华为海外女科学家为您揭秘:GaussDB(for MySQL)云栈垂直集成的力量有多大?

作者:吕漫漪 华为瑞典研究所数据库Lab首席科学家
如今云计算越来越普及,云堆栈作为云计算的重要服务模式,其关键组件之一是事务数据库服务。在实际业务场景中,应用程序依赖于可扩展、高性能的托管数据库服务,以充分受益于云平台。而云数据库也需要高效利用底层云基础架构,以释放云规模运营的潜力。
华为云GaussDB(for MySQL)是华为基于新一代DFV(全称Data Function Virtualisation,数据功能虚拟化)分布式存储,采用计算存储分离架构,完全兼容MySQL的高性能企业级云原生分布式数据库,以全托管服务形式为互联网和企业客户提供专业服务。在本文中,我将解释常见的客户工作负载,以及我们如何利用华为云计算堆栈的独特能力来处理这种工作负载。
谁是云上的客户?他们的工作负载是什么?
在国内,人们通常认为只有互联网初创企业才会使用云平台,而MySQL由于在互联网公司中广受欢迎,得到众多国内企业的青睐。但实际上,企业多年前就已经开始拥抱云概念,并在不断深入发展中,这也是中国当前的趋势。MySQL作为世界上最流行的开源数据库,在所有行业和互联网公司中都被广泛采用。
那么,云数据库客户的典型工作负载是什么?我们观察到的两个特点是:1)数据量越来越大。从一开始就有几TB到几十TB的数据量,而且随着时间的推移,数据量会越来越大。2)简单的插入/删除/更新/点查和复杂的分析查询的混合。此外,偶尔也会有DDL操作。
目前客户面临一个很大挑战,即如何在数据量大的情况下提升数据库性能。客户希望在复杂查询的同时,保持核心事务工作负载的吞吐量。因为企业的业务逻辑性质,查询通常会比较复杂。幸运的是,MySQL 8.0添加了期待已久的分析行SQL支持,例如windowing function和递归CTE。对于非结构化数据,MySQL的JSON支持已经非常受欢迎。
GaussDB(for MySQL)架构概述
GaussDB(for MySQL)的架构构建在多租户共享的分布式存储系统之上,目前一个数据库的最大数据量为128TB,一个主节点用于读写负载,最多15个只读节点用于读负载。SQL引擎是一个经过深度修改的MySQL 8.0,因此在语法和语义方面与MySQL 100% 兼容。计算节点和存储之间用RDMA网络。
GaussDB(for MySQL)服务使用的存储系统是一种高可靠的跨AZ云存储。在公有云上,存储系统可以是一个有几十或数百个节点的大型群集,横向扩展能力比单租户线下方案高很多倍。SQL节点将redo log写到存储层,页面在存储层materialize,此设计显著减少了更新密集型工作负载的网络通信。属于单个数据库的页面以slice形式组织,slices分布在多个存储节点上,这个数据分布是就是分布式查询的基础。
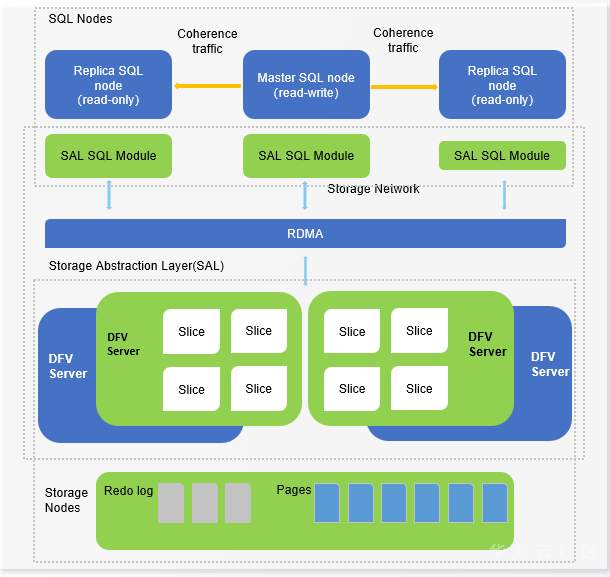
华为云GaussDB(for MySQL)架构图
华为独特优势:垂直集成
与传统的线下数据库不同,云数据库有垂直集成云栈中所有层的能力。华为作为在云栈各层领先的提供商,在云领域中有着独特的地位,有能力成为行业的领导者。
云栈中最接近数据库的是存储,线下纯软数据库需要与通用型存储以及标准文件系统配合使用,在垂直集成方面,几乎没有优化空间。但在云上,存储和数据库的集成能发挥更大的作用,因为云存储在存储节点方面的可扩展性很强,并允许客户根据数据量和负载动态扩展。由于云存储是多租户之间共享,而且并非所有租户都会每时每刻有大型扫描,因此我们可以将部分查询处理卸载到存储层,以实现更高的资源利用率。
- 通过并行提高性能(并行查询:PQ)
提高性能的一个通用方法是并行,并行可以在多层上实现。MySQL 8.0的社区版本仅支持单线程查询执行,无法充分利用硬件提供的所有核来执行复杂查询。我们修改了MySQL执行器,允许使用多个线程并行执行单个查询。与线下解决方案不同的是,云基础架构允许我们在计算节点上利用它的垂直扩展的能力。最大的计算节点目前有64个核,这也代表了我们通过并行查询可以实现的最大并行力度。当大部分热数据可以放在buffer pool里时,此优化效果最好。并行查询将在另一篇文章中详细解释。
客户工作负载不仅包含DML,还包含DDL,例如索引创建、更改列的数据类型。虽然大多数DDL在MySQL中都是在线处理的,但有些操作可能会被阻塞,而且使用逻辑复制会扩大堵塞。GaussDB(for MySQL)使用物理复制,避免了这个问题。当表很大时,DDL操作可能需要数小时才能完成。为了支持我们在云上常见的数据量,优化DDL的必要性是显而易见的。我们已经有一种创新的方法来处理DDL,这种创新将在后面的文章中探讨。
另一个允许更高并行力度的层是存储层,因为存储系统可能有数百个节点和数千个核心。GaussDB(for MySQL)使用的这种云规模的分布式存储是我们提高查询性能的一个关键基础,结合并行查询,有可能实现查询性能提高100倍以上。
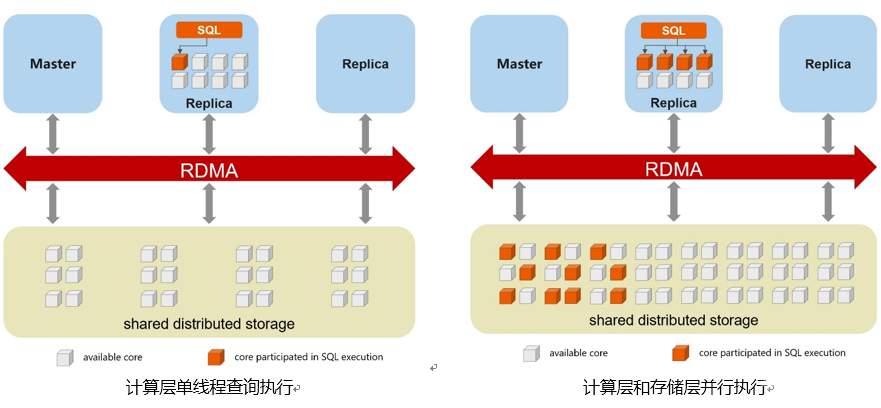
- 利用云存储提高查询性能 (算子下推:NDP)
GaussDB(for MySQL)中的数据以slice形式组织,分布在多个存储节点上。我们利用这个数据分布,把算子卸载到数据所在的存储节点上,利用当地可用的计算资源执行,无需将数据读到计算节点中。用数据库术语,我们将其称为近数据处理(NDP)或算子下推。其基本原理是:将查询处理的部分工作下推到数据所在的存储节点上,所下推的查询是数据密集型查询,例如全表扫描和索引扫描,投影和某些WHERE条件的过滤,以及聚合在存储层执行,仅将匹配行和列返回到计算节点,而不是完整的页。除了并行执行之外,因为提取到计算节点的数据量显著减少,这种方法还减少了网络IO。
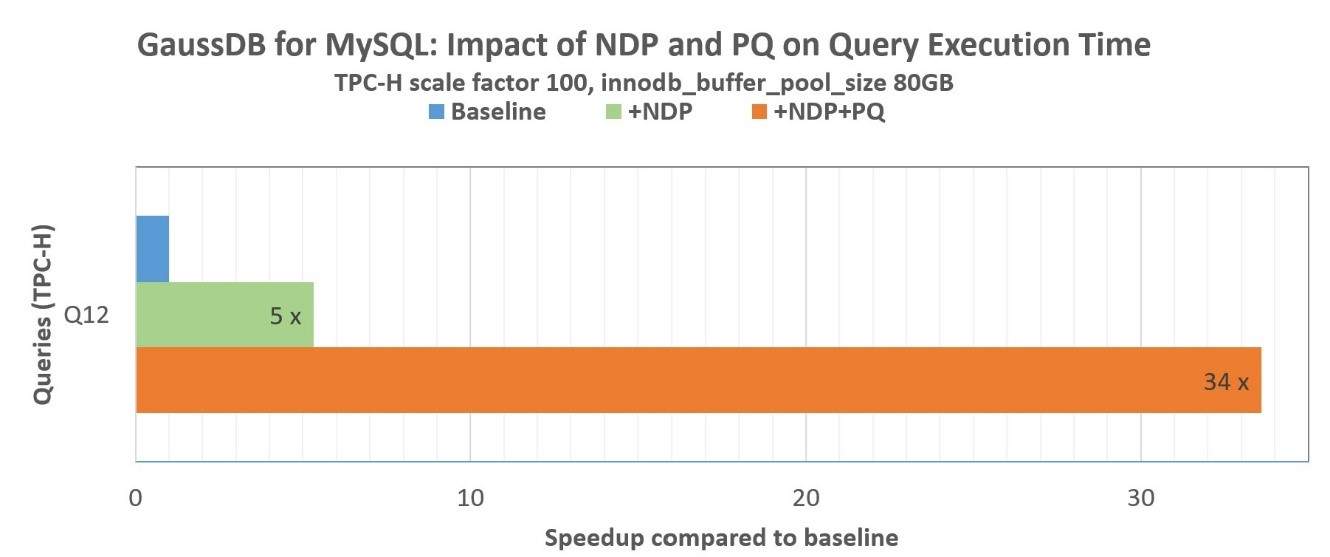
此外,NDP算子下推还允许充分利用缓存和存储介质的本地带宽,当查询需要扫描大量数据,且数据不在Innodb缓冲池中时,卸载到存储的效果最好。例如,下图显示了NDP算子下推和并行查询将TCP-H Q12的执行时间优化了34倍。另一篇文章会单独介绍NDP的技术细节,并提供全面的性能分析。
未来方向
GaussDB(for MySQL)的设计是为云而生,此架构具有极其强大和灵活的垂直集成能力,计算和存储资源解耦并且可以独立扩展,同时在功能上紧密集成,数据库操作可以在多层中执行。未来,数据库功能也可以卸载到网卡和其他云组件,而不限于计算节点和存储。
我们相信,云栈的深度集成是释放云数据库力量的关键,华为在实现这一目标方面处于独特的地位,正如GaussDB(for MySQL)所展示的那样,未来将引领云领域方向。
综上所述,华为云GaussDB(for MySQL)基于存算分离架构,通过并行查询PQ和算子下推NDP等先进技术,极大提升了数据库性能,实现了云栈垂直集成力量的最大化,让算力更快更猛。文章所述功能均已上线,欢迎大家前去华为云官网体验:https://www.huaweicloud.cn/product/gaussdb_mysql.html,也请继续关注我们,后续还有更多技术信息与大家分享!

华为将于2021年9月23-25日在上海世博中心&世博展览馆举办华为全联接2021,以“深耕数字化”为主题,汇聚业界思想领袖、商业精英、技术大咖、先锋企业、生态伙伴、应用服务商以及开发者等各方,探讨如何深入行业场景,把数字技术与行业知识深度结合,真正融入政企的主业务流程,解决核心业务问题,催生体验提升、效率提升以及模式创新;并发布场景化的产品与解决方案,分享客户伙伴的最新成果与实践,构筑开放共赢的健康生态。
了解更多信息,请访问官网www.huawei.cn/hc2021

- 点赞
- 收藏
- 关注作者
评论(0)