MV3D-Net、AVOD-Ne用于自动驾驶的多视图3D目标检测网络 丨【百变AI秀】

前言
MV3D-Net 融合了视觉图像和激光雷达点云信息;输入数据有三种,分别是点云俯视图、点云前视图和RGB图像。通过特征提取、特征整合和特征融合,最终得到类别标签、3D边界框。这样的设计既能减少计算量,又保留了主要的特征信息。
MV3D-Net 开源代码:https://github.com/bostondiditeam/MV3D
MV3D-Net 论文地址:Multi-View 3D Object Detection Network for Autonomous Driving
AVOD-Net算是MV3D-Net的加强版,它也融合了视觉图像和激光雷达点云信息。但它去掉了激光点云的前视图输入、去掉了俯视图中的强度信息;输入数据有二种,分别是点云俯视图和RGB图像。AVOD-Net使用FPN来提取特征,同时添加边界框的几何约束,整体模型效果有提升。
AVOD-Net 开源代码:https://github.com/kujason/avod
AVOD-Net 论文地址:Joint 3D Proposal Generation and Object Detection from View Aggregation
本文思路是先介绍MV3D-Net,再介绍AVOD-Net;在理解MV3D-Net的基础上,去看AVOD-Net做出了哪些改变和对应效果如何。
一、MV3D-Net篇
1.1、框架了解
先看下总体网络结构:(可以点击图片放大查看)
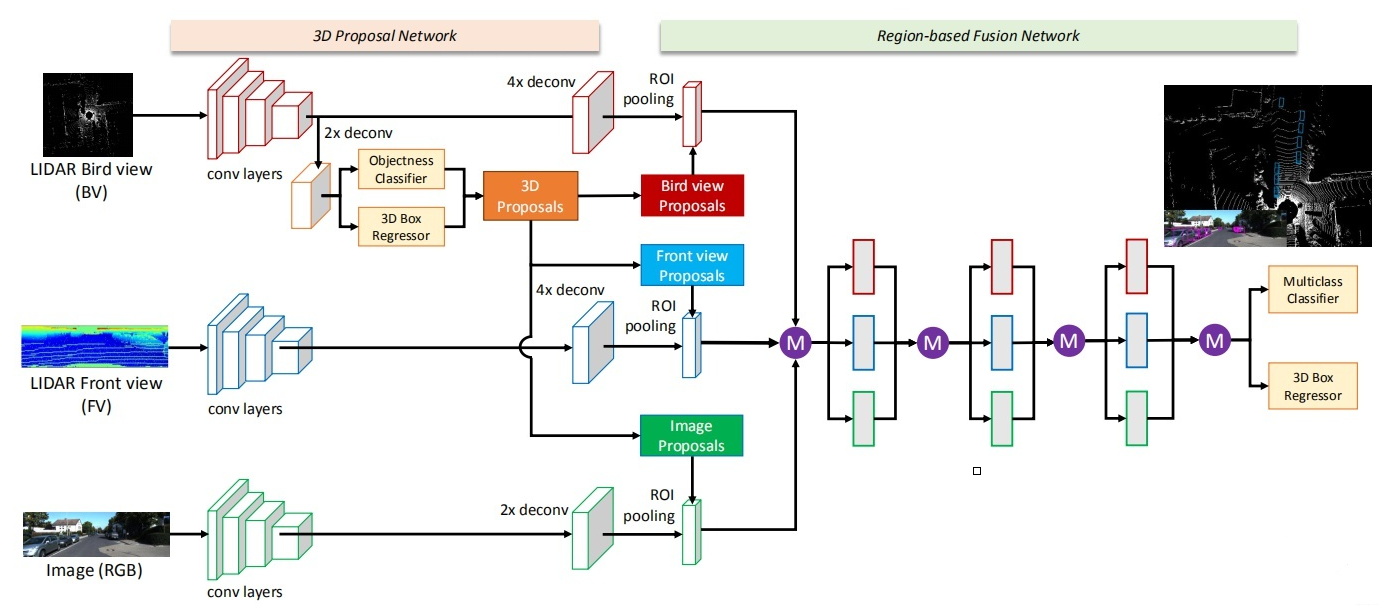
上图中的紫色圆圈中M是表示 :基于元素的均值。
输入的数据:有三种,分别是点云俯视图、点云前视图和二维RGB图像。“点云投影”,其实并非简单地把三维压成二维,而是提取了高程、密度、光强等特征,分别作为像素值,得到的二维投影图片。
输出数据:类别标签、3D边界框。
1.1.1 网络的主体部分

![]()
思路流程:
1)提取特征
- a. 提取点云俯视图特征
- b. 提取点云前视图特征
- c. 提取图像特征
2)从点云俯视图特征中计算ROI候选区域
3)把候选区域分别与提取到的点云俯视图特征、点云前视图特征和图像特征进行整合
- 先把俯视图候选区域投影到前视图和图像中
- 再经过ROI pooling整合成同一维度
1.1.2 网络的融合部分
这部分网络主要是:把整合后的数据进行融合。下图中的紫色圆圈中M是表示 :基于元素的均值。

最终得到类别标签、3D边界框。
1.2、MV3D的点云处理
MV3D将点云和图片数据映射到三个维度进行融合,从而获得更准确的定位和检测的结果。这三个维度分别为点云的俯视图、点云的前视图以及图片。

1.2.1 提取点云俯视图
点云俯视图由高度、强度、密度组成;作者将点云数据投影到分辨率为0.1的二维网格中。
高度图的获取方式为:将每个网格中所有点高度的最大值记做高度特征。为了编码更多的高度特征,将点云被分为M块,每一个块都计算相应的高度图,从而获得了M个高度图。
强度图的获取方式为:每个单元格中有最大高度的点的映射值。
密度图的获取方式为:统计每个单元中点云的个数,并且按照公式:
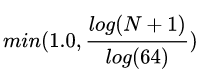
其中N为单元格中的点的数目。强度和密度特征计算的是整个点云,而高度特征是计算M切片,所以,总的俯视图被编码为(M + 2)个通道的特征。
1.2.2 提取点云前视图
由于激光点云非常稀疏的时候,投影到2D图上也会非常稀疏。相反,作者将它投影到一个圆柱面生成一个稠密的前视图。 假设3D坐标为:

那么前视图坐标:
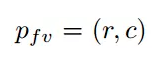
可以通过如下式子计算
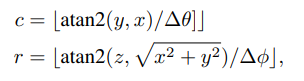
1.3、MV3D的图像处理
采用经典的VGG-16来提取图像特征,下图是VGG-16的网络结构,这里就不过多说明了。

![]()
1.4、俯视图计算候选区域
物体投射到俯视图时,保持了物体的物理尺寸,从而具有较小的尺寸方差,这在前视图/图像平面的情况下不具备的。在俯视图中,物体占据不同的空间,从而避免遮挡问题。
在道路场景中,由于目标通常位于地面平面上,并在垂直位置的方差较小,可以为获得准确的3Dbounding box提供良好基础。候选区域网络是RPN,这里简单介绍一下它的原理。
RPN网络的任务是找到proposals。输入:feature map。输出:proposal。
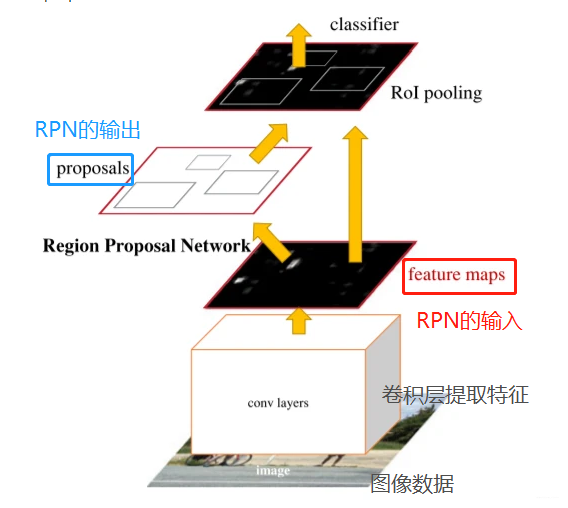
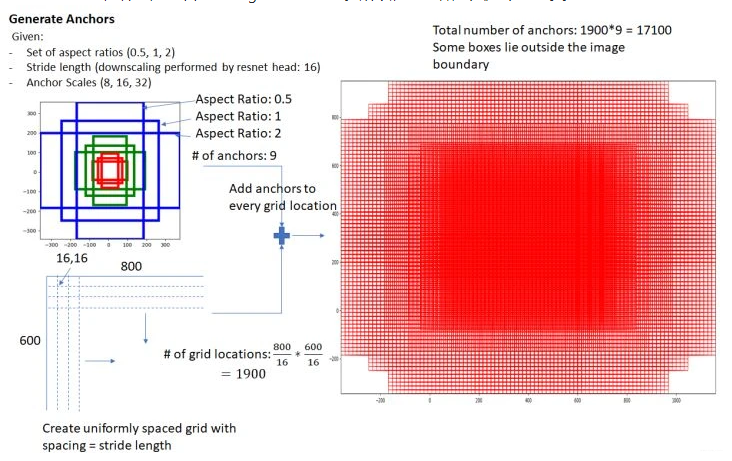
RPN总体流程:生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals。
1.4.1、softmax判定positive与negative
在feature map上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,RPN做的只是个二分类!
![]()
1.4.2、对proposals进行bounding box regression
图中红框为positive anchors,绿框为真实框GT。anchor和GT的梯度可以有dx, dy, dw, dh四个变换表示,bounding box regression通过线性回归学习到这个四个梯度,使anchor不断逼近GT,从而获得更精确的proposal。

1.5、特征整合
把候选区域分别与提取的特征进行整合。
特征整合流程:
- a. 把俯视图候选区域投影到前视图和图像中
- b. 经过ROI pooling整合成同一维度

![]()
1.6、特征融合
有了整合后的数据,需要对特征进行融合,最终得到类别标签、3D边界框。
作者介绍了三种不同的融合方式,分别为
- a、Early Fusion 早期融合
- b、Late Fusion 后期融合
- c、Deep Fusion 深度融合。
各自的结构如下图所示。

上图中的紫色圆圈中M是表示 :基于元素的均值。C是表示:串接。
最终选择了Deep Fusion 深度融合。融合的特征用作:分类任务(人/车/...)、更精细化的3D Box回归(包含对物体朝向的估计)。
1.7、模型效果
和其他模型对比的数据:

![]()

![]()
检测效果:

![]()
1.8、模型代码
代码地址:
作者使用KITTI提供的原始数据,点击

上图是用于原型制作的数据集 。
我们使用了[同步+校正数据] + [校准](校准矩阵)+ [轨迹]()
所以输入数据结构是这样的:
![]()
运行 src/data.py 后,我们获得了 MV3D 网络所需的输入。它保存在kitti中。

上图是激光雷达俯视图(data.py后)

上图是将 3D 边界框投影回相机图像中。
二、AVOD-Net篇
2.1、框架了解
先看下总体网络结构:(可以点击图片放大查看)

输入的数据:有二种,分别是点云俯视图和二维RGB图像。输出数据:类别标签、3D边界框。
相对于MV3D-Net的改进措施:
- 1)去掉了激光点云的前视图输入。
- 2)在俯视图中去掉了强度信息。
去掉这两个信息仍然能取得号的效果,就说明俯视图和图像信息已经能够完整诠释三维环境了。
2.2、提取特征
先看一下AVOD-Net如何提取特征的。

它主要提取出二部分数据,分别是图像特征、点云俯视图特征,其中图像+点云俯视图融合特征,在数据整合起到作用。后面将这二种特征进行融合。
它使用了全分辨率特征,所以为了在整合时降低维度,先进性了1X1的卷积。
AVOD使用的是FPN,FPN特征金字塔(Feature Pyramid Networks)是目前用于目标检测、语义分割、行为识别等方面比较重要的一个部分,对于提高模型性能具有较好的表现。
FPN包含了encoder和decoder,输入image,输出多尺度的feature map,如下图所示:

![]()
为什么要使用FPN呢?
不同大小的目标都经过了相同的降采样比例后会出现较大的语义代沟,最常见的表现就是小目标检测精度比较低。
FPN具有在不同尺度下有不同分辨率的特点,不同大小的目标都可以在相应的尺度下拥有合适的特征表示;通过融合多尺度信息,在不同尺度下对不同大小的目标进行预测,从而很好地提升了模型的性能。
FPN可以在保证特征图相对于输入是全分辨率的,而且还能结合底层细节信息和高层语义信息,因此能显著提高物体特别是小物体的检测效果。对比:MV3D-Net 是使用的VGG16做特征提取。
2.3、数据整合
再看看数据整合。

AVOD使用的是裁剪和调整(crop and resize)。
2.4、边界框的几何约束
AVOD在3D Bounding Box的编码上添加了几何约束。MV3D, Axis Aligned, AVOD三种不同的3D Bounding Box编码方式如下图所示,

- AVOD利用一个底面以及高度约束了3D Bounding Box的几何形状,即要求其为一个长方体。
- MV3D只是给出了8个顶点,没有任何的几何约束关系。
此外,MV3D中8个顶点需要一个24维(3x8)的向量表示,而AVOD只需要一个10维(2x4+1+1)的向量即可,做到了很好的编码降维工作。
2.5、模型效果
与其他模型的对比:
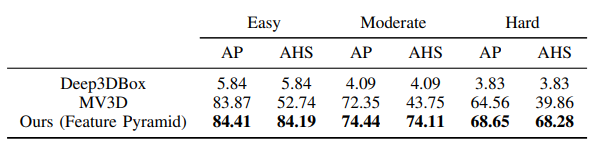
在上,AVOD目前(2018.7.23)名列前茅,在精度和速度上都表现较好,与MV3D, , 对比的结果如下表所示。

![]()
模型预测效果:

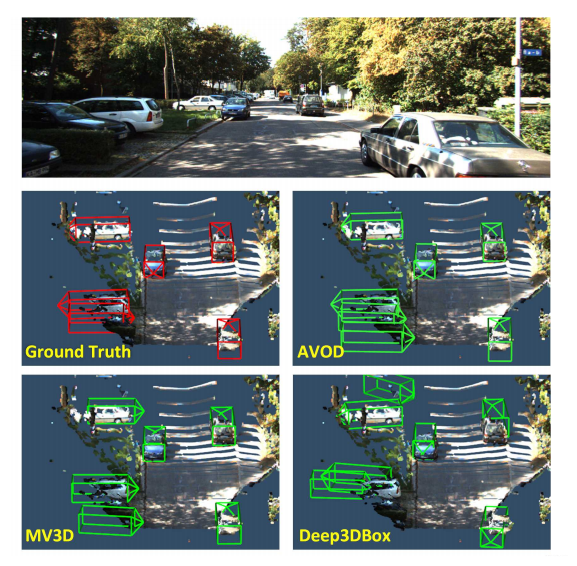
![]()
2.6、模型代码
AVOD-Net 开源代码:
作者代码的运行环境:
系统:Ubuntu 16.04
深度框架:TensorFlow1.3(GPU 版本)
其他依赖库:numpy>=1.13.0 、opencv-python 、pandas、pillow、protobuf==3.2.0 、scipy、sklearn 等。
数据集:在上进行训练。
【百变AI秀】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/296704
本文只供大家参考学习,谢谢。

- 点赞
- 收藏
- 关注作者
评论(0)