【云驻共创】目标检测算法TSD解耦分类与回归

华为云AI论文精读会2021 第七期:目标检测算法TSD解耦分类与回归
目录:
前言和导读
1.论文的研究背景及成果模型
2.剖析及算法创新点讲解
3.代码思路讲解及实操
总结
前言和导读:
针对当前AI经典论文算法在开源社区上的代码质量参差不齐,很多代码不好用、难用、甚至用不了,以及一些论文作者不共享源代码,无法指导AI开发者可以更好的参考与探索的现状,华为云官方将一些经典而又常用的论文算法上线华为云一站式AI开发平台ModelArts,供广大AI开发者免费使用,降低开发者学习门槛;同时发起华为云AI经典论文复现活动,鼓励参与者基于ModelArts复现AI经典论文,并将复现的论文算法开放共享到ModelArts AI Gallery, 打造AI开发者学习社区,从而达到赋能AI开发者,让更多人来低门槛使用经典的算法目标。
目前,已经有百余篇AI经典论文算法上线华为云AI Gallery,开发者可以了解算法介绍、查看代码,以及一键订阅算法,在ModelArts平台进行训练和推理。华为云ModelArts产品团队表示,将这些百余篇AI经典论文算法与现有教程结合,构建一整套由浅入深的“AI学习天梯”,帮助各行各业的开发者在人工智能领域“渐入佳境”。
目标检测
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。
在计算机视觉中,目标检测是一项将对象与背景区分开,并预测图像中存在的对象的位置和类别的任务。当前的深度学习方法试图将其作为分类问题或回归问题或综合两者的目标检测任务来解决。
例如,在RCNN算法中,从输入图像中识别出几个感兴趣的区域,然后将这些区域分类为对象或背景,最后使用回归模型为所标识的对象生成边界框。
另一方面,YOLO框架(只看一次)以不同的方式处理目标检测,它在单个实例中获取整个图像,并预测这些框的边界框坐标和类概率。
代表性AI经典论文算法:目标检测-TSD
目前很多研究表明目标检测中的分类分支和定位分支存在较大的偏差,论文从sibling head改造入手,跳出常规的优化方向,提出TSD:Revisiting the Sibling Head in Object Detector方法解决混合任务带来的内在冲突,该方法可以灵活插入大多检测器中,帮助通用的检测器大幅度提升性能3%-5%,在COCO上,基于ResNet-101可以达到49.4的map,在SENet154上可以达到51.2。
此模型基于Revisiting the Sibling Head in Object Detector 中提出的模型结构实现,该算法会载入在COCO上的预训练模型,在用户数据集上做迁移学习。我们提供了训练代码和可用于训练的模型,用于实际场景的微调训练。训练后生成的模型可直接在ModelArts平台部署成在线服务。
目标检测的评估手段一般使用AP指标,详细说明请参考原论文。
一、 论文概述
1.1基本信息

论文标题:Revisiting the Sibling Head in Object Detector
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/2003.07540
该论文名为 Revisiting the Sibling Head in Object Detector,其提出基于任务间空间自适应解耦(task-aware spatial disentangl该论文名为 Revisiting the Sibling Head in Object Detector,其提出基于任务间空间自适应解耦(task-aware spatial disentanglement,TSD)的检测算法能够有效地减弱通用物体检测中分类任务和回归任务之间的潜在冲突,可以灵活插入大多检测器中,在 COCO 和 OpenImage 上给任意 backbone 提升 3~5% 的 mAP。
该算法也作为核心解决方案(https://arxiv.org/abs/2003.07557)帮助港中文商汤联合实验室取得 OpenImage Object Detection Challenge 2019 冠军。
1.2 研究背景(目标检测)
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
计算机视觉中关于图像识别有四大类任务:
(1)分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
(2)定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
(3)检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。
(4)分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
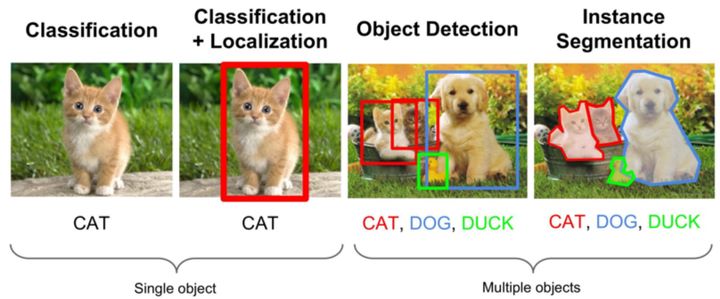
目标检测任务可分为两个关键的子任务:目标分类和目标定位。
目标分类给出Proposal框的confidence score,目标定位回归出准确的bounding box.目前的主流的detector算法主要有:
• Two-stage detector: RCNN,Faster RCNN, Mask RCNN, Cascade RCNN
• One-stage detector: SSD, YOLO-vx ...
• Anchor Free: FCOS,
• Transformer
1.3 相关工作
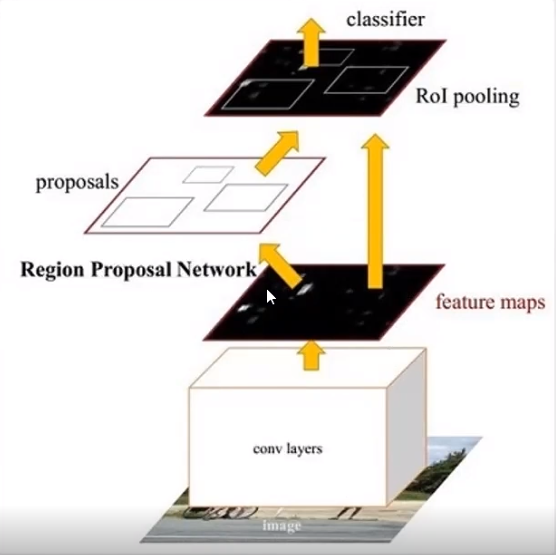
1.Faster RCNN
Faster RCNN整体结构可以分为如下四个模块:
A. Conv layers:提取特征图
B. RPN(Region Proposal Networks):生成region
C. Roi Pooling: 得到固定大小的proposal feature map
D. 全连接层(Sibling head) :进行全连接操作,进行分类和回归。
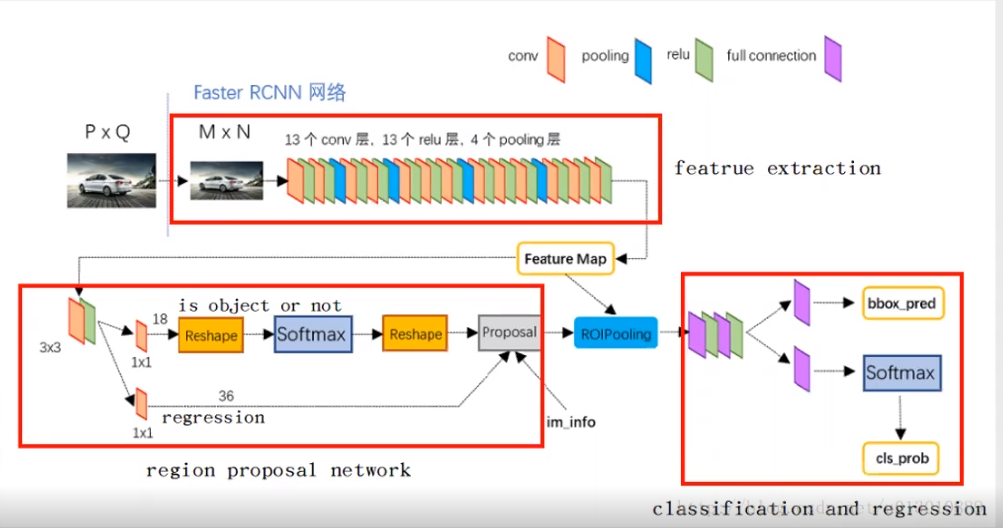
上图是具体的网络结构。下面对这几个模块分别做介绍。
A.Conv layers
Faster RCNN首先使用一组基础的conv+relu+pooling层提取inputimage的feature maps,该featuremaps会用于后续的RPN层和全连接层。
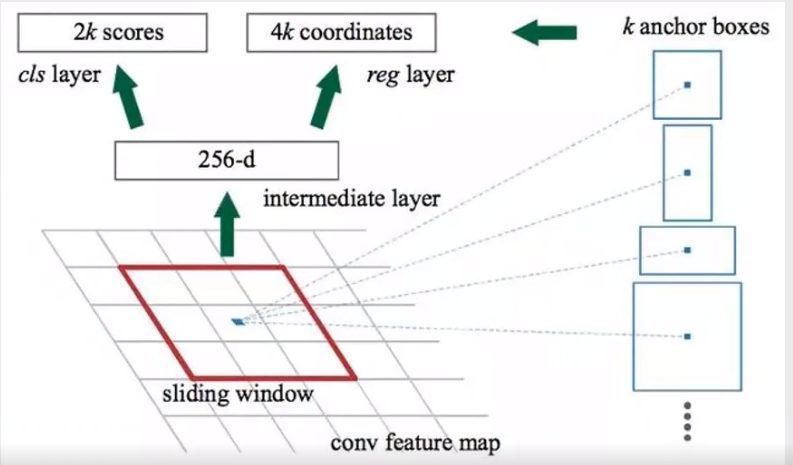
B. RPN(Region Proposal Network)
首先将Conv layers提取的特征图传递到RPN中,RPN会在这些特征映射上使用一个滑动窗口,每个窗口会生成具有不同形状和尺寸的k个anchor box。对每个anchor,RPN都会预测两点:
· anchor是目标物体的概率(不考虑类别)
· anchor经过调整能更合适目标物体的边界框回归量
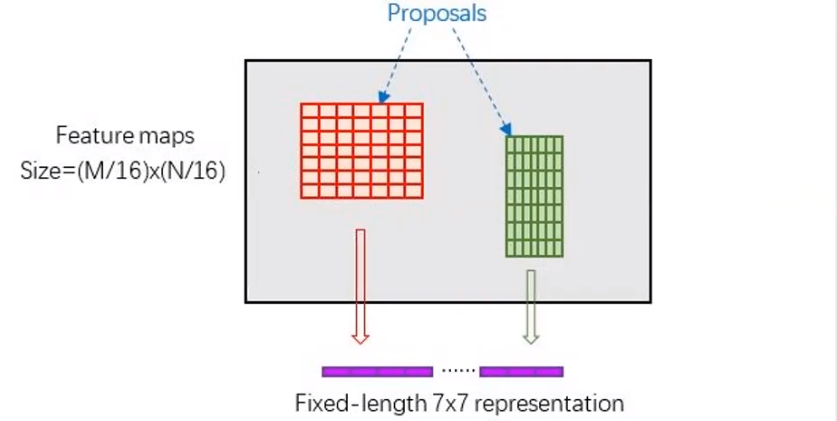
C. Roi Pooling
该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
Roi Pooling将每个proposal对应的featuremap区域水平分为pooled_w x pooled_h的网格;对网格的每一份都进行max pooling处理。这样处理后,即使大小不同的proposal输出结果都是固定大小。
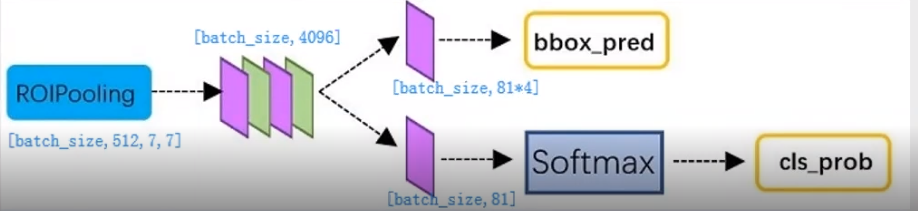
D. 全连接Sibling Head
利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
经过roi pooling层之后,对特征图进行全连接,完成两件事情:
·分类:通过全连接和softmax对region proposals进行具体类别的分类
·回归:再次对region proposals进行bounding box regression,获取更高精度的rectanglebox
1.4 主要贡献
·深入研究了基于roi的检测器中纠缠任务背后的本质障碍,揭示了制约检测性能上限的瓶颈。
·提出了一种简单的任务感知空间解缠(TSD)算子来处理复杂的任务冲突。通过任务感知的建议估计和检测头,生成任务特定的特征表示,消除分类和定位之间的折衷。
·我们进一步提出了一个渐进约束(PC)来扩大TSD与经典同辈头之间的性能差距。
·我们通过深入的消融实验,在标准的COCO基准和大规模的Openlmage数据集上验证了我们的方法的有效性。通过与现有方法的比较,我们提出的方法使用单一模式的ResNet-101主干实现了49.4的mAP,使用重SENet154实现了51.2的mAP。
二、算法模型剖析
2.1 研究动机(Motivation)
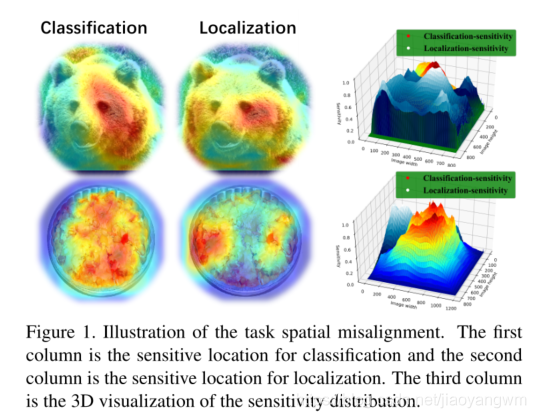
在这篇论文中,我们仔细地重新讨论了anchor-based的目标探测器中的 sibling head,以寻找任务不对齐的本质。我们探讨了FPN特征金字塔中各层输出特征图的分类和定位的空间敏感性。第一列是用于分类的空间敏感热图,第二列是用于定位的热图。越暖和颜色越好。我们也在第三栏展示了他们的3D可视化效果。很明显,一些突出区域的特征可能具有丰富的分类信息,而边界周围的特征可能擅长边界盒回归。这种重要的任务在空间维度上的不一致极大地限制了性能的提高,无论是改进主干还是增强检测头。换句话说,如果一个检测器试图从一个相同的空间点/锚推断分类分数和回归结果,那么它总是会得到一个不完美的折衷结果。
这个重要的发现促使我们重新思考兄弟头的结构。这种问题的最优解就是通过空间解耦的方法来解决。在此基础上,我们提出了一种新的基于任务感知的空间解纠缠(TSD)算子来解决这一障碍。
·分类与回归的矛盾
目标检测算法中,一般网络顶层都有全连接头,Sibling head 分别进行物体分类与检测框定位回归。
然而分类与回归两个不同的任务几乎共享相同的参数,但分类与回归所倾向的feature是不同的,比如图像中的某些显著区域的feature更适合分类而边界区域更适合检测框回归。
·Misaligned sensitivity in the spatial dimension between classification and localization.
2.2 模型总览:TSD
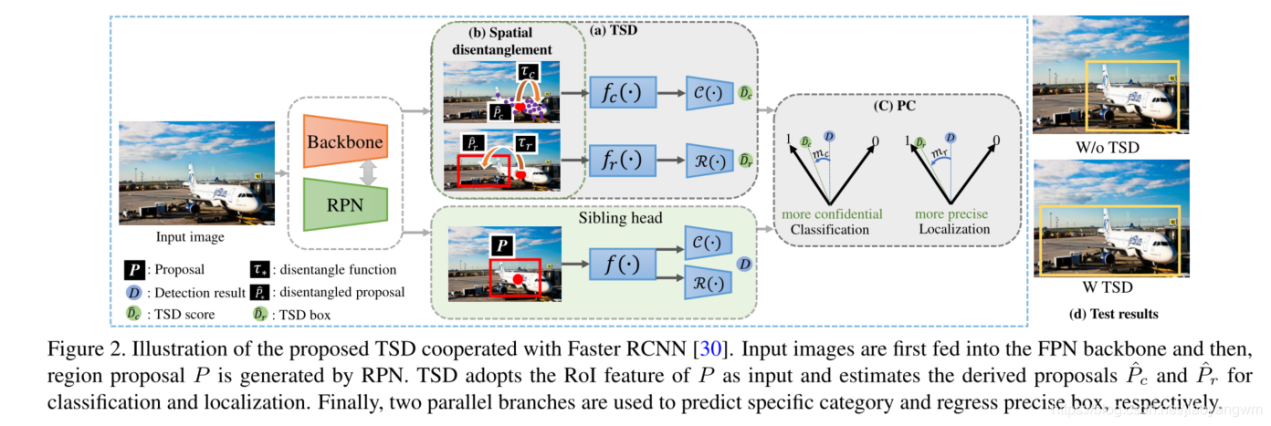
如图为使用TSD结合Faster R-CNN算法的整体示意图,重点学习的三部分为(a)TSD,(b)Spatial disentanglement 和(c)PC (progressive constraint)。
a. 将图片输入骨干网络提取特征
b. 通过RPN得到响应图
c. 通过Sibling head生成proposal
d. 将生成的每个proposal输入到Spatial distanglement模块分别得到用于分类的proposal和用于回归的proposal,即每个proposal会生成两个proposal,一个用于分类,另一个用于回归
e. 将用于分类的propostal输入分类分支得到分类得分;将用于回归的proposal输入回归分支得到回归偏移
f. 通过nms得到最终结果
2.3 TSD模型与Spatial disentanglement
TSD的全称为task-aware spatial disentanglement,即任务感知空间解缠。TSD本质上是将分类任务和定位任务从空间上分别解析,基于经典的sibling head中的原始proposal,为两个任务分别生成两个独立的proposals,这样允许两个任务在不影响彼此的情况下自适应地找到空间中的最佳位置。

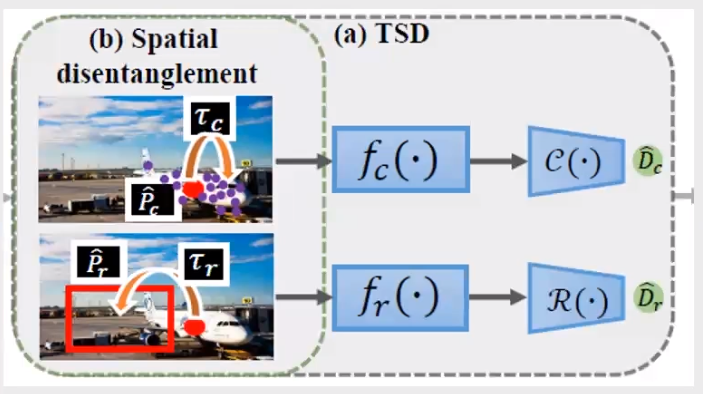
将proposal的ROI特征输入到上图b中,然后使用一个3层的全连接网络生成两个proposal,一个用于分类,一个用于回归。该模块通过下述公式学习相应的特征偏移。
• 回归Proposal P =P+ΔR
• ΔR由三层全连接网络回归得到,为每个proposalР预测一个偏移:
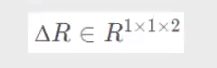
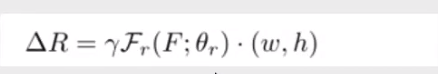
·分类Proposal PC = P+ΔC
ΔC也由三层全连接网络回归得到,但与FR共享第一层权重。Fc为每个proposal P预测k*k个偏移,生成一个形变的不规则的proposal Pc.
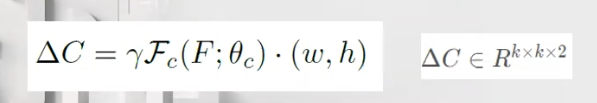
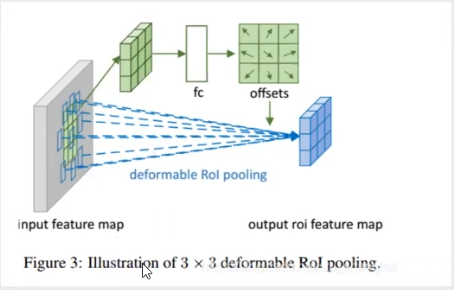
Deformable Rol pooling:
可以用线性插值从irregular proposal Pc得到Feature
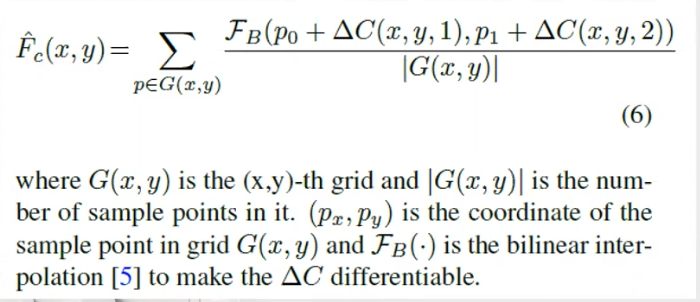
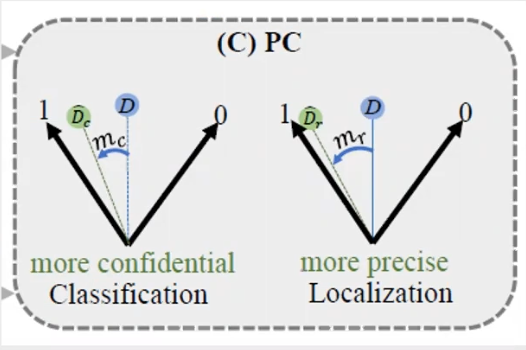
Progressive constraint 渐进性约束
PC就是使得TSD和传统ROI Pooling主干(sibling head)结果保持一定margin,使得TSD部分的回归分类结果优于sibling head分支的结果。
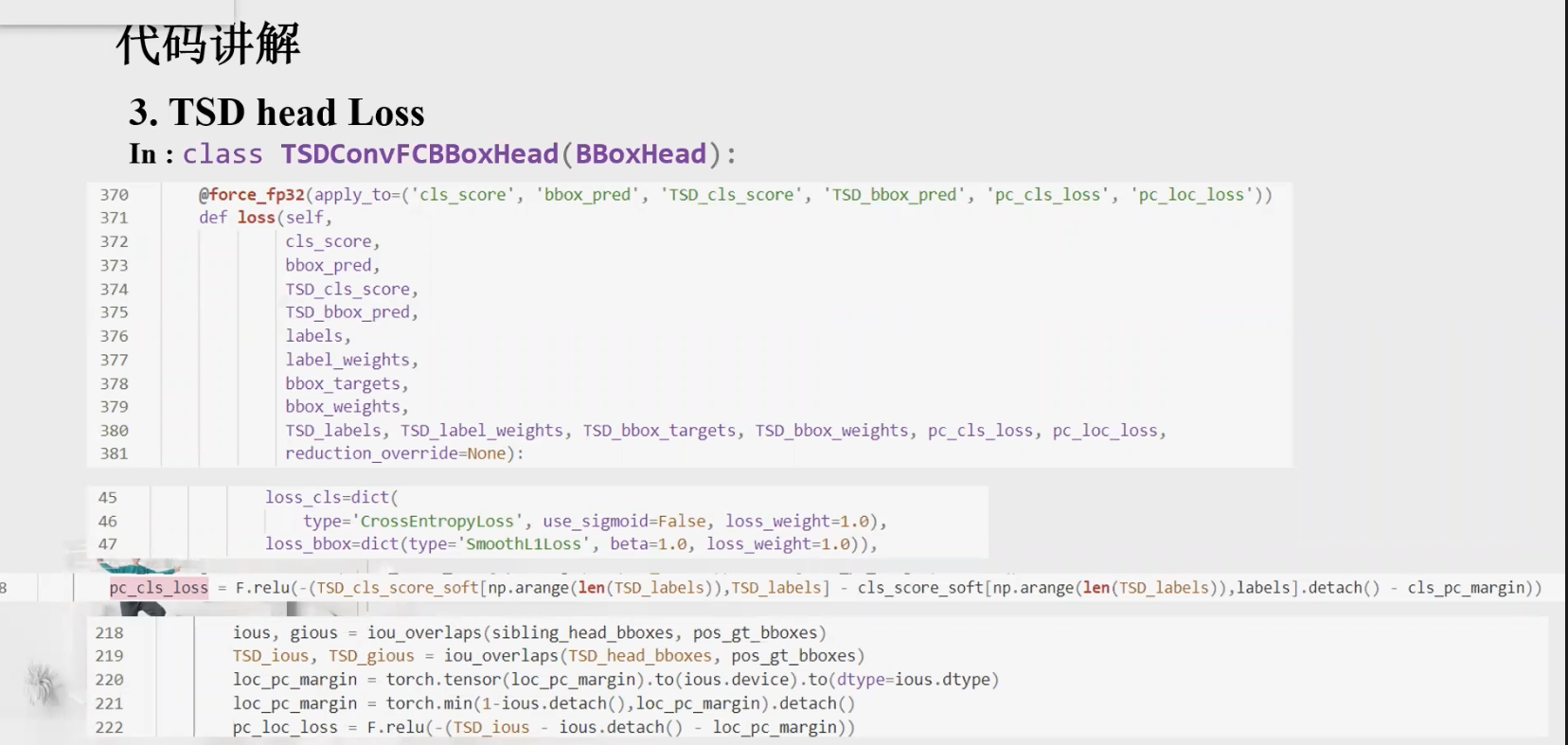
2.4 常见的损失函数(loss function)
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
• Progressive constraint (PC)渐进约束:
通过progressive constraint (PC)来增加TSD和传统的head之间的performance margin。
Predefined Margin Loss,比原本的Sibling Head预测的confidence和IOu高预定义的margin距离。
为了进一步提升任务间自适应空间解耦算法的训练,我们进一步提出渐进学术 (PC),来使得 TSD 的检测器头部对于分类任务和定位任务的表现要优于原始的结构。
对于分类任务,有:
• For Classification Branch:
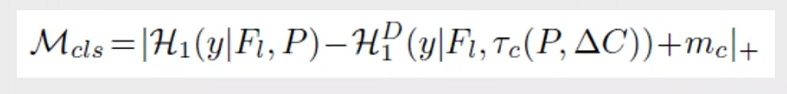
• For Regression Branch:
其中 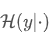 表示对于第 y 类的预测置信度,
表示对于第 y 类的预测置信度,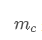 是预定于的 margin。对于定位任务有:
是预定于的 margin。对于定位任务有:
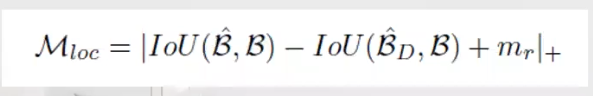
• Overall Loss:
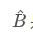 是原始检测器头部得到的检测框,
是原始检测器头部得到的检测框, 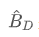 是 TSD 算法得到的检测框。如果当前的 proposal 是一个负样本,那么该 loss 会被 ignore。
是 TSD 算法得到的检测框。如果当前的 proposal 是一个负样本,那么该 loss 会被 ignore。
综上,在整个训练过程中,整体检测器的优化为:
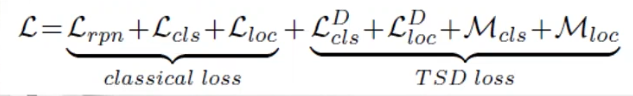
在推理阶段,原始的检测器头部不再使用。
2.5 实验结果
1. COCO 2017test-dev result:
首先将 TSD 与在不同的 level 进行任务间解耦的结构进行比较,如图所示:
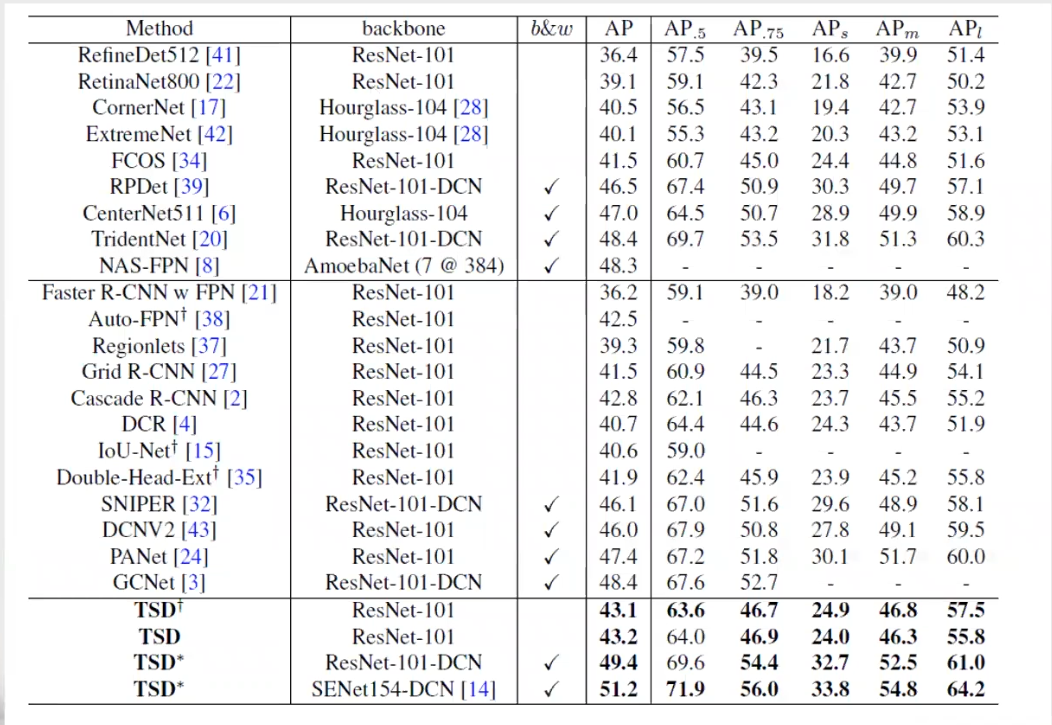
可以看到无论是从参数量上还是从性能上,TSD 都有着明显的优势。
2.使用不同的Backbone:
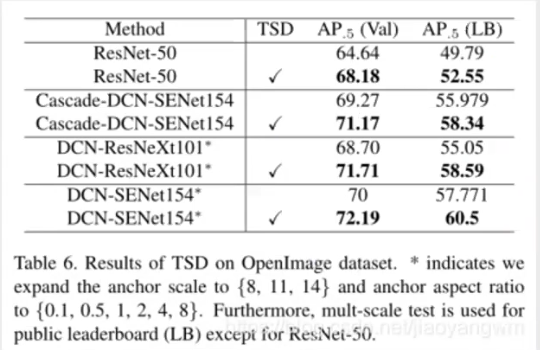
3.PC的有效性
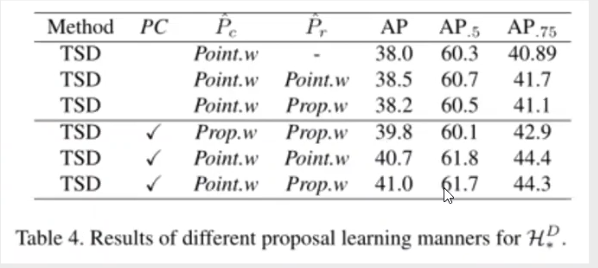
建议使用PC来提高TSD的性能。表中报告了详细的烧蚀情况。我们发现PC显著提高了ap.75 1.5,而ap.5几乎没有受到影响。这说明PC的目标是提倡对准确的盒子进行更机密的分类和精确的回归。即使在严格的测试标准下(IoU从0.5:0.95),也可以获得1.3的AP增益。
三、代码复现
3.1 复现思路
原则是先实现,再调优以达到论文要求。
秉承“站在巨人肩膀上”的思想,我们首先在GitHub上查找开源代码,在开源代码基础上进行调优。
商汤开源的TSD检测代码,是基于mmdetection目标检测库的。由于开源仓库缺少我们要训练的模型设置细节,我们在开源代码的基础上,参考原论文实现细节,使用八卡复现了Table 8倒数第二行的模型精度(AP-49.4 in COCO)。


https://github.com/Sense-X/TSD 扫码查看参考代码仓库
3.2 ModelArt环境介绍
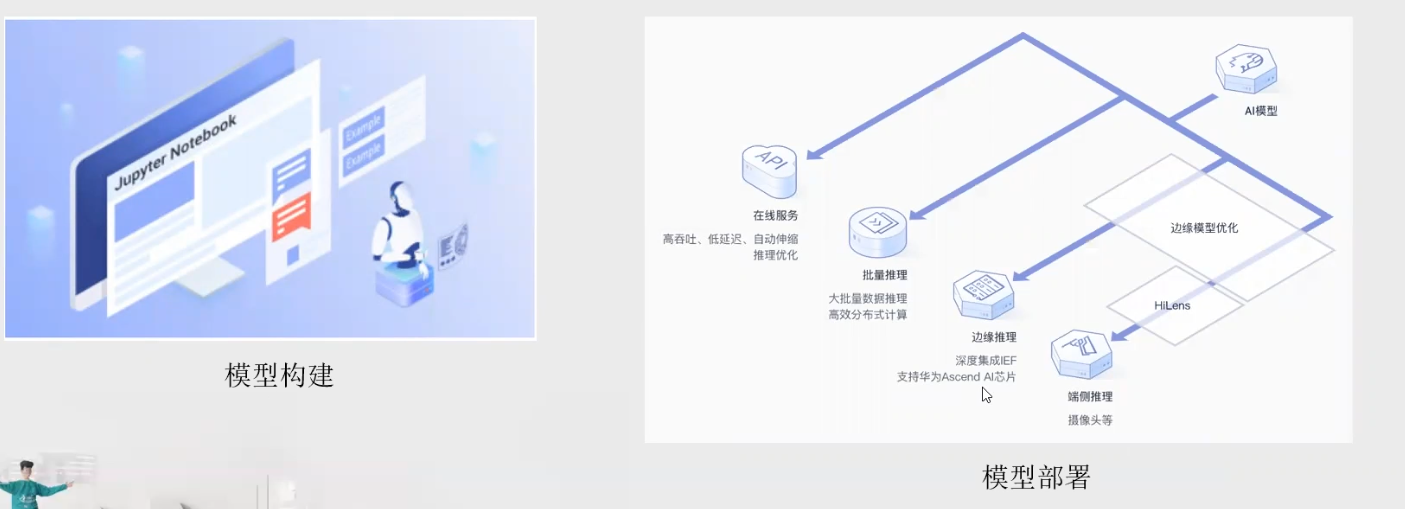
ModelArts是面向AI开发者的一站式开发平台,通过AI开发全流程管理助您智能、高效地创建AI模型和一键部署到云、边、端。
ModelArts不仅支持自动学习功能,还预置了多种已训练好的模型,同时集成了Jupyter Notebook,提供在线的代码开发环境。
根据经验选择您的使用方式
• 如果您是业务开发者,没有AI开发经验,您可以使用ModelArts的自动学习功能,进行零基础构建AI模型,详细介绍请参见业务开发者:使用自动学习构建模型 。
• 如果您是AI初学者,有一定AI基础,您可以使用自己的业务数据对ModelArts预置算法进行重训练,从而得到新模型,详细介绍请参见AI初学者:使用订阅算法构建模型 。
• 如果您是AI工程师,熟悉代码编写和调测,您可以使用ModelArts提供的在线代码开发环境,编写训练代码进行AI模型的开发,详细介绍请参见使用自定义算法在ModelArts上构建模型 和使用线上环境Notebook构建模型 。如果您更习惯使用本地PyCharm工具开发模型,建议可参考使用PyCharm ToolKit在本地进行云上训练 ,安装ModelArts ToolKit工具,在本地完成代码开发后,将代码提交至ModelArts公有云端进行训练和推理。
3.3 MMDetection库介绍

香港中文大学-商汤科技联合实验室开源了基于 PyTorch 的检测库——mmdetection。商汤科技和港中大组成的团队在 2018年的COCO 比赛的物体检测(Detection)项目中夺得冠军,而 mmdetection 正是基于 COCO 比赛时的 codebase 重构。
这个开源库提供了已公开发表的多种视觉检测核心模块。通过这些模块的组合,可以迅速搭建出各种著名的检测框架,比如 Faster RCNN,Mask RCNN,R-FCN,RetinaNet ,Cascade R-CNN及ssd 等,以及各种新型框架,从而大大加快检测技术研究的效率。遗憾的是现在还没有出yolo网络。
mmdetection是港中文mmlab openproject的一部分。包含很多开源的目标检测算法实现,例如Faster RCNN,Mask RCNN, RetinaNet
它的主要特点是:·模块化设计·高效,速度快·支持的检测算法效果好
3.4 复现步骤
1.Details for Reproduction:

• Backbone: ResNet-101+Deformable Convolution
• Basic Detector: Cascade R-CNN
• Train:Multi-scale train, x3 epochs,lr=0.04, warmup from 0.00125,SGD(momentum=0.9,1e-4 weight decay), batchsize=32 with 16 V100.
• Test: Multi-scale test,Soft-NMS
2. 使用MMDetection
·使用作者repo提供的mmdetection (https://github.com/Sense-X/TSD), 按指南build from source即可。
·由于mmdetection是模块化设计,我们只需要编辑要训练模型的config即可。
·数据集准备:从coco网站https://cocodataset.org/#download下载coco2017。
·训练:我们使用8卡V10o训练,相应的batchsize设为8,learning rate设为0.02。
mmdetection提供了tools/train.py训练接口,此处我们使用分布式训练脚本:
./tools/dist_train.sh <config_file> <GPU_NUM>[optional arg]
测试: mmdetection提供了tools/test.py,以及分布式test脚本:./tools/dist_test.sh
3.5 代码讲解
1.Mmdetection overview
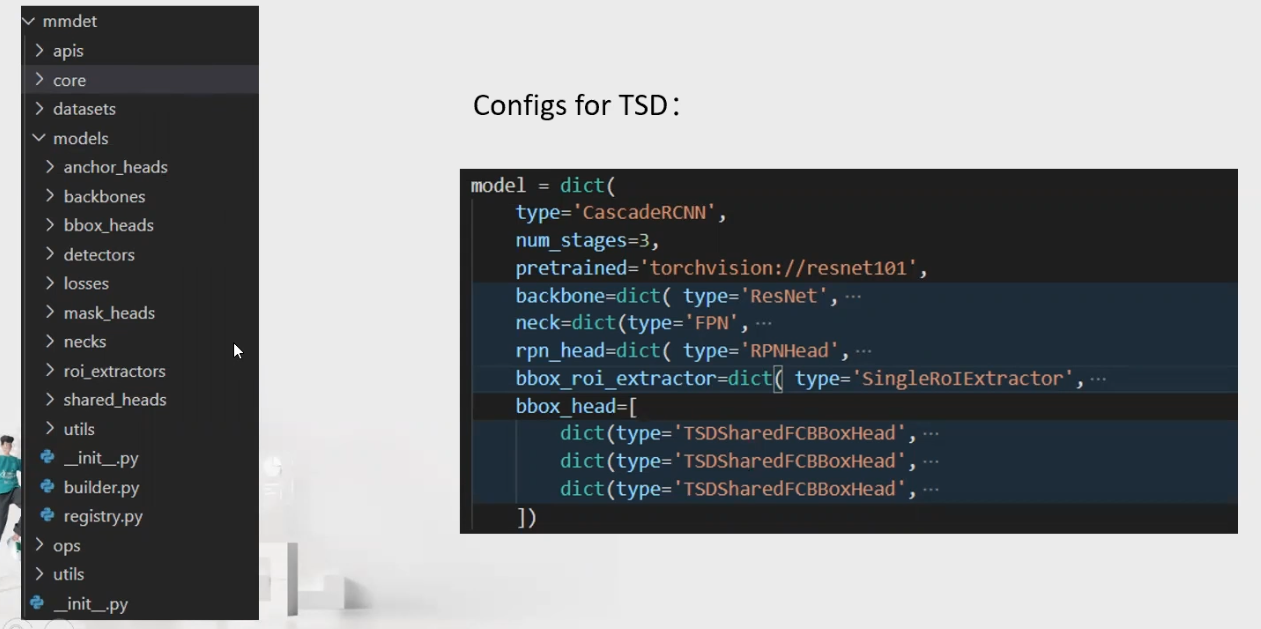
backbone:通常是FCN网络,用于提取功能图,例如ResNet。
neck:骨干和头部之间的部分,例如FPN,ASPP。
head:用于特定任务的部分,例如bbox预测和mask预测。
roi extractor:用于从 feature maps中提取feature的部分,例如RoI Align。
官方使用上述组件编写了一些通用的检测管道,例如“SingleStageDetector”和“ TwoStageDetector”。
2. Mmdetection如何从config构建模块
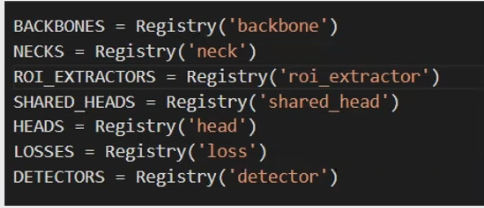
·模型: mmdet中每个模块按backbone, neck, roi_extractor, shared_head, head, loss和detector划分,使用装饰器register。
例如:
@ROI_EXTRACTORS.register_module
class singleRoIExtractor(nn. Module):
因此在构建model的时候,根据config中各个模块的type和参数,递归地调用各个模块,构建模型即可。
obj_cls = registry.get(obj_type)
在 config/_base_中存在4中基本的组件类型,分别为:dataset(数据集), model(模型), schedule(学习率调整的粗略),default_runtime(默认运行时设置)。使用Faster R-CNN,Mask R-CNN,Cascade R-CNN,RPN,SSD中的一个可以轻松构造许多方法。来自__base__中的组件称为promitive.
对于同一文件夹下的所有配置,建议仅具有一个 *原始(promitive)配置。所有其他配置应从原始(promitive)*配置继承。这样,继承级别的最大值为3。
便于理解,构建模型推荐从现有的方法中继承。
3. Mmdetection如何train/test
·Mmdet使用mmcv库的runner管理训练流程:See apis/train.py
·关键train代码:
·detector的成员函数forward_train为训练时前传损失计算函数
·关键inference代码:
· Detector的成员函数simple_test, aug_test( test with augmentation)
4. Two-stage detector
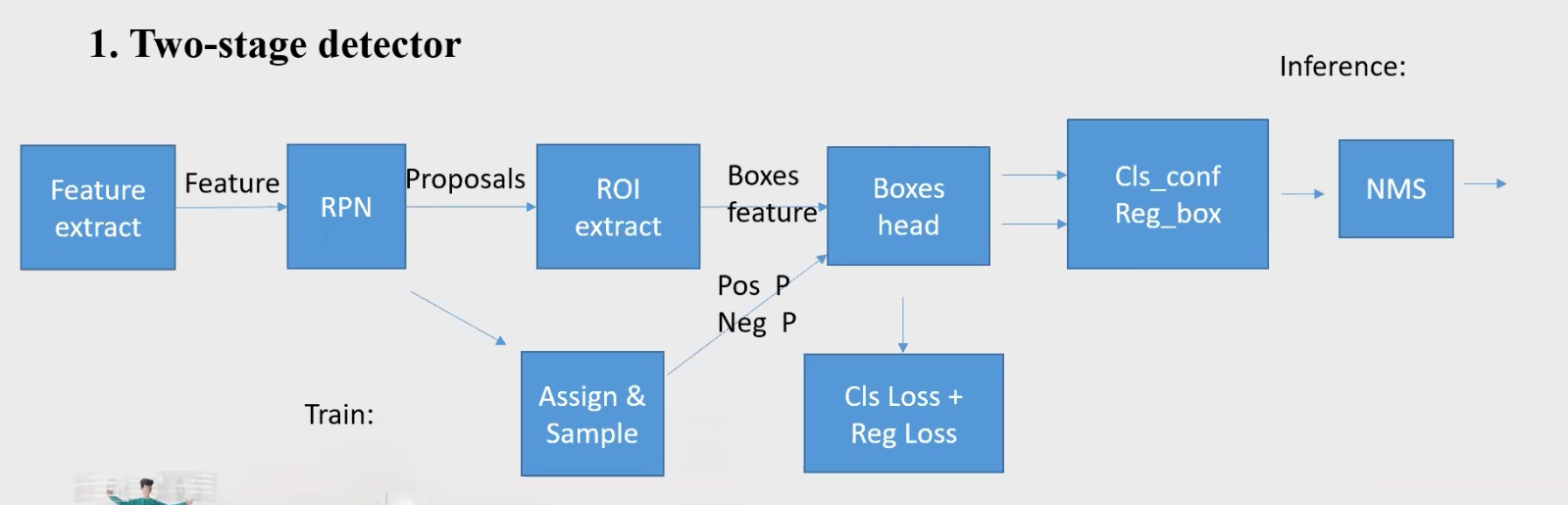
TwoStage: BackBone + Neck + DenseHead + RoIHead(proposals需送入RoIHead进行roiAlign,然后进行检测)
Two-stage 是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。
对于Two-stage的目标检测网络,主要通过一个卷积神经网络来完成目标检测过程,其提取的是CNN卷积特征,在训练网络时,其主要训练两个部分,第一步是训练RPN网络,第二步是训练目标区域检测的网络。网络的准确度高、速度相对One-stage慢。
第一,one-stage算法从网络结构上看只是一个多分类的rpn网络,相当于faster rcnn的第一阶段。其预测结果是从feature map中anchor对应的特征中预测得到的,而two-stage会对上述结果再进行roi pooling之后进一步精细化,因此更为精准。比如,一个anchor有可能只覆盖了一个目标的50%,但却作为完全的正样本,因此其预测肯定是有误差的。
第二,one-stage算法对小目标检测效果较差,如果所有的anchor都没有覆盖到这个目标,那么这个目标就会漏检。如果一个比较大的anchor覆盖了这个目标,那么较大的感受野会弱化目标的真实特征,得分也不会高。two-stage算法中的roi pooling会对目标做resize, 小目标的特征被放大,其特征轮廓也更为清晰,因此检测也更为准确。
5.TSDSharedFCBBoxHead
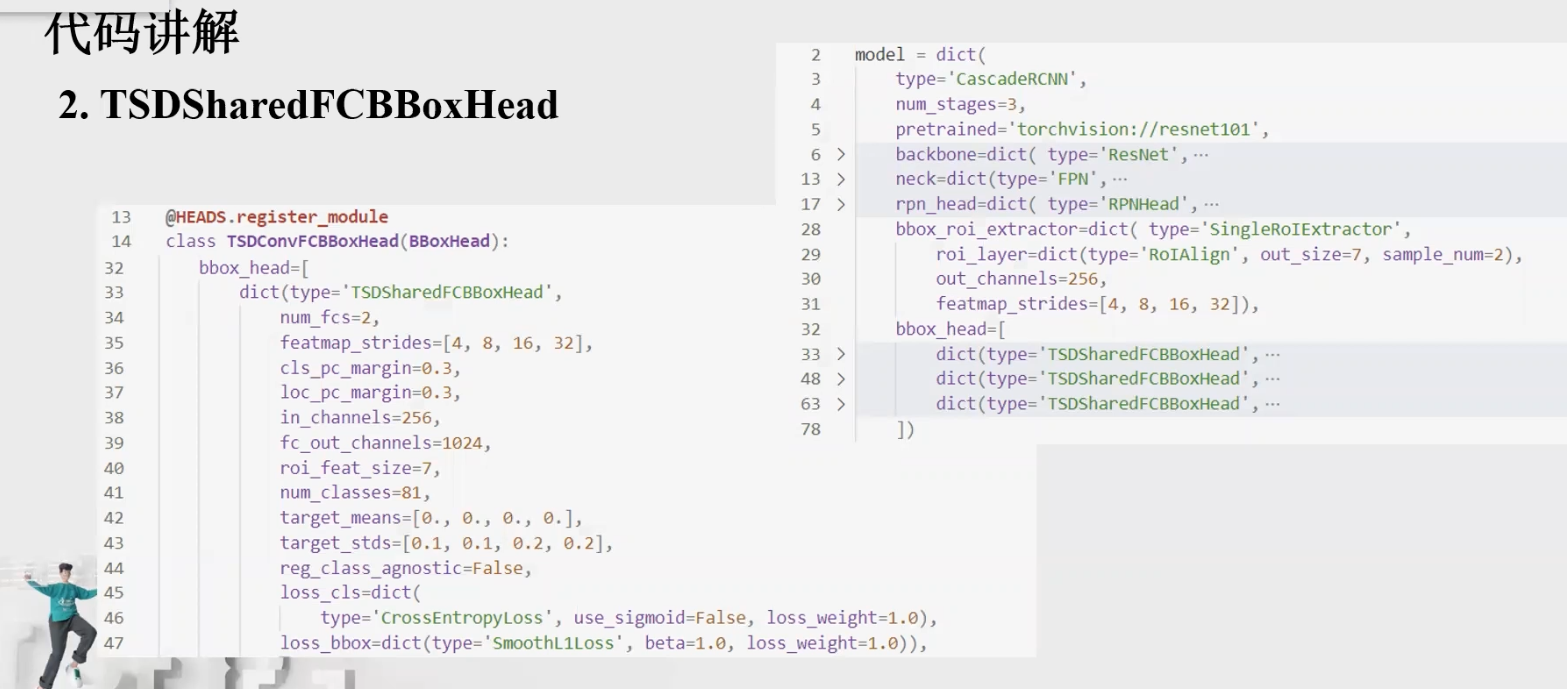

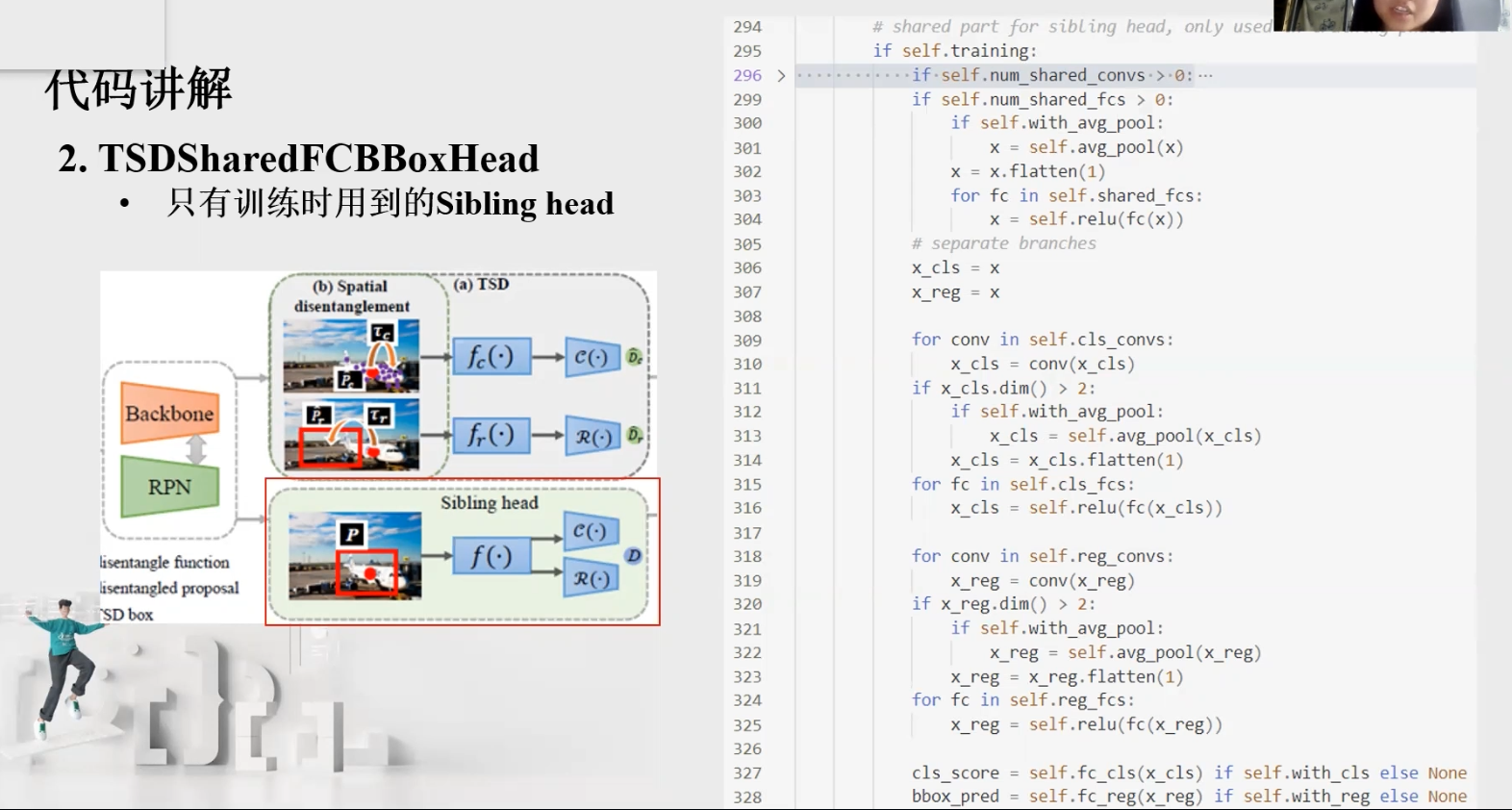
在使用mmdetection对模型进行调优的过程中总会遇到很多参数的问题,不知道参数在代码中是什么作用,会对训练产生怎样的影响。
在实验中发现,分类任务更关注语义信息丰富的地方,而回归任务比较关注物体的边界处。在这样的一种潜在的性质下,传统的 faster RCNN 对于分类任务和回归任务共享同一个 proposal 和特征提取器(sibling head)就会出现一些内在的矛盾影响检测器的训练。
SharedFCBBoxHead这个类继承了ConvFCBBoxHead,ConvFCBBoxHead又继承了BBoxHead,BBoxHead继承了nn.Module。其中BBoxHead实现了一个最基础的roi head,只有两个fc层,分别做分类和回归:
ConvFCBBoxHead在上面的基础上多做了一件事,就是可能在roi出来的特征后不是直接做分类和回归,一般还会再接几层卷积或者全连接,从而增加网络的非线性和计算量,让性能更好。配置文件里面我们看到有个键值对是num_fcs=2,就是指定了有两个共享的fc,没有指定conv,那么就没有额外的共享卷积了。也没有指定分类分支和回归分支需要额外的层。
总结:
TSD算子,通过学习任务感知的空间解耦来减轻 sibling head 中存在的固有冲突。特别是,TSD从共享 proposal 中衍生出两个独立的 proposals,并分别学习用于分类和定位的特征。此外,我们提出了一个递进约束来进一步提升TSD的效果,从而提供额外的性能收益。没有附加功能,这个简单的设计可以很容易地将COCO和大型OpenImage上的大多数主骨架和模型提升3% ~ 5%,这是2019年OpenImage挑战的第一个解决方案中的核心模型。
该论文从一个新的角度解决分类和回归分支的内在冲突问题,方法的创新性挺好的,通过对proposal特征的重采样或特征变换,解耦分类和回归任务,使得新的proposal更关注于与task-specific的特征。分类分支和回归分支的解耦依然是目标检测任务中非常重要的问题,值得我们更多的思考学习。
上述算法之所以可以实现,首先需要感谢华为云ModelArts强大的硬件支持,ModelArts是面向开发者的一站式AI开发平台,为机器学习与深度学习提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。最后,还要感谢华为云AI论文精读会,提供了这样的机会可以让计算机视觉、自然语言处理等领域的学者,特别是学生有机会和条件去学习优秀的论文,帮助自己成长,提高自己的学科专业知识和研究能力。



查看具体算法模型:
华为云AI论文精读会2021·论文算法实战赛报名地址:https://competition.huaweicloud.cn/information/1000041393/introduction
注:本文整理自【内容共创系列】之目标检测算法TSD解耦分类与回归
查看活动详情:https://bbs.huaweicloud.cn/blogs/298594

- 点赞
- 收藏
- 关注作者
评论(0)