【云驻共创】华为云云原生黄金课程03:Kubernetes 系统快速入门

前言
为进一步推进云原生技术的普及,帮助广大技术爱好者快速掌握云原生相关技能,华为云云原生团队重磅推出《云原生王者之路系列课程》。课程分为黄金、钻石和王者三阶段,从云原生基础知识介绍到最佳实践讲解、底层原理和方案架构深度剖析,层层深入,可满足不同云原生技术基础和学习目标人群的需求。本课程还将理论与实践相结合,精选数十个企业典型应用场景,作为学员上机实践案例,帮助学员将所学技术快速与企业业务相结合,服务于企业生产。
学完本课程后,您将能够:了解Kubernetes的基本概念;了解Kubernetes的总体架构;了解Kubernetes的基本API对象,有助于从全局了解Kubernetes中的设计模式,和相关基础概念,为后期系统性的认识kubernetes打下坚实的基础。
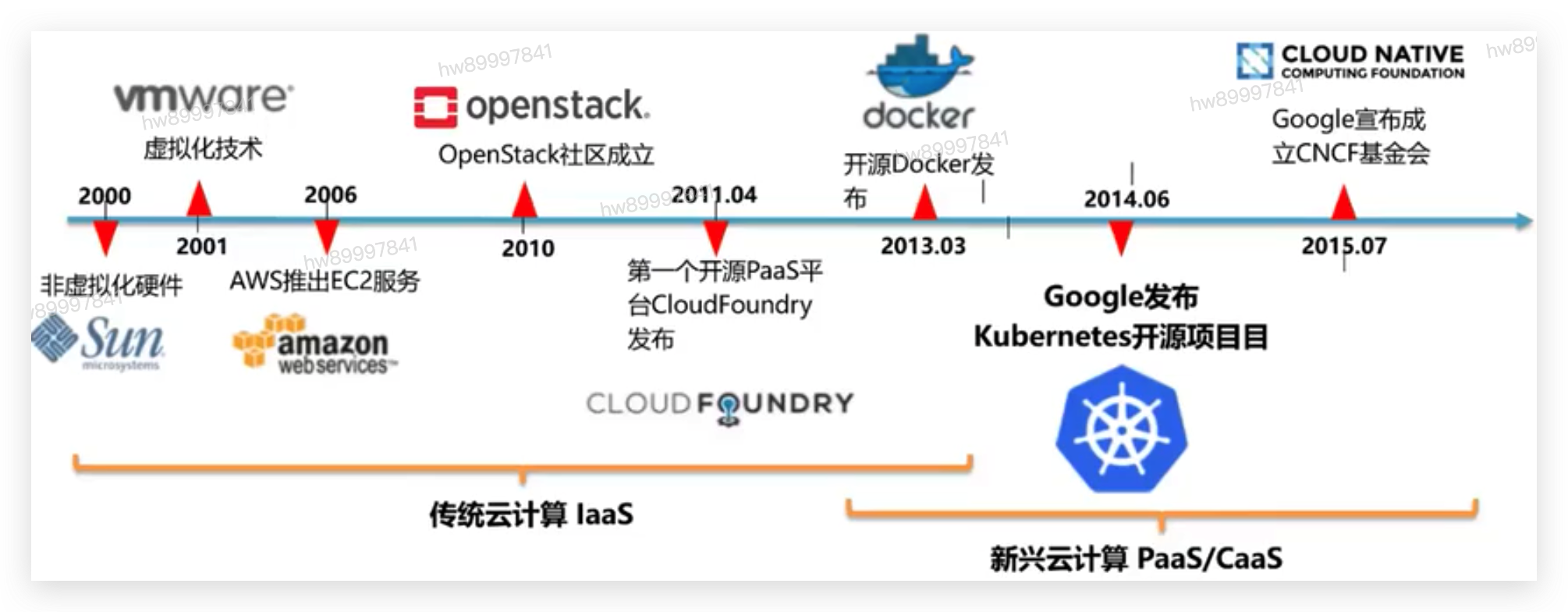
一 云计算发展历程
"云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。这种特性经常被称为像水电一样使用IT基础设施。
2004 年— 2007 年,Google 已在内部大规模地使用像 Cgroups 这样的容器技术;
• 2008 年,Google 将 Cgroups 合并进入了 Linux 内核主干;
• 2013 年,Docker 项目正式发布。
• 2014 年,Kubernetes 项目也正式发布。这样的原因也非常容易理解,因为有了容器和 Docker 之后,就需要有一种方式去帮助大家方便、快速、优雅地管理这些容器,这就是 Kubernetes 项目的初衷。在 Google 和 Redhat 发布了 Kubernetes 之后,这个项目的发展速度非常之快。
• 2015 年,由Google、Redhat 以及微软等大型云计算厂商以及一些开源公司共同牵头成立了 CNCF 云原生基金会。CNCF 成立之初,就有 22 个创始会员,而且 Kubernetes 也成为了 CNCF 托管的第一个开源项目。在这之后,CNCF 的发展速度非常迅猛;
• 2017 年,CNCF 达到 170 个成员和 14 个基金项目;
• 2018 年,CNCF 成立三周年有了 195 个成员,19 个基金会项目和 11 个孵化项目,如此之快的发展速度在整个云计算领域都是非常罕见的。
二 Kubernetes架构分层
kubernetes 是希腊语,翻译过来是:舵手的意思,它的原型是谷歌内部使用 Borg 集群管理系统,可以说是集结了 Borg 设计思想的精华,并且吸收了 Borg 系统中的经验和教训。
它的目标不仅仅是一个编排系统,而是提供一个规范,可以让你来描述集群的架构,定义服务的最终状态,Kubernetes可以帮你将系统自动地达到和维持在这个状态。Kubernetes作为云原生应用的基石,相当于一个云操作系统,其重要性不言而喻。
kubernetes 在 2014 年发布了第一个版本,目前开源并托管在 Github 上。
Kubernetes五层的架构主要分为五层,分别是生态层,接口层,治理层,和内核层。
其中针对内核层:
1、内核层:提供最核心的特性最小集以及API,为必选模块
2、内核层之上:以各种Controller插件方式实现内核层API,支持可替换的实现
3、内核层之下:是各种适配存储、网络、容器、Cloud Provider等
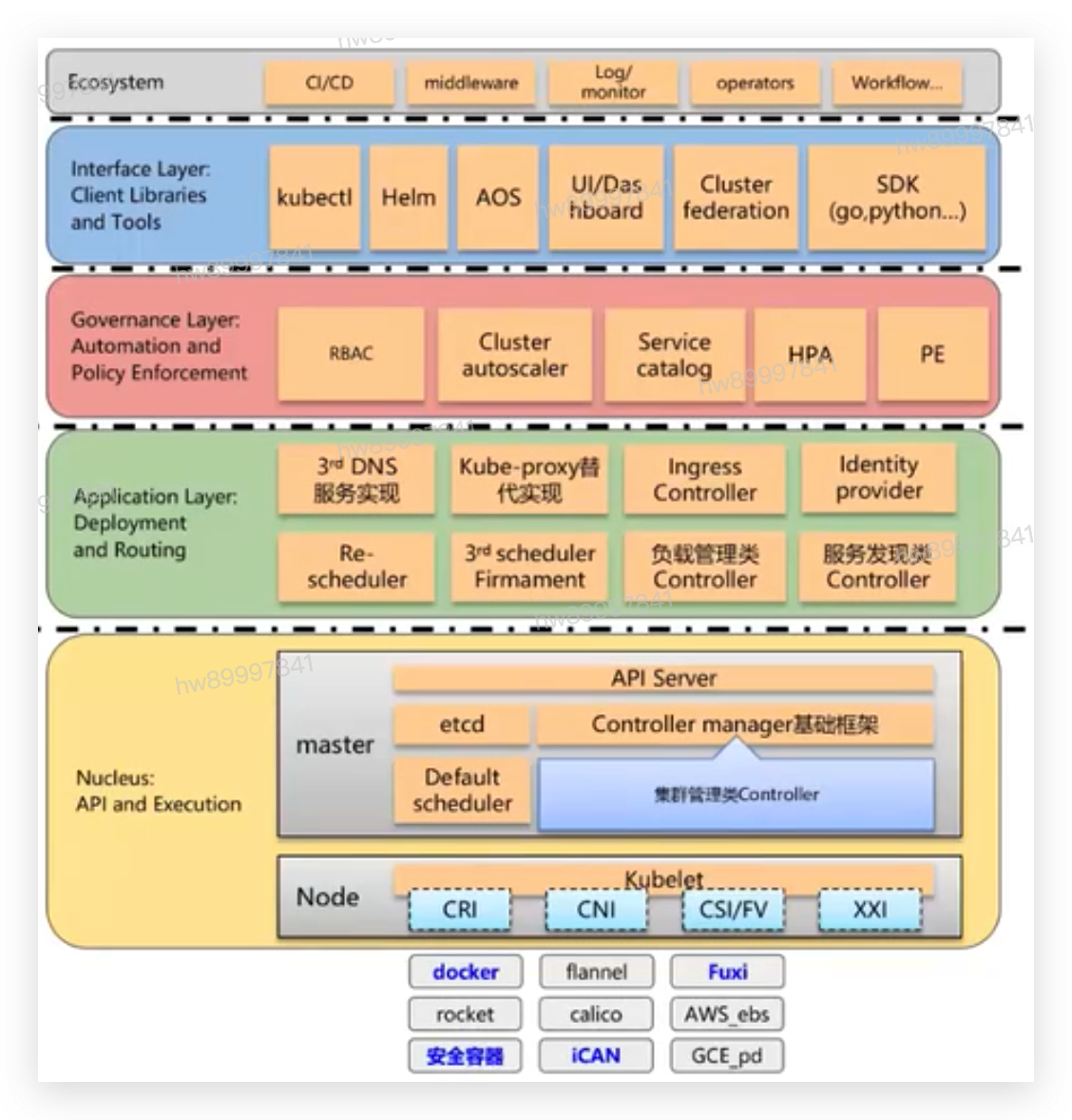
2.1 生态层:
不属于K8s范围,生态系统,保护日志,监控,存储网络,等一系列生态。
2.2 接口层:
• K8s官方项目提供的库,工具,UI等。
• 外部可使用自由实现,例如helm charts等。
2.3 治理层:
策略执行也自动编排
• 对应用运行的可选层,没有这层功能不影响应用的执行。
• 自动化API:水平弹性伸缩、租户管理、集群管理、动态LB等。
• 策略API:限速、资源配额、pod可靠性策略、network policy等。
2.4 应用层:
• K8S发行版必备功能和API, K8S会提供默认的实现,如Scheduler。
• Controller和scheduler可以被替换为各自的实现,但必须通过-致性测试。
• 业务管理类Controller: daemonset/replicaset/replication/statefulset/cronjob/service/endpoint
2.5 内核层:
包括容器运行时,网络差距,存储差距,镜像仓库,云Provoder,身份认证等。
• 由主流K8S codebase実現(主項目),属于K8S的内核、最小特性集.等同于Linux Kernel。
• 提供必不可少的Controller. Scheduler。
• 集群管理类。Controller: Node/gc/podgc/volume/namespace/resourcequota/serviceaccount
三 Kubernetes概览

四 Kubernetes关键概念
4.1 Pod
在 Kubernetes 上调度的原子单元,Kubernetes 不直接调度容器,而是 Pod,Pod可以理解为容器的二次封装,可以由一个或者多个容器组成,多个容器共享同一个网络名称空间:NET、UTS、IPC。
同一个 POD 里的容器,还能共享同一个存储卷,存储卷可以属于 POD。
一般一个 POD 只运行一个容器,如果需要在POD放多个容器,那么一般有一个主容器,其他容器是为主容器提供服务的。
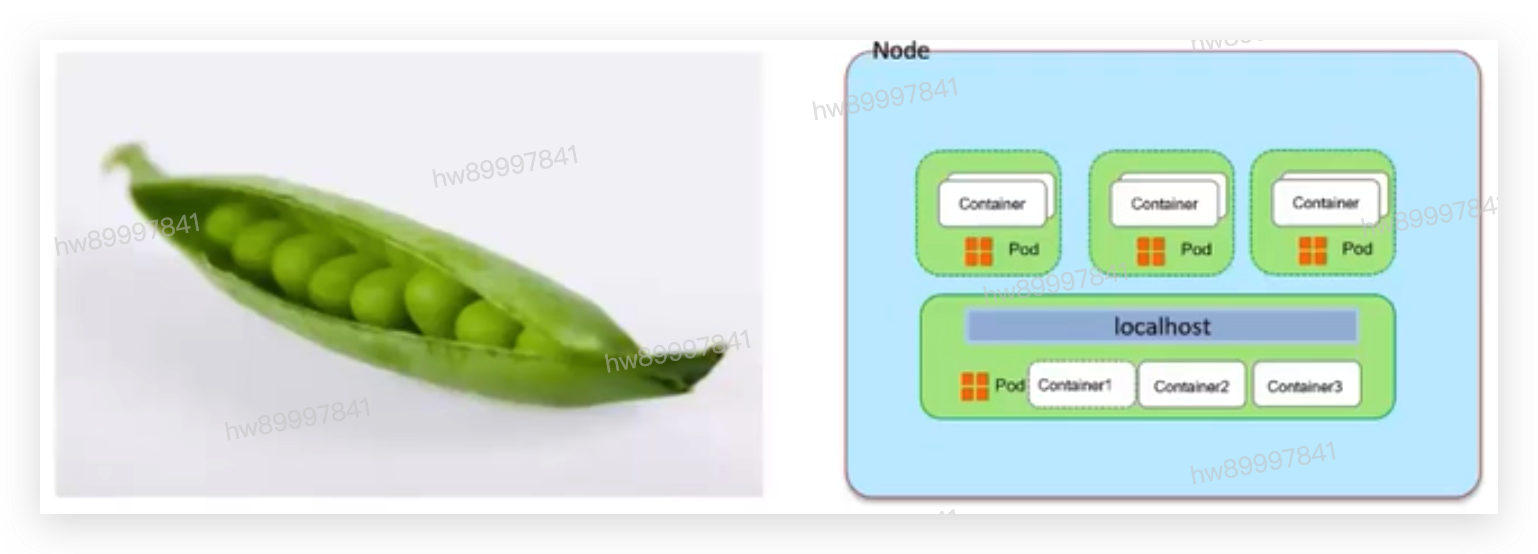
• 在Kubernetes中,pods是能够创建、调度、和管理的最小部署单元,是- -组容器的集合,而 不是单独的应用容器
• 同一个Pod里的容器共享同一个网络命名空间,IP地址及端口空间。
• 从生命周期来说,Pod是短暂的而不是长久的应用。Pods被调度到节点,保持在这个节点上
直到被销毁。
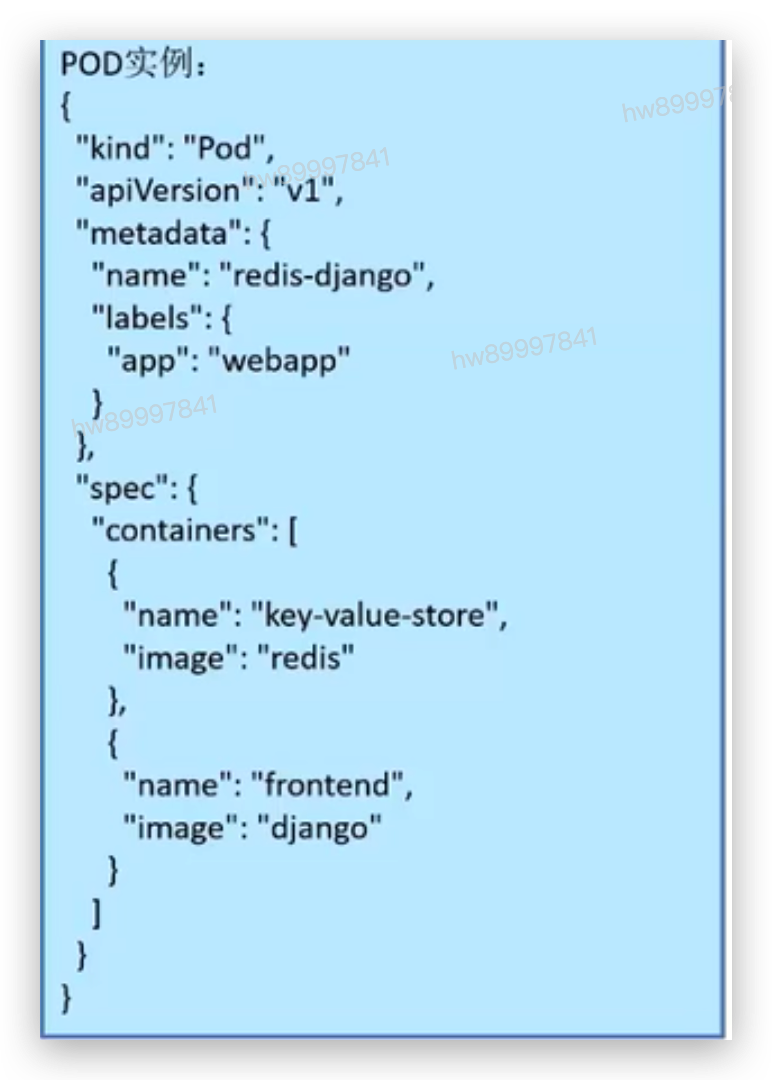
4.1.1 POD详解
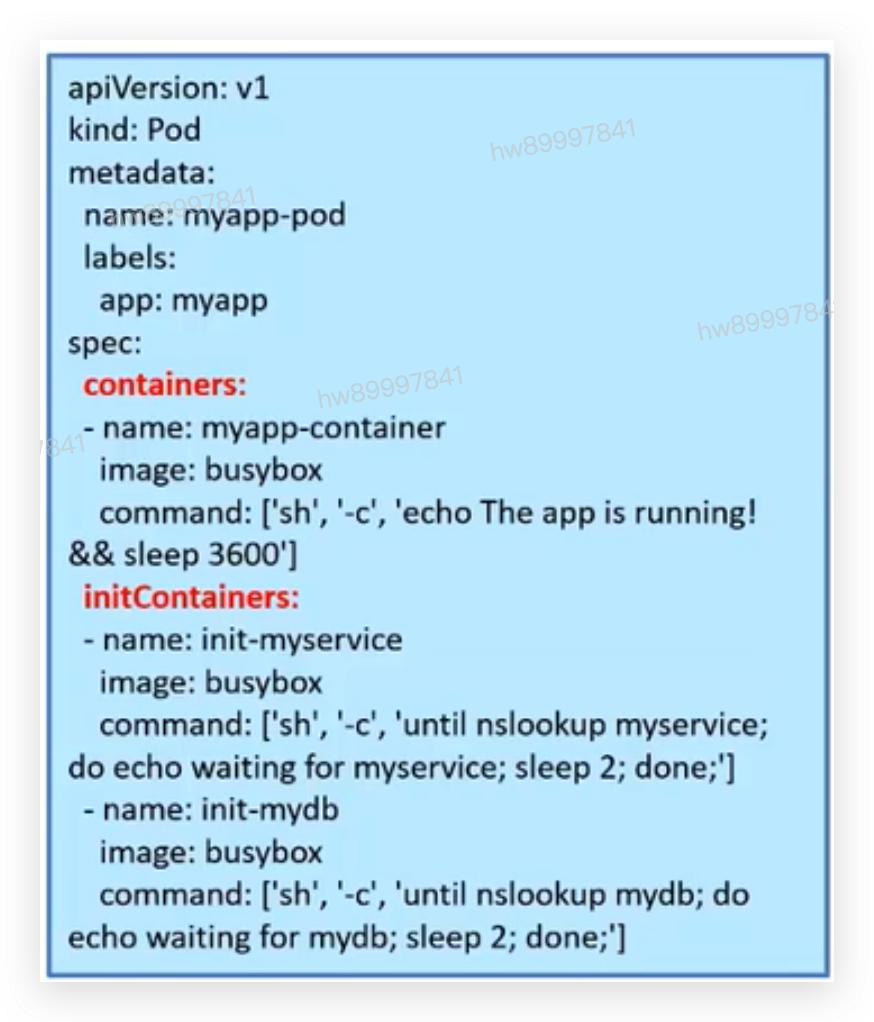
• Infrastructure Container:基础容器
• 用户不可见,无需感知
• 维护整个Pod网络空间
• InitContainers:初始化容器,-般用于服务等待处理以及注册Pod信息等
• 先于业务容器开始执行
• 顺序执行,执行成功退出(exit 0),全部执行成功后开始启动业务容器
• Containers:业务容器
• 并行启动,启动成功后- -直Running
4.1.2 容器基本组成
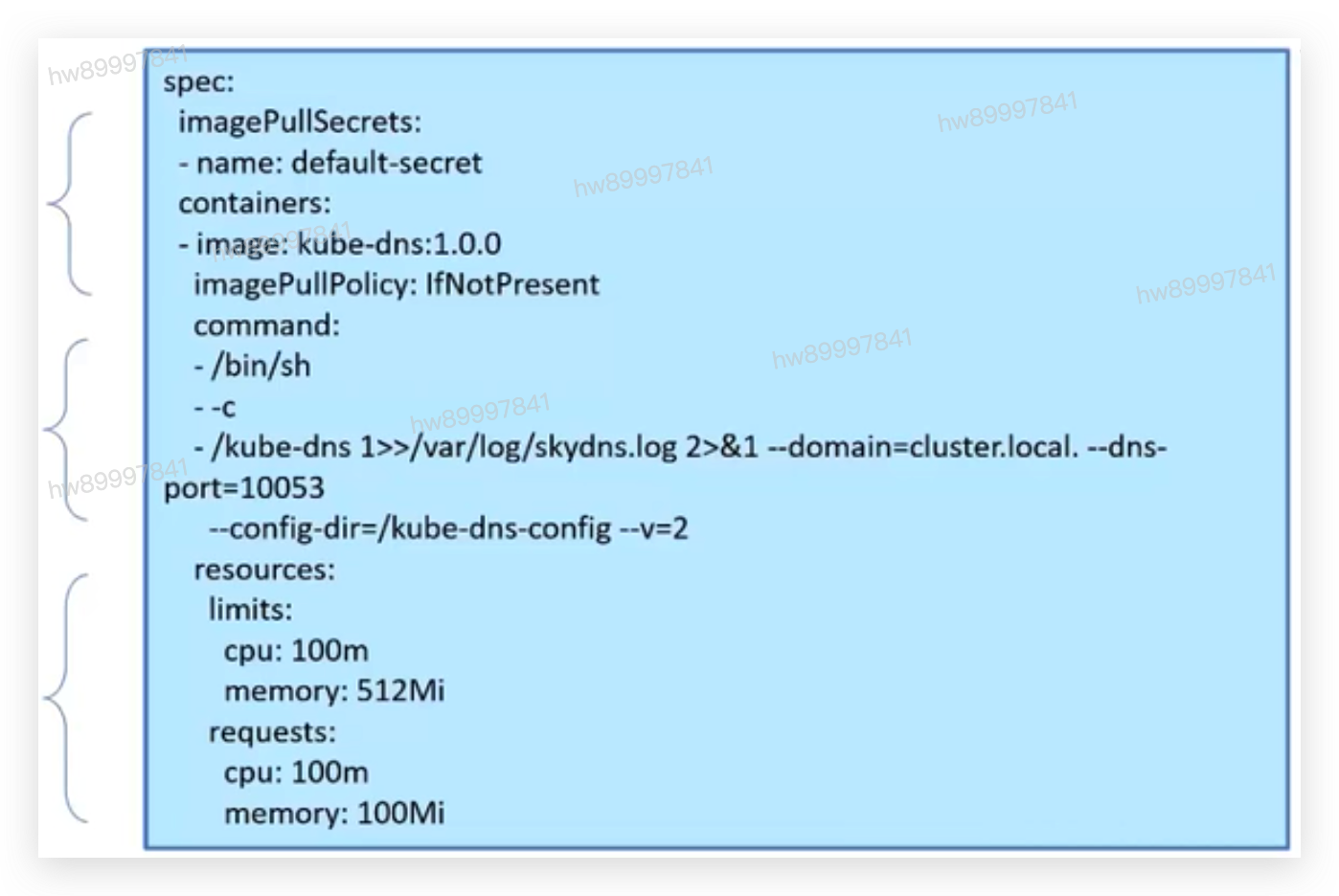
• 镜像部分:
• 镜像地址和拉取策略
• 拉取镜像的认证凭据
• 启动命令:
• commandg9替换docker容器的entrypoint
• args:作为docker容器entrypoint的=入参
• 计算资源:
• 请求值:调度依据
• 限制值:容器最大能使用的规格
4.1.3 外部输入
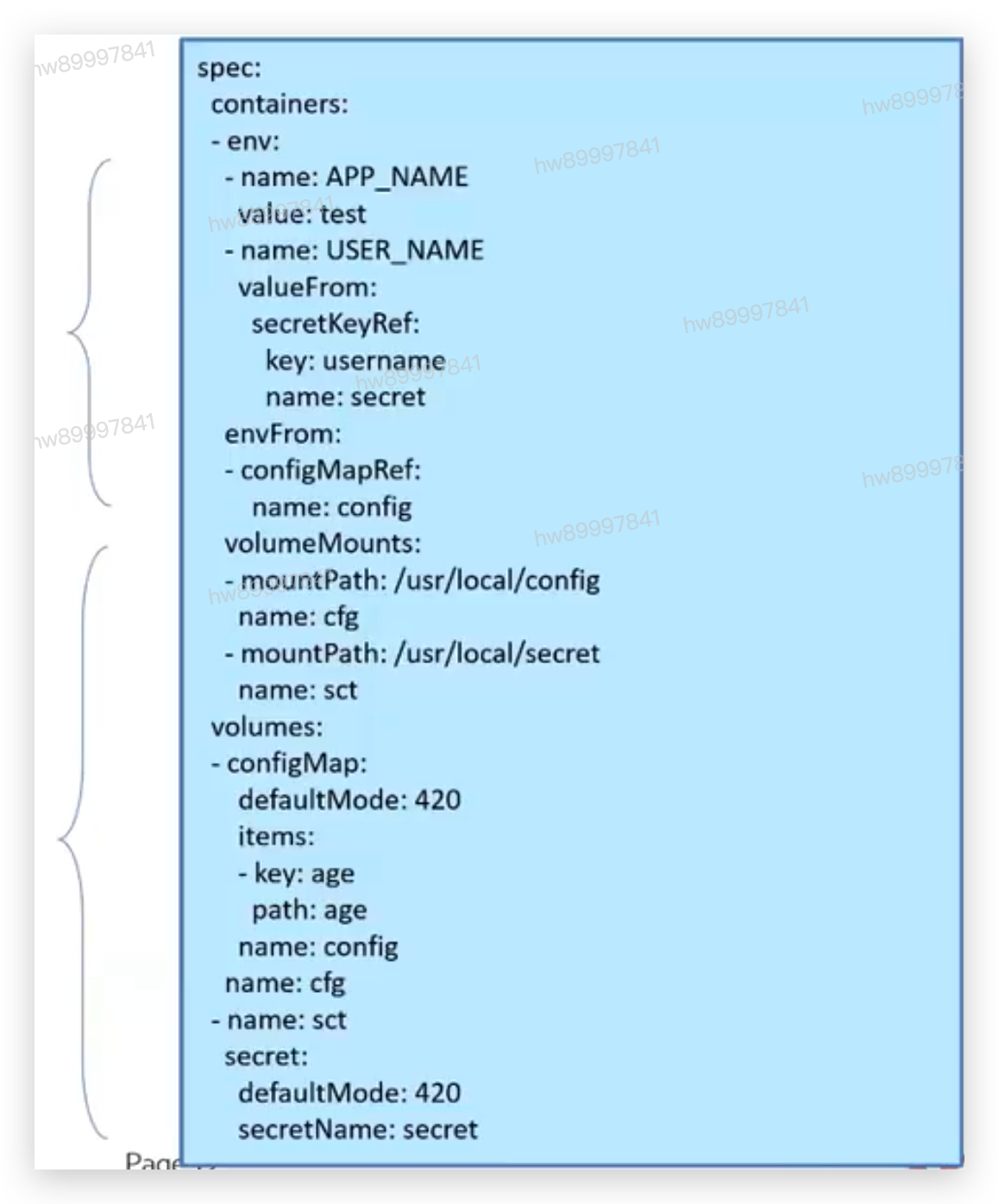
Pod可以接收的外部输入方式:环境变量、配置文件以及密钥。
• 环境变量:使用简单,但- -旦变更后必须重启容器。
• Key-value自定义
• From配置文件(configmap)
• From密钥(Secret)
• 以卷形式挂载到容器内使用,权限可控。
• 配置文件(configmap)
• 密钥(secret)
4.1.4 Pod与工作负载的关系
• 通过label-selector和owerReference相关联
• Pod通过工作负载实现应用的运维,如伸缩、升级等
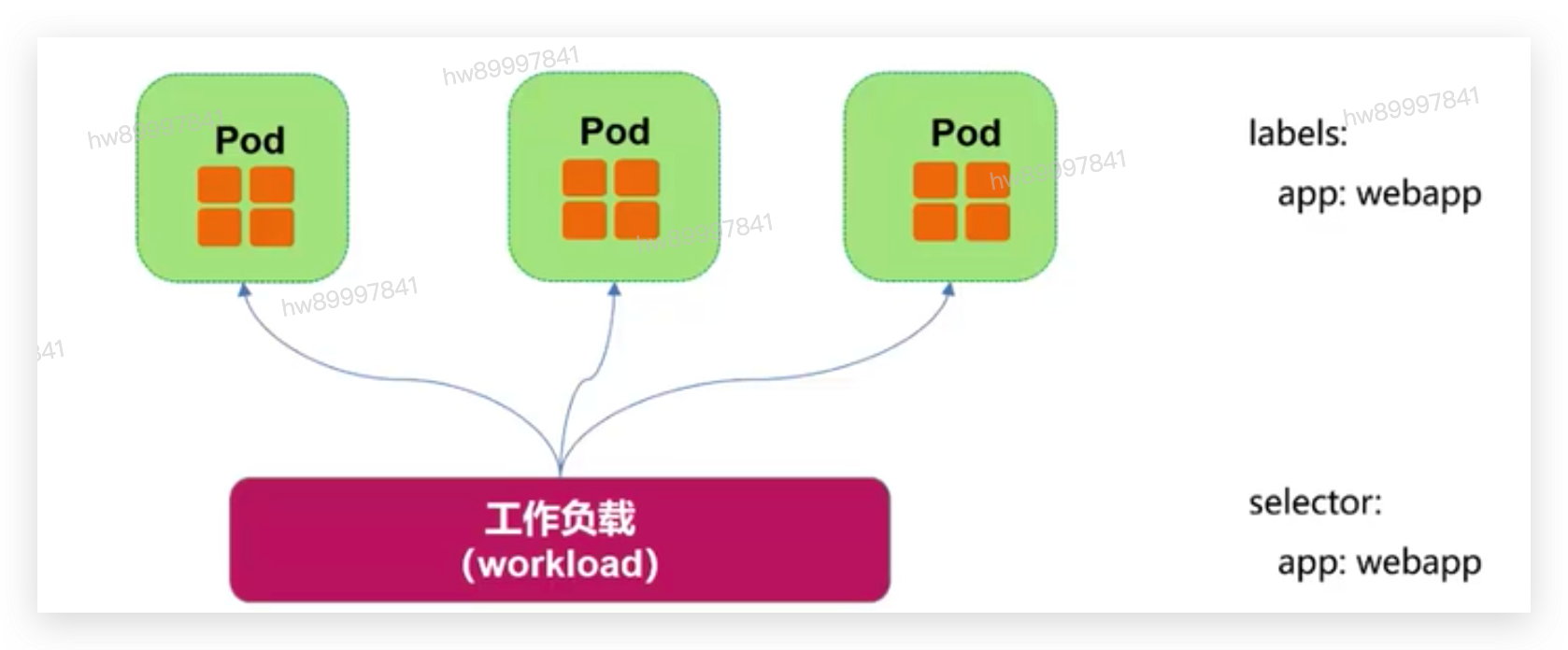
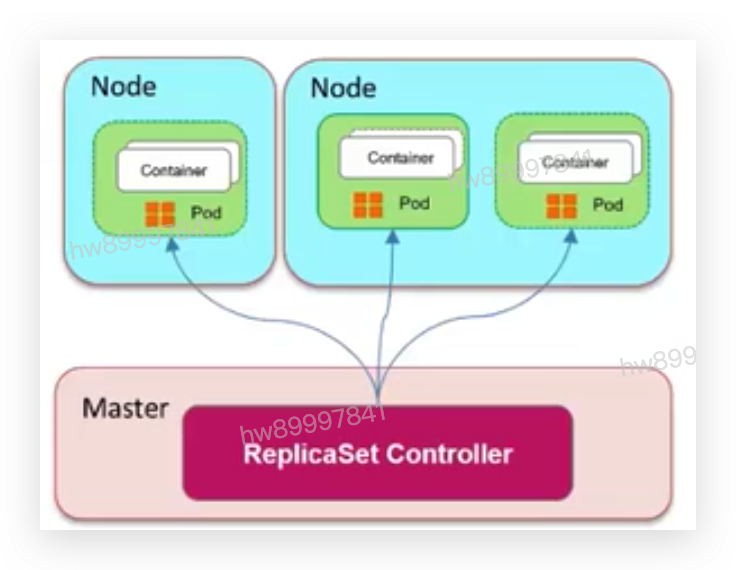
4.2 关键工作负载之-ReplicaSet
• ReplicaSet-副本控制器
• 确保Pod的一定数量的份数(replica)在运行。 如果超过这个数量,控制器会杀死-些, 如果少了控制器会启动一些。
• ReplicaSet用于解决pod的扩容和缩容问题。
• 通常用于无状态应用

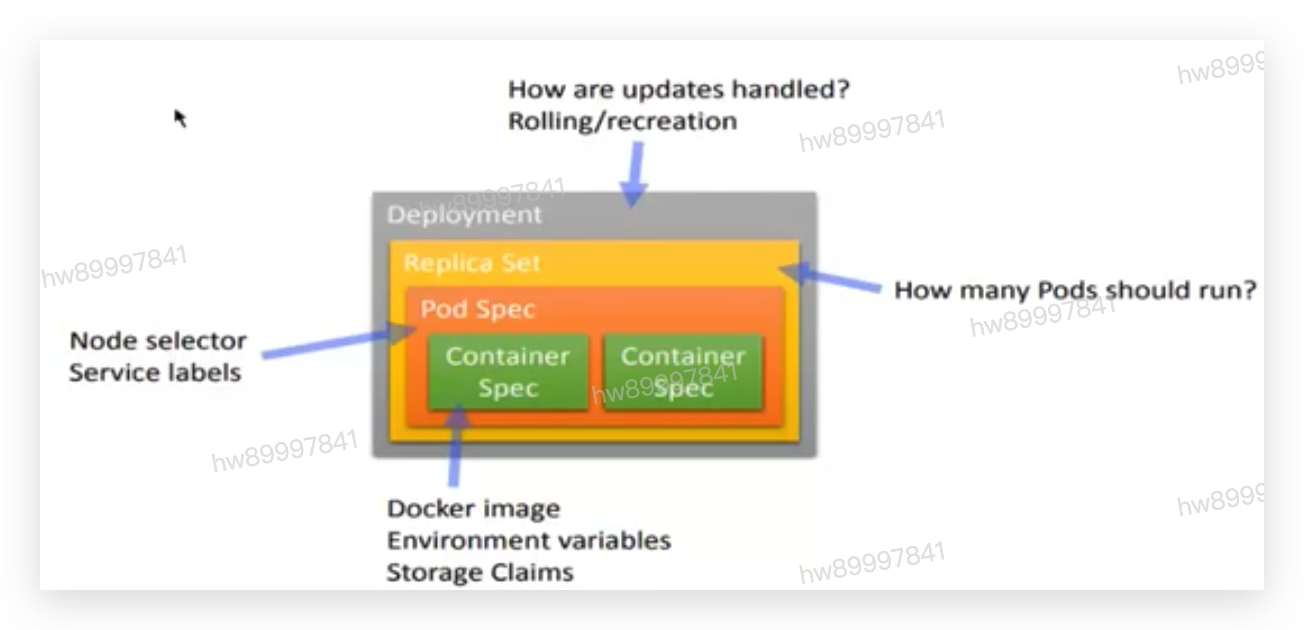
• Kubernetes Deployment提供了官方的用于更新Pod和Replica Set (下-代的Replication
Controller)的方法,您可以在Deployment对象中只描述您所期望的理想状态(预期的运行状态),
• Deployment控制器为您将现在的实际状态转换成您期望的状态;
Deployment集成了,上线部署、滚动升级、创建副本、暂停上线任务,恢复上线任务,回滚到以前某- -版本(成功/稳定)的Deployment等功能, 在某种程度上, Deployment可以帮我们实现无人值守的上线,大大降低我们的上线过程的复杂沟通、操作风险。
• Deployment的典型用例:
• 使用Deployment来启动(上线/部署) -个Pod或者ReplicaSet
• 检查-个Deployment是否成功执行
• 更新Deployment来重新创建相应的Pods (例如,需要使用一个新的Image)
• 如果现有的Deployment不稳定,那么回滚到一个早期的稳定的Deployment版本
五 Kubernetes系统组件
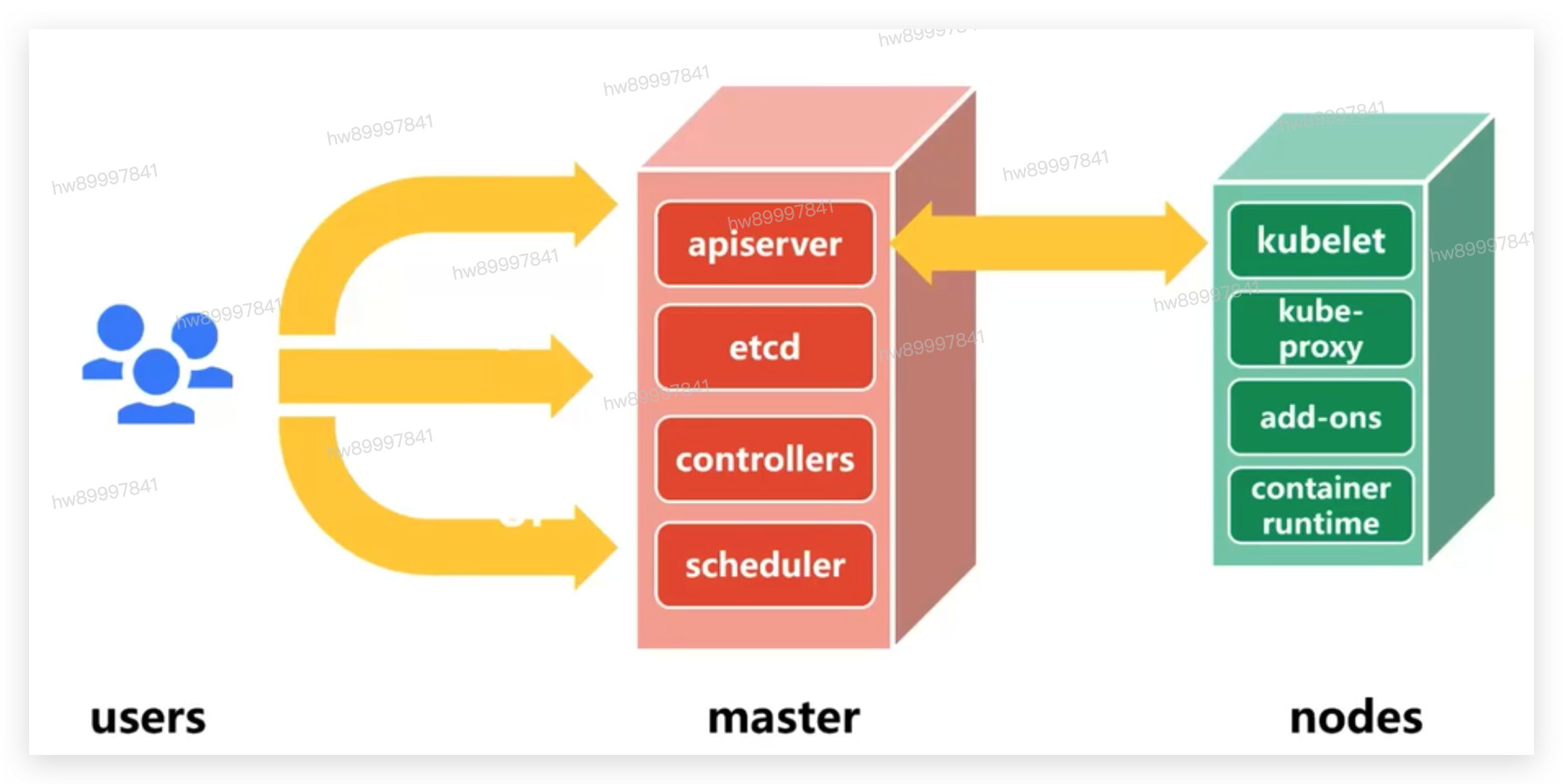
• User:Dashboard,kubectl
• master:apiserver,etcd,controllers,scheduler
• nodes:kubelet,kube-proxy,add-ons,container-runtime
Kubernetes总体架构

• ApiServer
kubernetes 接收用户创建容器等请求的是 Kubernetes Cluster,那么它对外提供服务的接口就是一个 API 接口 ,这个接口需要编程来访问,或者通过编写好的客户端程序来访问,Kubernetes Master 上有一个组件就是 ApiServer,来接收客端请求,解析客户端请求,其主要功能包括认证授权、数据校验以及集群状态变更,以及负责其他模块直接的相互通讯和数据交互,只有api server才能操作etcd,其他模块想要获取数据需要通过api server提供的接口进行相关数据操作
• Scheduler
scheduler watch apiserver,接受系统或用户请求是运行,如何要运行一个pod,那么 Master 会使用调度器(scheduler)根据请求来分配一个能够运行容器的 nodes 节点,例如:根据用户对资源要求,CPU、内存、来评估哪个 nodes 最合适运行。
大概的过程就是:首先是预选,从 nodes 中挑选出符合用户容器运行要求的,然后在这些预选结果中进行优选,选出最佳的适配 node。
• Controller(控制器)
如果运行容器的节点宕机或者容器本身运行出现问题,kubernetes 能够在其他节点再启动一个一模一样的容器,这就是 Kubernetes 提供的自愈能力。
控制器就实现了监控它所负责的每一个容器的健康状态,一旦发现不健康了,那么控制器会向 Master 发送请求,Master 会再次由调度器挑选出合适的节点再次运行这个容器。
它能持续性探测所管理的容器,一旦不健康,或不符合用户定义的健康状态,就会由它发起来请求,来保证容器向用户希望的健康状态迁徙。
而 Kubernets 支持众多的控制器,支持容器健康的控制器只是其中一种。
六 List-watch机制控制器架构
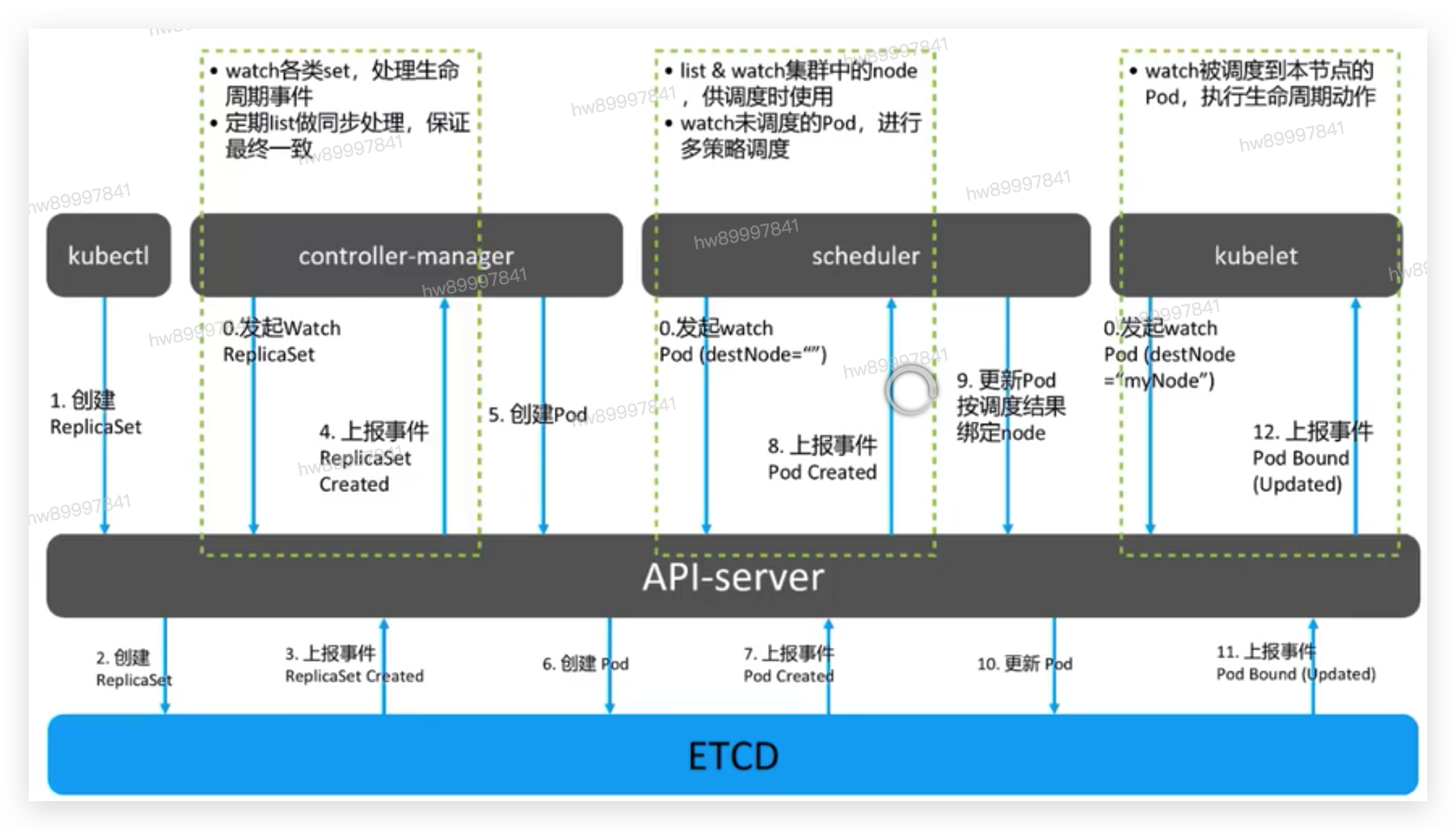
1、客户端提交创建请求,可以通过API Server的Restful API,也可以使用kubectl命令行工具。支持的数据类型包括JSON和YAML。
2、API Server处理用户请求,存储Pod数据到etcd。
3、调度器通过API Server查看未绑定的Pod。尝试为Pod分配主机。
4、过滤主机 (调度预选):调度器用一组规则过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉。
5、主机打分(调度优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把容一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等。
6、选择主机:选择打分最高的主机,进行binding操作,结果存储到etcd中。
7、kubelet根据调度结果执行Pod创建操作: 绑定成功后,scheduler会调用APIServer的API在etcd中创建一个boundpod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步boundpod信息,一旦发现应该在该工作节点上运行的boundpod对象没有更新,则调用Docker API创建并启动pod内的容器。
七 controller

在K8S 拥有很多controller 他们的职责是保证集群中各种资源的状态和用户定义(yaml)的状态一致, 如果出现偏差, 则修正资源的状态.
八 schedule
为pod寻找一个合适的node执行。
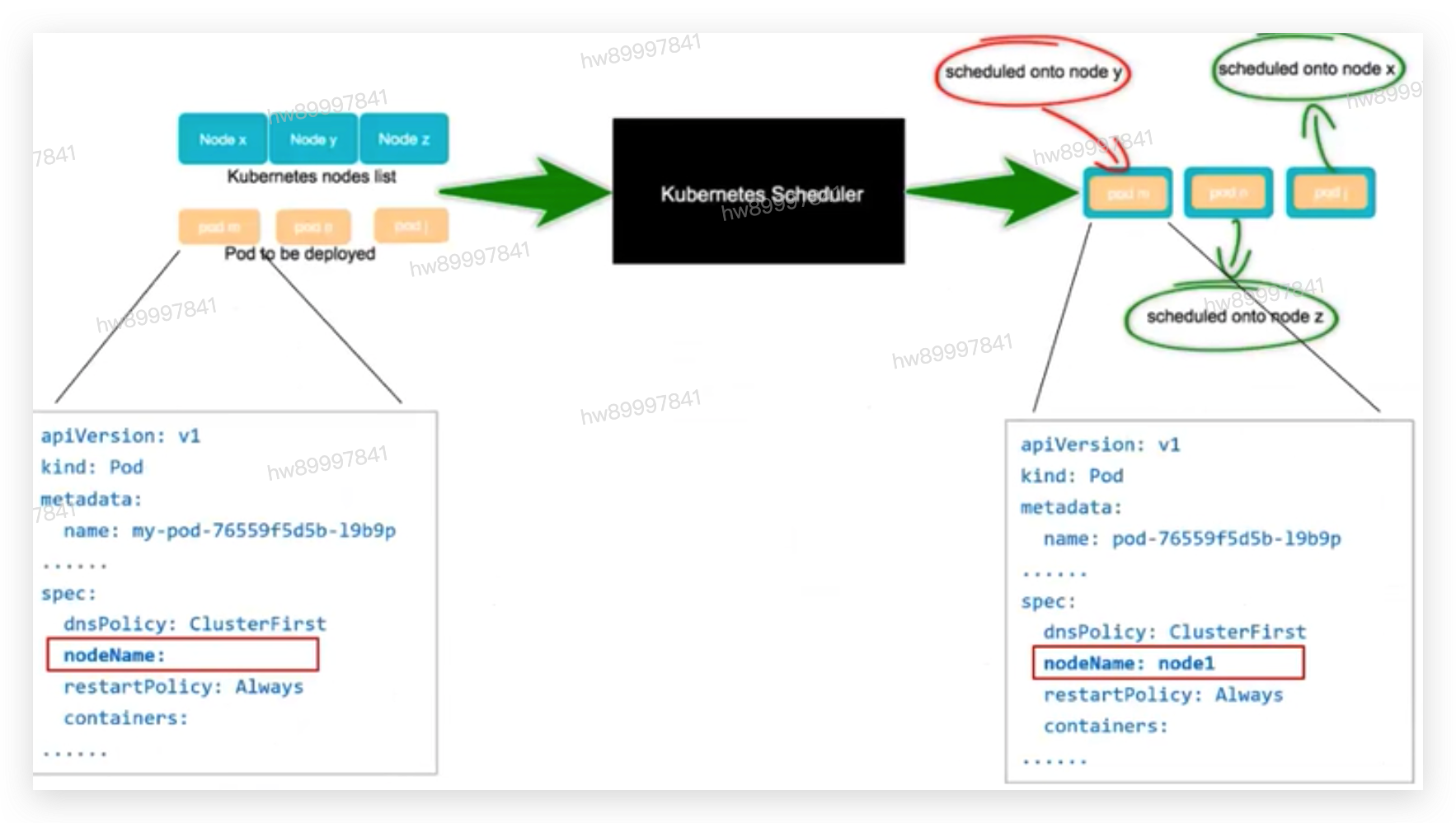
• 预选阶段:排除完全不符合运行这个 POD 的节点、例如资源最低要求、资源最高限额、端口是否被占用
• 优选阶段:基于一系列的算法函数计算出每个节点的优先级,按照优先级排序,取得分最高的 node
• 选中阶段:如果优选阶段产生多个结果,那么随机挑选一个节点
8.1 Default Schedule
基于队列调度器,对节点过滤,之后对节点进行打分,通过此刻全局最优进行调度。

结语
十年云计算浪潮下,DevOps、容器、微服务等技术飞速发展,云原生成为潮流。2020年华为云在业界率先提出了云原生2 .0的理念。云原生2.0是企业智能升级新阶段,企业云化从“ON Cloud”走向“IN Cloud”,成为“新云原生企业”,新生能力与既有能力立而不破、有机协同,实现资源高效、应用敏捷、业务智能、安全可信。
本文整理自华为云社区【内容共创】活动第12期。
查看活动详情:https://bbs.huaweicloud.cn/blogs/325315
相关任务详情:华为云云原生黄金课程03:Kubernetes 系统快速入门

- 点赞
- 收藏
- 关注作者
评论(0)