克隆检测模型(名为Linear-Model)的整体架构以及具体的技术细节。
1. 整体架构
图3展示了Linear-Model的整体架构图。我们首先使用javalang[8]将代码片段解析为抽象语法树。然后我们使用PACE[5](由Yu等人提出)对每个结点进行编码,接着使用编码的结点传给Linear-Model和一个最大池化层。
图4展示了详细例子(虚线表示AST中的终结结点,实线表示AST中的非终结结点)。然后我们遍历AST(抽象语法树)上的所有结点,并且根据node的ID去重。最后我们得到的node ID为“MethodDeclaration”, “copy”, “FormalParameter”, “src”, “ReferenceType”, “String”, “dest”, and “IOException”。State-of-the-art的方法使用程序的AST信息,包括词法和结构信息。Linear-Model也使用同样的词法信息,但是由于Linear-Model不对AST做处理,因此Linear-Model只使用程序的少量结构信息(比如根据ForStatement结点得知程序包含for循环结构等),详细的Linear-Model的实现在下一节介绍。
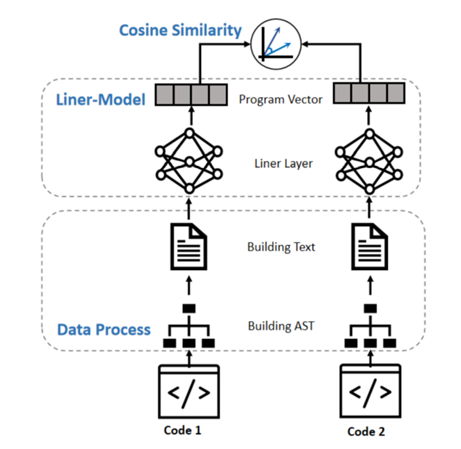
图3:Linear-Model的整体架构
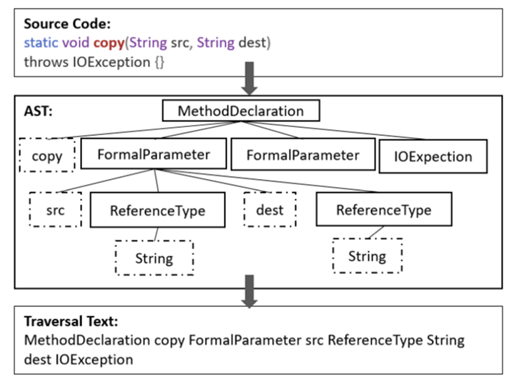
图4:一个代码片段及其对应的AST以及遍历AST得到的Node IDs集合的示例
2.线性操作和最大池化
图5展示了Linear-Model的线性操作和最大池化。Node IDs集合中有n个token,每个token的编码长度为d。Linear-Model使用一个d×m的矩阵进行线性操作,得到一个n×m的矩阵。经过线性操作后,node IDs集合中的token个数不变。然后对每一维度使用一个最大池化的操作,最终得到一个1×m的向量。
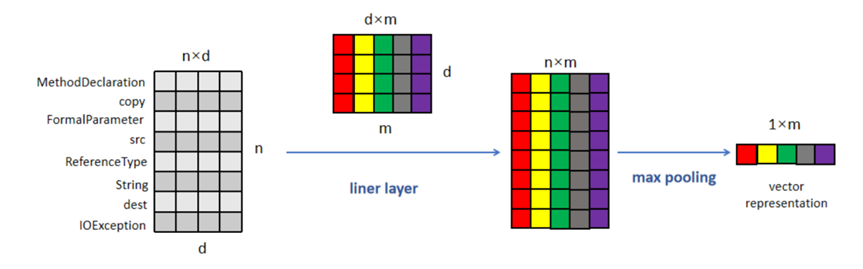
图5:线性操作
四、实验设置
我们通过实验回答如下3个Research Question:
RQ1:一个不合理的模型Linear-Model(通过只考虑哪些标识符出现在代码片段中)能够在BigCloneBench数据集中达到好的效果吗?
RQ2:State-of-the-art的方法和Linear-Model在AbsBigCloneBench数据集上的效果如何?
RQ3:State-of-the-art的方法和Linear-Model在交叉实验上的效果如何?
1. 对比方法
- ASTNN[9]。ASTNN是一个基于神经网络的程序抽象语法树的表示模型。它对抽象语法树的子树进行编码来更加充分的捕获程序抽象语法树的信息。然后它使用一个双向RNN来对每个子树的表示做处理,得到整个AST的表示。最后通过比较两个代码片段的AST表示的相似性来判断两个代码片段是否属于代码克隆。
- TBCCD[5]。TBCCD提出使用基于树的卷积神经网络检测语义代码克隆的工作。TBCCD还提出了一个基于词位置编码的方法来解决测试集中存在不在词表中的未知token的问题。
- FA[10]。FA使用基于图的卷积神经网络进行语义代码克隆检测。FA首先在程序的抽象语法树上加边,然后FA使用两个不同类型的图神经网络来判断两个代码片段的相似性。由于FA只支持Java语言的代码克隆检测,因此我们只汇报FA在BigCloneBench数据集以及AbsBigCloneBench数据集上的结果。
2. 数据集
我们使用两个公开的数据集(剩下两个数据集是基于这两个数据集变化而来):BigCloneBench[3]和OJClone[11]。这两个数据集被广泛用来验证语义代码克隆检测方法的有效性。表3展示了两个数据集的详细信息。
表3:BigCloneBench数据集和OJClone数据集的整体统计信息

- BigCloneBench
BigCloneBench数据集由Svajlenko等人提出,它是从IJaDataset中挖掘而来,并且由三个专家手动确认。IJaDataset包含25000个项目,3.65亿行代码。BigCloneBench包含10类问题以及600万克隆对和26万非克隆对。BigCloneBench将类型三的代码克隆分为弱、中、强和非常强四类。表1展示了BigCloneBench数据集中每个类型的代码克隆对占比,超过98%的代码克隆对属于语义代码克隆。我们使用OJClone来回答我们的RQ1。
- OJClone
OJClone由Mou等人提出,它最初是用来验证代码分类任务有效性的。后来CDLH、TBCCD、ASTNN以及FA使用OJClone来验证语义代码克隆检测任务有效性。学生为了解决同一问题提交的代码片段的实现往往不同,因此OJClone的代码克隆对被认为至少属于类型三的克隆。我们使用OJClone来回答我们的RQ1。
- AbsBigCloneBench
AbsBigCloneBench是从BigCloneBench数据集中抽象而来。AbsBigCloneBench抽象了BigCloneBench数据集中的部分标识符,包括类型、变量以及函数名,保留了其他token,比如操作符、基本类型以及成员变量。根据代码克隆类型的定义,抽象标识符之后的AbsBigCloneBench不会改变BigCloneBench数据集中语义代码克隆和非语义代码克隆的标记信息。我们使用AbsBigCloneBench数据集来回答我们的RQ2和RQ3.
- Over-AbsBigCloneBench
跟Mou等人和Yu等人一样,我们同样尝试研究如果只使用AST中的非终结结点,语义代码克隆检测方法在该数据集的有效性。Over-AbsBigCloneBench只使用图4中实线部分的token进行实验。我们使用Over-AbsBigCloneBench来展示state-of-the-art方法在这样一个过抽象的数据集上同样比Linear-Model有效。
3. 实验设置
对于所有数据集,我们按照8:1:1划分训练集、验证集和测试集。Linear-Model的参数如下:m为100,训练的epoch为10,优化器为SGD。
五、实验结果
RQ1:一个不合理的模型Linear-Model(通过只考虑哪些标识符出现在代码片段中)能够在BigCloneBench数据集中达到好的效果吗?
表4展示了State-of-the-art的方法和Linear-Model在BigCloneBench以及OJClone数据集的效果。从表中可以看到,Linear-Model在BigCloneBench数据集上可以达到跟state-of-the-art方法几乎一致的效果,而在OJClone数据集上的效果要明显比state-of-the-art方法差很多。在使用BigCloneBench数据集验证基于深度学习的语义代码克隆检测方法的有效性时,研究者应当注意BigCloneBench数据集中的标识符的影响。
表4:State-of-the-art的方法和Linear-Model在BigCloneBench以及OJClone的效果
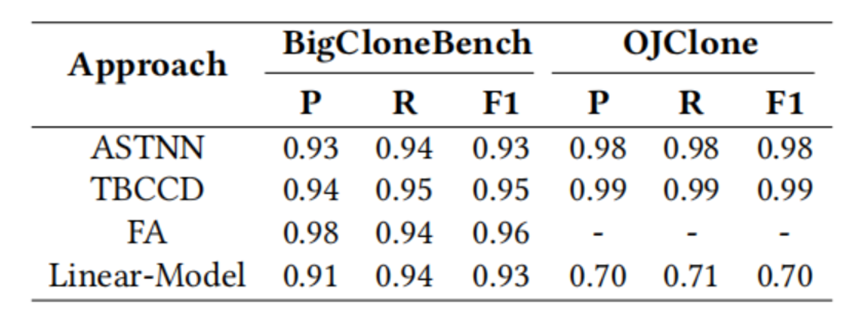
发现1:
一个不合理的模型Linear-Model在只考虑哪些标识符出现在代码片段中,能够在BigCloneBench数据集上达到很好的效果,但是它在OJClone数据集上失效。只使用BigCloneBench数据集来验证基于深度学习的语义代码克隆检测方法是有问题的,BigCloneBench数据集需要被改进。
RQ2:State-of-the-art的方法和Linear-Model在AbsBigCloneBench数据集上的效果如何?
为了减轻BigCloneBench数据集中标识符的影响,我们通过抽象BigCloneBench数据集中的一部分标识符来更好的验证基于深度学习的语义代码克隆检测方法的有效性。我们将抽象后的数据集记为AbsBigCloneBench。我们首先介绍state-of-the-art的方法和Linear-Model在Over-AbsBigCloneBench数据集(只保留程序AST中的非终结结点)上的效果,接着介绍怎样修改BigCloneBench来得到AbsBigCloneBench,最后讨论为什么AbsBigCloneBench比BigCloneBench在验证基于深度学习的语义代码克隆检测方法有效性时更合理。
1. State-of-the-art的方法和Linear-Model在Over-AbsBigCloneBench数据集的效果
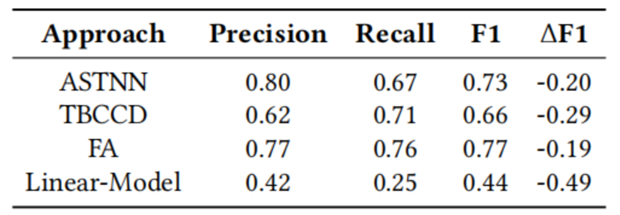
跟Mou等人和Yu等人一样,为了进一步研究代码token对代码克隆检测的影响,我们在Over-AbsBigCloneBench数据集上测试了state-of-the-art的方法和Linear-Model的效果。表5展示了state-of-the-art的方法和Linear-Model在Over-AbsBigCloneBench数据集的效果。当程序AST中的终结结点(即代码token)被移除后,state-of-the-art的方法明显比Linear-Model的方法有效,因为state-of-the-art的方法在学习程序结构信息方面比Linear-Model更有效。但是移除所有的代码token是不合理的,这样会损失大量的程序语义信息。这也是state-of-the-art的方法在Over-AbsBigCloneBench数据集上的效果相比BigCloneBench差很多的原因。
表5:state-of-the-art的方法和Linear-Model在Over-AbsBigCloneBench数据集的效果
2. 怎样修改BigCloneBench来得到AbsBigCloneBench
考虑到保留代码语义信息不变,抽象所有的代码token是不合理的。我们只抽象BigCloneBench数据集中的部分标识符,包括类型、变量以及函数名,保留了其他token,比如操作符、基本类型以及成员变量。图6展示了一个BigCloneBench数据集中的代码片段以及其抽象后的示例。

图6:BigCloneBench数据集中的一个代码片段以及其抽象后的示例
AbsBigCloneBench数据集不同问题之间的标识符的Jaccard相似系数为0.484,对比BigCloneBench数据集的0.038,表明AbsBigCloneBench比BigCloneBench数据集更少的依赖于标识符。
3. State-of-the-art的方法和Linear-Model在AbsBigCloneBench数据集的效果
跟RQ1类似,我们比较了state-of-the-art的方法和Linear-Model在AbsBigCloneBench数据集的效果。实验结果如表6所示,∆F1指标指相对表4的F1值结果的提升或降低。
表6:State-of-the-art的方法和Linear-Model在AbsBigCloneBench数据集的效果
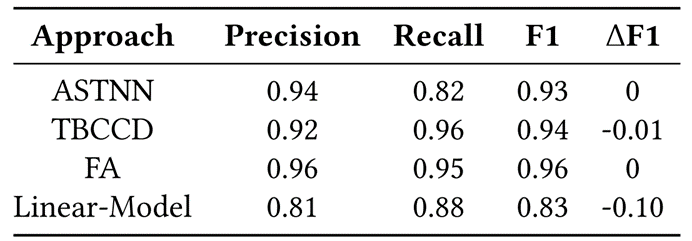
从表6可以看到,state-of-the-art的方法在AbsBigCloneBench数据集上的F1值明显比Linear-Model高。同时state-of-the-art的方法在AbsBigCloneBench数据集上的F1相比BigCloneBench几乎没有变化,而Linear-Model却有一个明显的下降。分析原因我们认为在抽象了部分标识符后,Linear-Model只通过考虑哪些标识符出现来进行语义代码克隆检测是无效的。图7进一步展示了state-of-the-art的方法和Linear-Model在BigCloneBench以及AbsBigCloneBench数据集的PR曲线以及AUC值,PR曲线和AUC值同样能说明AbsBigCloneBench数据集在检测基于深度学习的语义代码克隆检测方法的有效性时更合理。
发现2:合理的抽象BigCloneBench数据集中的标识符能够帮助其更好的分别state-of-the-art的方法和不合理的基于深度学习的代码克隆检测方法。抽象BigCloneBench数据集中的标识符名字能更帮助其更好的评估基于深度学习的代码克隆检测方法的有效性。
RQ3:State-of-the-art的方法和Linear-Model在交叉实验上的效果如何?
本节我们通过交叉实验来研究模型在BigCloneBench(AbsBigCloneBench)数据集上训练,在AbsBigCloneBench(BigCloneBench)数据集上测试的效果,并且提出三个评估技术来检查用来验证基于深度学习的代码克隆检测方法的数据集是否合理。
1. State-of-the-art的方法和Linear-Model在BigCloneBench数据集训练,在AbsBigCloneBench数据集测试
表7的上半部分展示了state-of-the-art的方法和Linear-Model在BigCloneBench数据集训练,在AbsBigCloneBench测试的效果相比在BigCloneBench测试的效果有一个明显的下降,它表明在BigCloneBench数据集上训练的模型,在其他只是标识符不同的数据集上测试将会失效,而根据代码克隆的定义,标识符不同不应该影响代码语义克隆检测模型的效果。分析原因我们认为模型在BigCloneBench数据集上训练时,能够通过标识符信息快速达到收敛,模型不会继续深入学习程序的结构信息。因此一旦测试集中的标识符跟训练集不相似,模型的效果就会有一个明显的下降。
表7:State-of-the-art的方法和Linear-Model在交叉实验上的效果
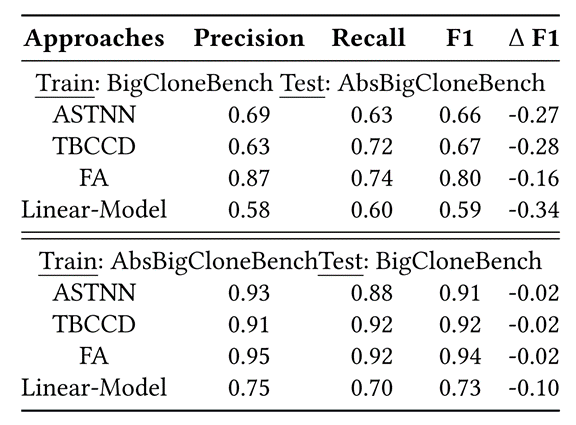
发现3:
在BigCloneBench数据集上训练的模型在AbsBigCloneBench数据集测试无效
2. State-of-the-art的方法和Linear-Model在AbsBigCloneBench数据集训练,在BigCloneBench数据集测试
表7的下半部分展示了state-of-the-art的方法和Linear-Model在AbsBigCloneBench数据集训练,在BigCloneBench测试的效果相比在AbsBigCloneBench测试的效果几乎没有变化,它表明在BigCloneBench数据集上训练的模型,在其他只是标识符不同的数据集上测试依然有效。分析原因我们认为模型在AbsBigCloneBench数据集上训练时,不能够通过标识符信息快速达到收敛,模型会继续深入学习程序的结构信息。因此即使测试集中的标识符跟训练集不相似,模型的效果依然会有效。
发现4:
在AbsBigCloneBench数据集上训练的模型在BigCloneBench数据集测试依然有效。AbsBigCloneBench提供了更全面的方法有效性视图,与在BigCloneBench数据集训练的模型相比,在AbsBigCloneBench数据集训练的模型对标识符名称的依赖程度更低。
3. 三个检查用来验证基于深度学习的代码克隆检测方法的数据集是否合理的评估技术
- 不同方法在抽象前数据集和抽象后数据集的有效性排序应该一致
- 同一个方法,在抽象前数据集训练,在抽象后数据集测试的效果应该一致
- 不合理的方法在抽象后的数据集应该无效
六、总结
我们首先发现BigCloneBench数据集的语义代码克隆对使用相似的标识符,而非语义代码克隆对的标识符不相似。接着文章提出了一个不合理的模型(Linear-Model),通过只考虑那些标识符在代码克隆片段中出现来检测代码语义代码克隆。这个不合理的模型可以达到跟其他被验证有效的方法一样的效果。为了减轻这个问题,我们通过抽象BigCloneBench数据集中的一部分标识符(类型名、变量名以及方法名)得到AbsBigCloneBench数据集。实验结果表明AbsBigCloneBench数据集能够更好的验证语义代码克隆检测方法的有效性。并且使用AbsBigCloneBench数据集训练的模型在BigCloneBench数据集测试依然有效,而使用BigCloneBench数据集训练的模型在AbsBigCloneBench数据集测试却无效。
文章来自北京大学、华为云PaaS技术创新Lab;PaaS技术创新Lab隶属于华为云(华为内部当前发展最为迅猛的部门之一,目前国内公有云市场份额第二,全球第五),致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!(招聘接口人:guodongshuo@huawei.com; huwei18@huawei.com;)
PaaS技术创新Lab主页链接:https://www.huaweicloud.cn/lab/paas/home.html
参考文献
- Chanchal Kumar Roy and James R Cordy. A Survey on Software Clone Detection Research. Queen’s School of Computing TR 541, 115 (2007), 64–68.
- Stefan Bellon, Rainer Koschke, Giulio Antoniol, Jens Krinke, and Ettore Merlo. Comparison and Evaluation of Clone Detection Tools. IEEE Transactions on Software Engineering 33, 9 (2007), 577–591.
- Jeffrey Svajlenko, Judith F. Islam, Iman Keivanloo, Chanchal K. Roy, and Mohammad Mamun Mia. Towards a Big Data Curated Benchmark of Inter-Project Code Clones. In Proceedings of the 30th International Conference on Software Maintenance and Evolution (ICSME), 2017, 476–480.
- Hui-Hui Wei and Ming Li. Positive and Unlabeled Learning for Detecting Software Functional Clones with Adversarial Training. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), 2018, 2840–2846.
- Hao Yu, Wing Lam, Long Chen, Ge Li, Tao Xie, and Qianxiang Wang. Neural Detection of Semantic Code Clones Via Tree-Based Convolution. In Proceedings of the 27th IEEE International Conference on Program Comprehension (ICPC), 2019, 70–80.
- Hao Yu, Xing Hu, Ge Li, Ying Li, Qianxiang Wang, Tao Xie. Assessing and Improving an Evaluation Dataset for Detecting Semantic Code Clones via Deep Learning. TOSEM, 2022, Accepted.
- IJaDataset2.0. January 2013. Ambient Software Evoluton Group. http://secold.org/projects/seclone.
- https://github.com/c2nes/javalang.
- Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, Kaixuan Wang, and Xudong Liu. A Novel Neural Source Code Representation Based on Abstract Syntax Tree. In Proceedings of the 41st IEEE/ACM International Conference on Software Engineering (ICSE), 2019, 783–794.
- Wenhan Wang, Ge Li, Bo Ma, Xin Xia, and Zhi Jin. Detecting Code Clones with Graph Neural Network and Flow-Augmented Abstract Syntax Tree. In Proceedings of the 27th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), 2020, 261–271.
- Lili Mou, Ge Li, Lu Zhang, Tao Wang, and Zhi Jin. Convolutional Neural Networks over Tree Structures for Programming Language Processing. In Proceedings of the 30th AAAI Conference on Artificial Intelligence (AAAI), 2016, 1287–1293.

- 点赞
- 收藏
- 关注作者
评论(0)