【云驻共创】详解Kubernetes工作负载管理

声明:本篇文章部分资料来自《华为云云原生王者之路训练营》黄金课程集训营第5课,由华为云技术专家Jessia
Ding主讲,帮你了解工作负载的概念以及Kubernetes提供的内置工作负载的信息;Deployment/ DaemonSet/ Job/
CronJob概念以及使用场景。
希望读者通过接下来代码加图文的介绍对工作负载的概念以及使用场景有更清晰的认识和帮助。
通过本文能学会什么?
1.了解工作负载的概念以及Kubernetes 提供的内置工作负载的信息。
2.deployment概念及使用场景
3.daemonset概念及使用场景
4.job/cronjob概念及使用场景
工作负载是在 Kubernetes 上运行的应用程序。无论你的负载是单一组件还是由多个一同工作的组件构成,在 Kubernetes 中你 可以在一组 Pods 中运行它。 在 Kubernetes 中,Pod 代表的是集群上处于运行状态的一组容器。Pod 有确定的生命周期,如果该Pod所在的节点出现了致命的错误时,所有该节点的Pod都会失败。Kubernetes提供一些负载资源来替你管理一组Pod,让用户没有必要管理每个Pod。
本篇文章呢将分为三个点来向大家介绍:
1.Deployment
2.Job/CronJob
3.DaemonSet
一、Deployment
1.1 Deployment概念:
Deployment是一组不具有唯一标识的多个Pod的集合:
-
确保集群中有期望数量的Pod运行
-
提供多种升级策略以及一键回滚能力。
-
提供暂停/恢复的能力
典型使用场景:
- Web Server等无状态应用
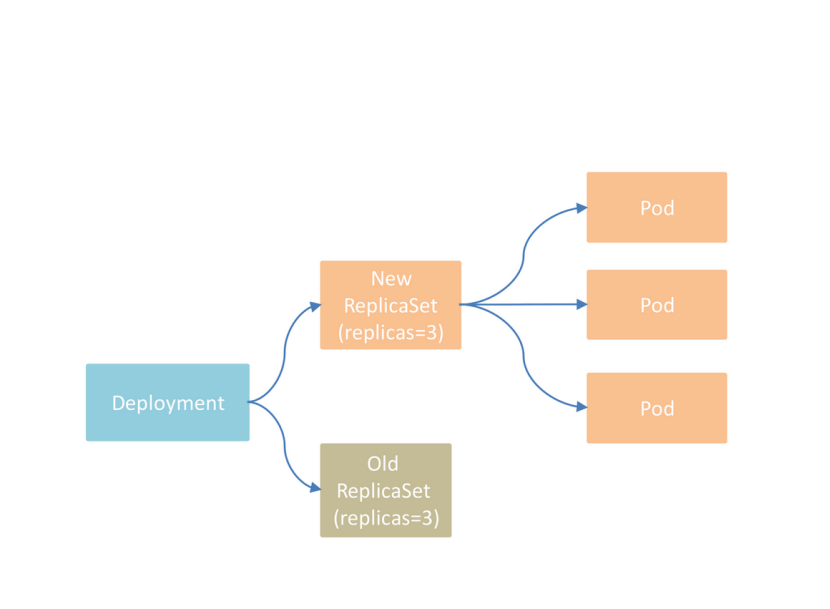
1.2Deployment 语法
Deployment 升级策略:
RollingUpdate: 滚动升级策略中我们可以配置以下两个参数:
- maxUnavailable 表示在更新过程中能够进入不可用状态的 Pod 的最大值;
- maxSurge 表示能够额外创建的 Pod 个数
滚动更新的过程中是启动一个新的ReplicaSet,创建一部分新Pod,并缩减历史的ReplicaSet的数量,一直循环往复,以达到期望状态,步长由以上两个参数控制。
Recreate: 先将老的ReplicaSet期望实例数改成0,等所有Pod终止以后,再创建新的ReplicaSet
RevisonHistoryLimit: 指定保留的历史ReplicaSet数量。
Pause: 当Deployment暂停后,Deployment发生了改动,也不会被Controller同步,触发更新。

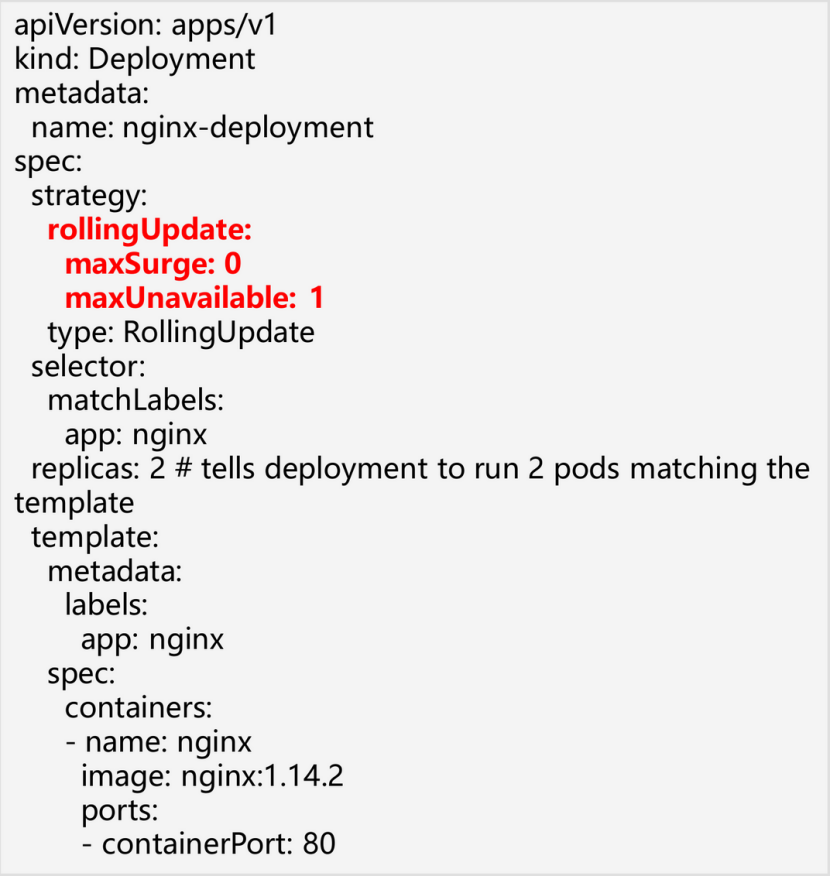
1.3Deployment 常用操作

1.4 Deploymen使用小结
1.选择所需的升级策略,合理配置升级参数,例如maxUnavailable以及maxSurge
2.合理设置历史版本数量,系统默认情况下会保留10个历史版本。
3.回滚时,只有Deployment 模板部分会被回滚,手动/自动扩缩Deployment数量是不会被回滚的。
4.暂停过程中,模板更新不会触发Deployment滚动更新。
二、Job/CronJob
2.1 Job 概念:
主要处理一些短暂的一次性任务:
- 保证指定数量Pod成功运行结束
- 支持并发执行
- 支持错误自动重试
- 支持暂停/恢复Job
典型使用场景: - 计算以及训练任务, 如批量计算,AI训练任务等
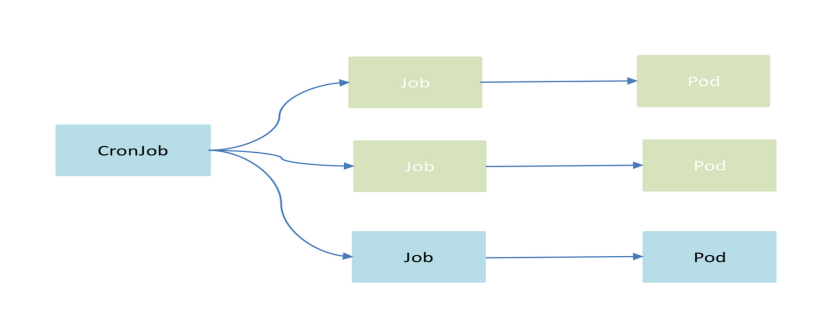
CronJob 主要处理周期性或者重复性的任务:
- 基于Crontab格式的时间调度
- 可以暂停/恢复CronJob
典型的使用场景: - 周期性的数据分析服务
- 周期性的资源回收服务
2.2 Job/CronJob 语法
Job关键字段:
- Parallelism: 在同一时间运行的最大的Pod的数量
- Completions: 指定Job成功需要运行成功的Pod的数量
- BackoffLimit: 重试次数,当超过该重试次数时,该Job标记为Failed
- CompletionMode: 1.21引入,如果设置为Indexed,创建的Pod annotation会带上batch.kubernetes.io/job-completion-index,index值为0~spec.completions-1,并且仅当每个index的pod都有一个成功的时候,这时Job才会被认为是成功的。
- controller会给pod中注入JOB_COMPLETION_INDEX的环境变量
- Suspend: 1.21引入,等于true时,用户暂停了Job,controller会删除所有正在运行的Pod。
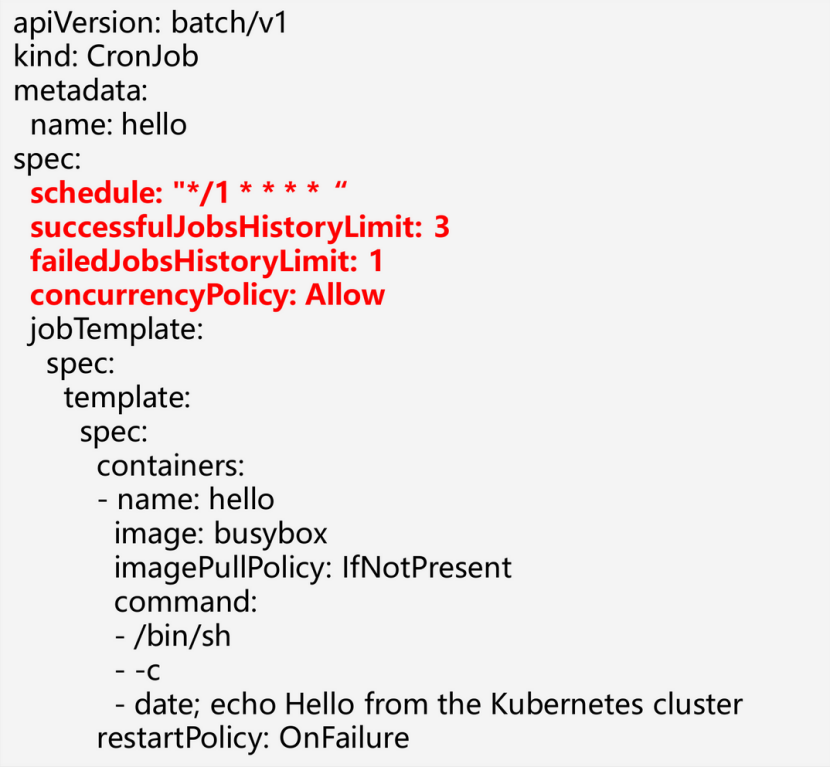
2.3 CronJob关键字段:
-
Schedule: 设置Job的周期策略
-
ConcurrencyPolicy: 指定 CronJob 创建的任务执行时发生重叠如何处理, Allow是允许并发执行任务, Forbid是不允许并发执行,Replace是会用新任务替换正在运行的任务。
-
startingDeadlineSeconds: 表示统计错过调度次数开始的时间,默认从上一次调度时间开始统计。
-
successfulJobsHistoryLimit,failedJobsHistoryLimit: 可以指定保留的成功和失败的任务个数。
-
Suspend: 是否暂停
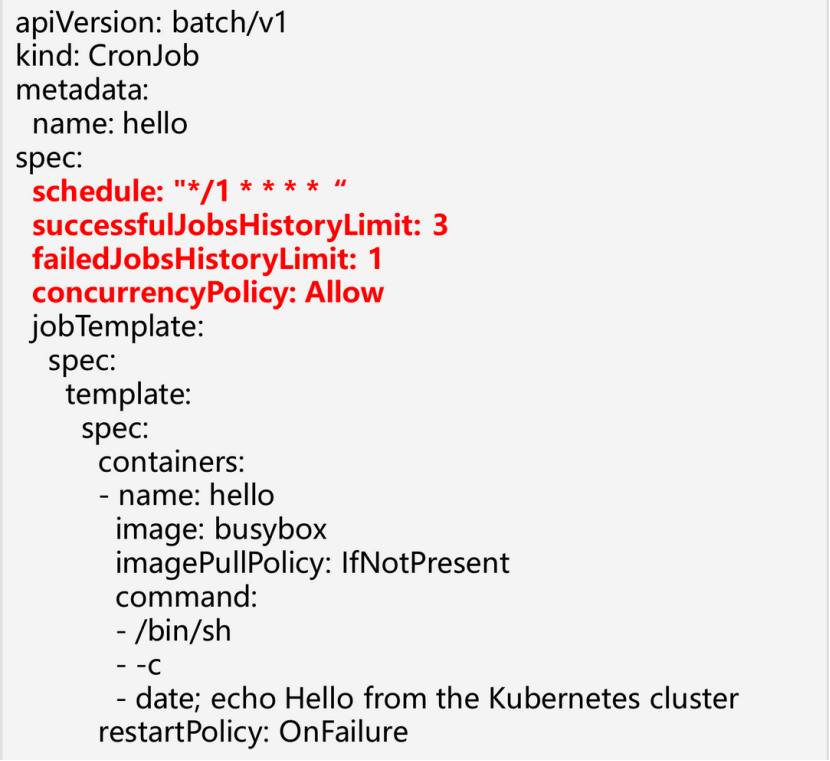
2.4 Job/CronJob 常用操作
-
创建Job
-
查询Job

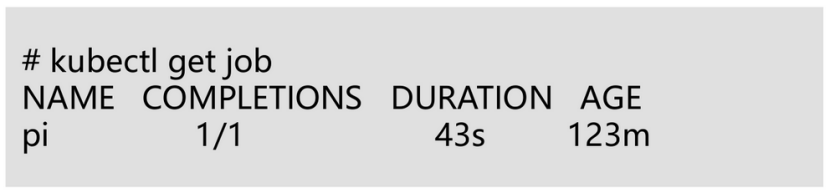
COMPLETIONS: 显示已经完成的Pod数量,显示的字段为.status.succeeded
DURATION: Job实际也运行时长,已完成Job使用status.completionTime – status.startTime
创建CronJob

查询CronJob

SUSPEND : 显示已经该Cronjob是否暂停
ACTIVE : 显示的是正在执行的Job的数量
LAST SCHEDULE: 显示的是上一次触发任务执行的时间
2.5 Job/CronJob 使用小结
· 合理设置Job 的并发度,和所需的完成数量
· 合理设置失败重试次数,当前系统默认值为6
· Job 中的Pod Restart Policy 只能为Never 或者 OnFailure
· 合理设置历史Job保留时间
· 合理设置CronJob的周期策略,以及并发策略
· CronJob 当在一个时间窗内(上一次调度的时间点到现在)所错过的调度次数超过100次以后,那么就不会再启动这个任务了
三、DaemonSet
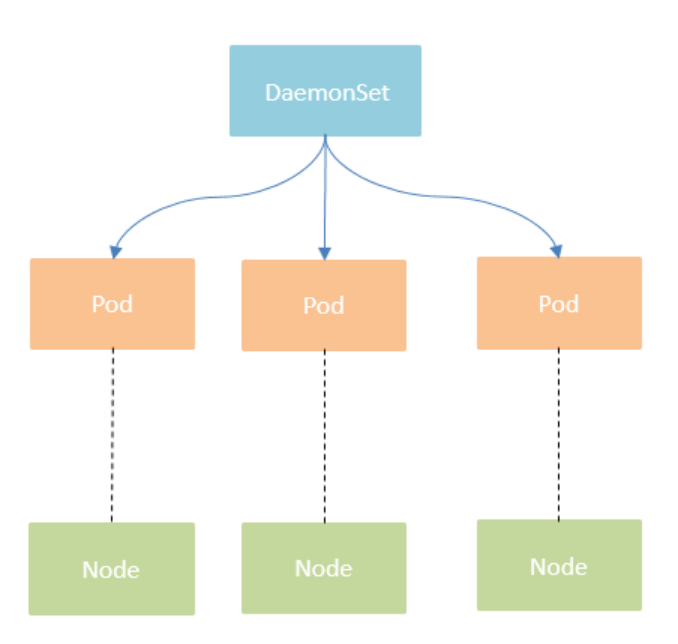
3.1 DaemonSet(守护进程集)功能:
- 确保每一个节点或者期望的节点上运行一个Pod
- 新增节点时自动部署一个Pod
- 移除节点时自动删除Pod
典型使用场景: - 日志监控采集进程,如fluentd, icagent,
- 节点运维进程,等Node Problem Detector, OS-Operator-Agent
- Kubernetes 必要运行组件,如Everest Driver, Calico等
- Device Plugin:
- GPU Device Plugin,运行在GPU节点上
DaemonSet 语法
DaemonSet 升级策略:
RollingUpdate:更新了DaemonSet的配置时,会自动删除老的Pod,删除完成后,创建新的Pods,并发滚动更新的节点数可以通过maxUnavailable控制.
OnDelete: 更新了DaemonSet的配置,不会自动删除并重建Pod; 通过删除Pod,触发Pod的更新。
DaemonSet Template中RestartPolicy必须为Always
RevisionHistoryLimit: 指定保留的历史revision数量。
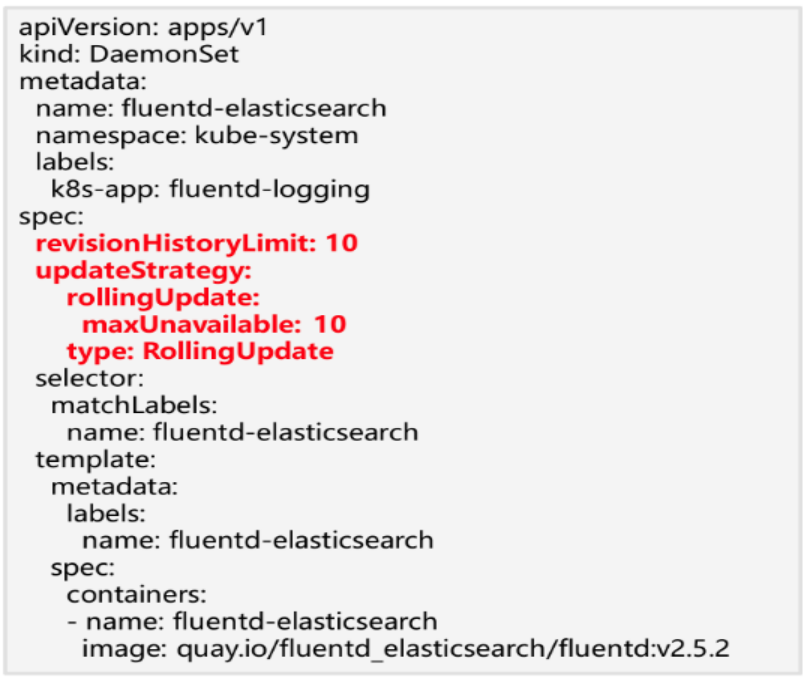
3.2 DaemonSet 常用操作

DESIRED: 对应status.desiredNumberScheduled,表示集群中需要部署ds pod的节点数量
CURRENT:对应status.currentNumberScheduled, 表示集群中已经有调度ds pod的节点数量
READY:对应status.NumberReady, 表示集群中已经有Running ds pod的节点数量
UP-TO-DATE:对应status.updatedNumberScheduled, 表示集群中已经启动最新的ds版本pod的节点数量
AVAILABLE: 对应status.numberAvailable, 表示集群中有running ds pod,并且在minReadySeconds容器没有重启的节点数量

3.3 DaemonSet使用小结
- 合理设置DaemonSet升级策略
- 可以通过设置节点亲和性或者节点选择器来选择部分节点部署。
- 合理设置DaemonSet的RevisionHistoryLimit,默认值为10
本文整理自华为云社区【内容共创】活动第12期。
查看活动详情:https://bbs.huaweicloud.cn/blogs/325315
相关任务详情:元宇宙漫游指南-新一代GIS技术构建元宇宙

- 点赞
- 收藏
- 关注作者
评论(0)