爬取游民福利,搞了一堆美女图片,代码奉上,多张福利【生长吧!Python】

点赞再看,养成习惯
因为想要爬取一些福利图片,花了差不多1个半小时的时间写了这个图片的爬虫,虽然还是有些问题,但是能爬下来图片就够了,下面开始聊一下,
展示成果:
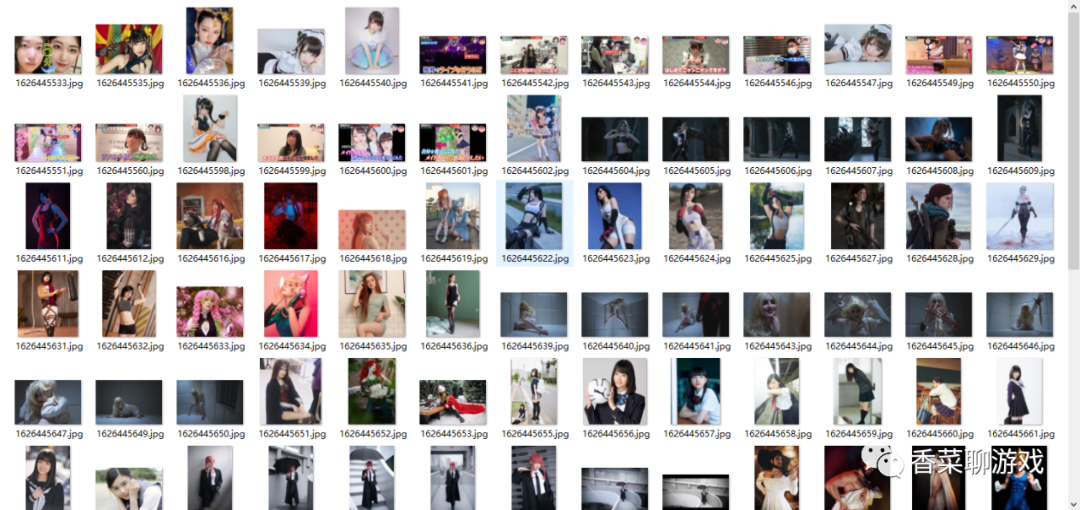
注:这只是一页的数据,网站总共有262 页哦
分析网站
目标网站:
游民星空的游民福利,基本上是一些美女图片,LSP喜欢,废话不多说,开始吧
Url 如下:https://www.gamersky.com/ent/xz/
打开网址,选择自己想要查看的,右键 -> 检查,就可以直接查看到对应的html 代码。
href 就是对应的链接
分析下url找个每个详情页的地址
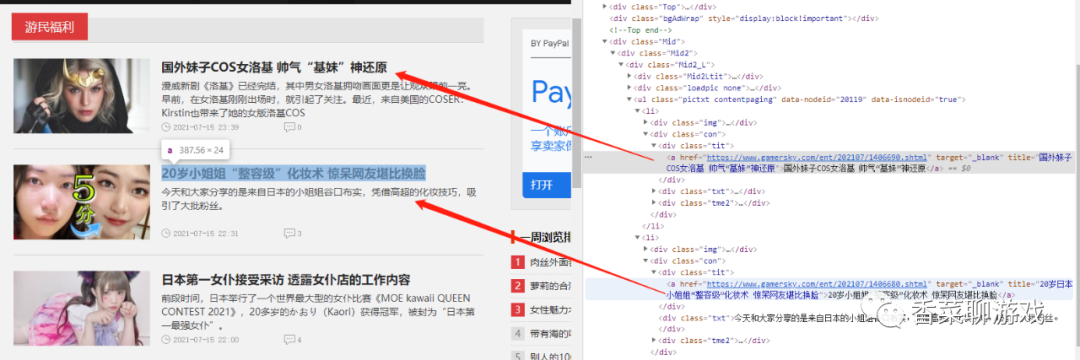
进入到详情页查看每个图片的url
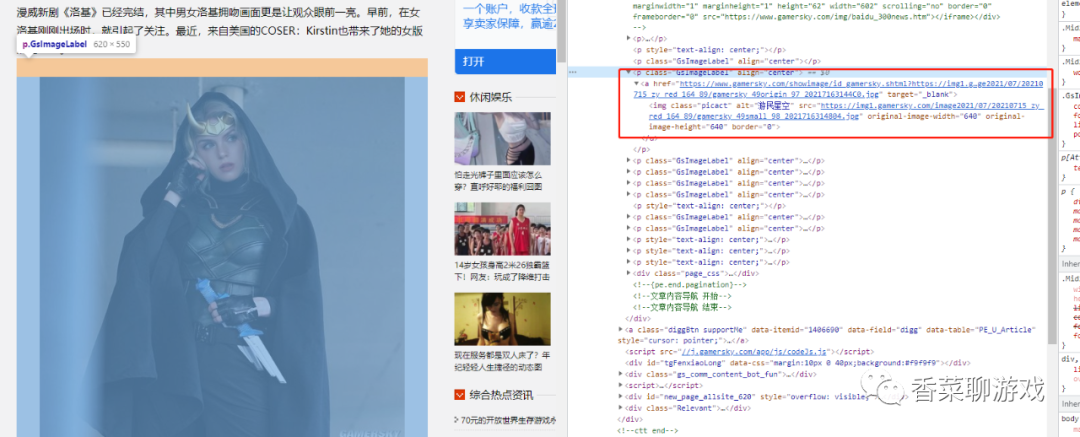
最终找到图片的详细地址
总结下:
-
对首页进行分析,找到详情页的url
-
对详情页进行分析,找到图片的url
-
打开url,找到图片
-
每个详情页的的第一页就是url ,第二页就是url_2.shtml
技术分析
之前没写过爬虫,所以技术上没有什么经验,但是爬虫领域python是最火的,所以果断放弃Java,选择python,有段时间没写python了,有点生疏了,管他呐,不会就查,开干!!!
选择的IDE 是pycharm ,因为习惯了idea
python 是选择了3.9的版本,随便下的
使用的库是BeautifulSoup 和 requests
直接上代码:
import time
import requests
from bs4 import BeautifulSoup
def get_content(url):
try:
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
response = requests.get(url, headers={'User-Agent': user_agent})
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
print(response.url)
print("爬取成功!")
return response.content
def save_img(img_src):
if img_src is None:
return
try:
print(img_src)
urlArr = img_src.split('?')
if len(urlArr) == 2:
url = urlArr[1]
else:
url = urlArr[0]
headers = {"User-Agent": 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'}
# 注意 verify 参数设置为 False ,不验证网站证书
requests.packages.urllib3.disable_warnings()
res = requests.get(url=url, headers=headers, verify=False)
data = res.content
filePath = "D:\\pic\\"+ str(int(time.time())) +".jpg"
with open(filePath, "wb+") as f:
f.write(data)
except Exception as e:
print(e)
def downloadImg(sigleArticle):
if sigleArticle is None:
return
# 实例化soup对象, 便于处理;
soup = BeautifulSoup(sigleArticle, 'html.parser')
imgList = soup.find_all('p',class_ ="GsImageLabel")
for img in imgList:
atag = img.find('a')
if atag:
save_img(atag['href'])
def getAllArticle(content):
# 实例化soup对象, 便于处理;
soup = BeautifulSoup(content, 'html.parser')
divObj = soup.find_all('div', class_="tit")
for item in divObj:
link = item.find('a')
if link:
articleUrl = link['href']
sigleArticle = get_content(articleUrl)
downloadImg(sigleArticle)
arr = articleUrl.split(".shtml")
for i in range(2,10):
url = arr[0]+"_" +str(i)+ ".shtml"
sigleArticle = get_content(url)
downloadImg(sigleArticle)
if __name__ == '__main__':
for i in range(2, 5):
print(i)
url = "https://www.gamersky.com/ent/xz/"
articleUrl = "https://www.gamersky.com/ent/202107/1406688.shtml"
content = get_content(url)
getAllArticle(content)
# singleArticle = get_content(articleUrl)
#
# downloadImg(singleArticle)注:图片下载可运行
遇到的困难
1.bs4 的安装
在pycharm 中无法安装,不知道什么情况,即使换了阿里的和清华的源依然不行,最后是在控制台安装
2.字符串的拆分
字符串的拆分的函数提示不好,不如Java方便
网站的字符串存在一些不规律,也没有深度探索
未解决的问题:
1.首页的翻页问题,现在只解决了首页的下载,还需要研究
2.程序的一些警告没有处理,直接无视了 requests.packages.urllib3.disable_warnings()
3.图片网址的前半部分是否需要拆分的问题,在浏览器中可以查看,但是爬取的时候似乎有点问题,没有深究
注意:爬虫虽好,可不要多用,会浪费网站的服务器性能
常规福利





赶紧点赞,分享
【生长吧!Python】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/278897

- 点赞
- 收藏
- 关注作者
评论(0)