使用Python爬虫抓取华为商城图片和文字实验丨【我的华为云体验之旅】

今天继续体验华为云的沙箱,在一堆的沙盒中选择了一个感性的爬虫抓取,实验的目的可能不仅仅是抓取的代码,主要还是体验下华为云的使用,目标是明确的,开始吧
1、准备环境
体验地址:https://lab.huaweicloud.cn/testdetail_468
登陆华为云
如果曾经用过沙箱,我想着一步都是通用的,只要按照实验手册操作,登陆进去就可以了
创建云数据库RDS
创建云数据库的目的是为了保存爬取的数据,毕竟不能只是放在内存中,也是为了体验云数据库。
在已登录的华为云控制台,展开左侧菜单栏,点击“服务列表”->“数据库”->“云数据库 RDS”进入云数据库RDS控制台。 点击“购买数据库实例”。
参数设置可以参照实验手册,这里就不赘述了。
注意这里设置的数据库密码,下面将要用来登陆
注意:若参数配置与实验手册不符,系统将自动清理您创建的资源,由此将导致创建不成功
确认参数无误后点击“提交”完成购买,点击“返回云数据库RDS列表”可查看到正在创建的云数据库RDS,约等待【4-6分钟】数据库状态变为“正常”,说明数据库创建完成

创建数据库和表
点击云数据库RDS“rds-spider”进入详情页,选择左侧栏“连接管理”在右侧“公网连接”下,点击“绑定”弹性公网IP,在弹窗中选中弹性公网IP点击“确定”完成绑定
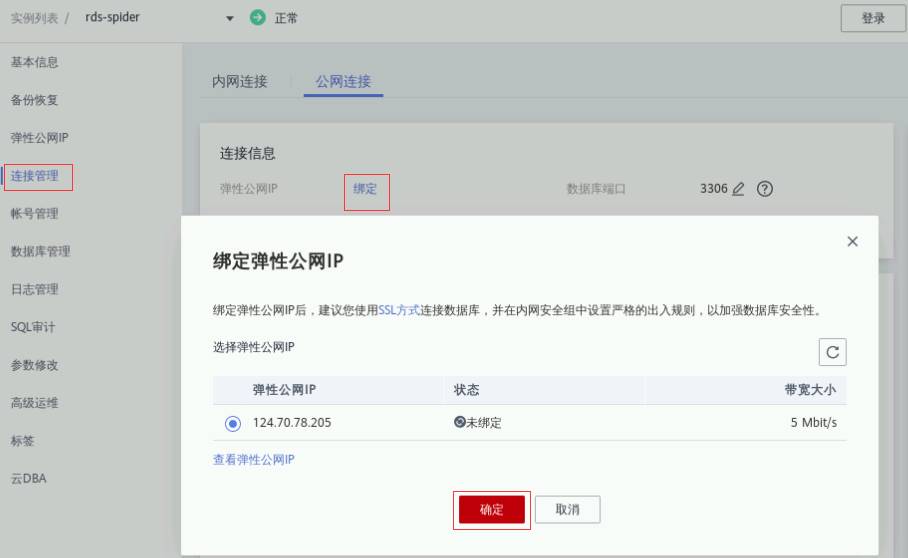
弹性公网IP绑定完成,点击“登录”,输入用户名:root,密码:创建云数据库RDS时设置的密码,如下图所示

登陆进来之后我们创建数据库vmall 和 数据表,点击“+新建表”,表名:“product”,其他参数默认
添加3个字段分别如下: ①列名id,类型int,长度11,勾选主键,扩展信息如下图(id自增长); ②列名title,类型varchar,长度255,勾选可空; ③列名image,类型varchar,长度255,勾选可空。
注:这里可以随意一些,根据自己的需求进行,没必要一定遵循实验手册

2.查看目的网页并编写爬虫代码
环境准备好了,下面开始业务逻辑的编写
业务分析
目标网站:https://sale.vmall.com/huaweizone.html
分析目标地址:https://www.vmall.com/product/10086151859746.html#2801010096501
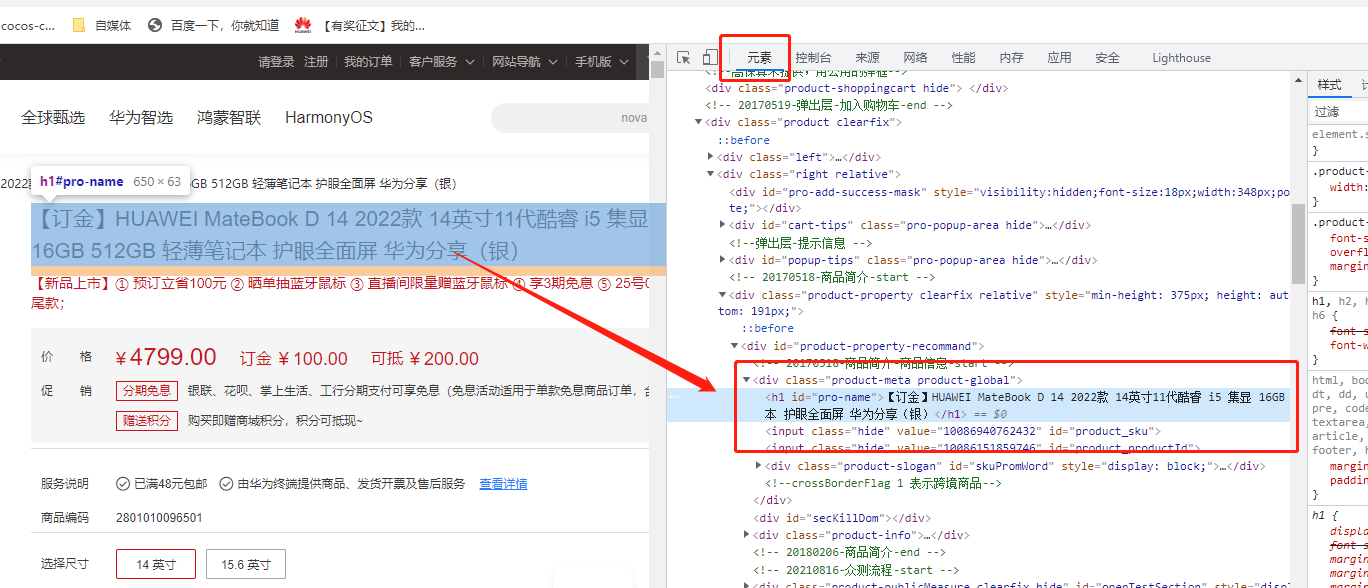
按“F12”查看网页元素,选择“鼠标跟随”按钮查看元素,然后点击网页中某个元素,可以看到源码界面显示了此元素对应的源码片段,从该源码片段中找到元素class或是id属性,如下图所示:
创建爬虫项目并导入
切换到【实验操作桌面】,打开“Xfce终端”,依次执行以下命令在桌面新建项目文件夹。
cd Desktop
scrapy startproject vmall_spider
cd vmall_spider
scrapy genspider -t crawl vmall "vmall.com"
在桌面打开Pycharm导入项目,常规操作,没难度,也不赘述了
编写爬虫代码
在项目“vmall_spider”->“spiders”下,双击打开“vmall.py”文件,删除原有代码,写入以下代码
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from vmall_spider.items import VmallSpiderItem
class VamllSpider(CrawlSpider):
name = 'vamll'
allowed_domains = ['vmall.com']
start_urls = ['https://sale.vmall.com/huaweizone.html']
rules = (
Rule(LinkExtractor(allow=r'.*/product/.*'), callback='parse_item', follow=True),
)
def parse_item(self, response):
title=response.xpath("//div[@class='product-meta product-global']/h1/text()").get()
price=response.xpath("//div[@class='product-price-info']/span/text()").get()
image=response.xpath("//a[@id='product-img']/img/@src").get()
item=VmallSpiderItem(
title=title,
image=image,
)
print("="*30)
print(title)
print(image)
print("="*30)
yield item双击打开“itmes.py”文件,删除原有代码,写入以下代码:
import scrapy
class VmallSpiderItem(scrapy.Item):
title=scrapy.Field()
image=scrapy.Field()双击打开“pipelines.py”文件,删除原有代码,写入以下代码(使用步骤1.3创建的云数据库RDS的密码、步骤1.4绑定的弹性公网IP替换代码中的相关信息)
import pymysql
import os
from urllib import request
class VmallSpiderPipeline:
def __init__(self):
dbparams={
'host':'124.70.15.164', #云数据库弹性公网IP
'port':3306, #云数据库端口
'user':'root', #云数据库用户
'password':'rIDM7g4nl5VxRUpI', #云数据库RDS密码
'database':'vmall', #数据库名称
'charset':'utf8'
}
self.conn=pymysql.connect(**dbparams)
self.cursor=self.conn.cursor()
self._sql=None
self.path=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
if not os.path.exists(self.path):
os.mkdir(self.path)
def process_item(self,item,spider):
url=item['image']
image_name=url.split('_')[-1]
print("--------------------------image_name-----------------------------")
print(image_name)
print(url)
request.urlretrieve(url,os.path.join(self.path,image_name))
self.cursor.execute(self.sql,(item['title'], item['image']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql="""
insert into product(id,title,image) values(null,%s,%s)
"""
return self._sql
return self._sql注意:上面的数据库参数要换成沙箱内的数据
核心代码就上面这些,一些配置相关的代码,可以参照实验手册就不赘述了
3.在弹性云服务器ECS上运行爬虫程序
登陆云服务器进行安装依赖,也就是布置python的运行环境

执行下面这些命令,安装环境
yum -y groupinstall "Development tools"
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
yum install gcc libffi-devel python-devel openssl-devel -y
yum install libxslt-devel -y
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip执行下面这些命令,安装python所需要的三方包
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pymysql
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pillow上传代码
cd /home/user/Desktop && scp -r ./vmall_spider root@EIP:/root上传过程如下 :

运行代码
再次登陆云服务器
执行以下命令启动爬虫项目,运行片刻(约30秒),按“Ctrl+Z”键停止运行程序。
cd /root/vmall_spider/vmall_spider/ && python3 start.py查看爬取数据
切换至【实验操作桌面】浏览器已登录云数据库RDS页面,点击“对象列表”->“打开表”如下图所示:

可看到已爬取的数据,如下图所示:

总结:
整个实验过程基本上就是我们拿到一个新项目的环境搭建过程
-
首先拿到一台电脑,创建ecs
-
安装数据库,部署RDS
-
创建数据库和表,创建数据库vmall 和 表名:“product”
-
分析业务需求,对网页进行分析
-
编写代码,实验手册提供了详细的代码
-
【我的华为云体验之旅】有奖征文火热进行中:

- 点赞
- 收藏
- 关注作者
评论(0)