【Datawhale7月打卡】李宏毅机器学习Task2笔记

回归定义
Regression 就是找到一个函数 function ,通过输入特征 x,输出一个数值 Scalar。
应用举例
- 股市预测(Stock market forecast)
- 输入:过去10年股票的变动、新闻咨询、公司并购咨询等
- 输出:预测股市明天的平均值
- 自动驾驶(Self-driving Car)
- 输入:无人车上的各个sensor的数据,例如路况、测出的车距等
- 输出:方向盘的角度
- 商品推荐(Recommendation)
- 输入:商品A的特性,商品B的特性
- 输出:购买商品B的可能性
- Pokemon精灵攻击力预测(Combat Power of a pokemon):
- 输入:进化前的CP值、物种(Bulbasaur)、血量(HP)、重量(Weight)、高度(Height)
- 输出:进化后的CP值
模型步骤
- step1:模型假设,选择模型框架(线性模型)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降)
Step 1:模型假设 - 线性模型
一元线性模型(单个特征)
以一个特征 为例,线性模型假设 y = b + ,所以 w 和 b 可以猜测很多模型:
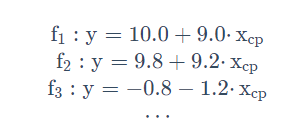
虽然可以做出很多假设,但在这个例子中,显然 f3 的假设是不合理的
多元线性模型(多个特征)
实际使用中,由于输出特征不止这一个,故可以假设一个线性模型: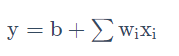

Step 2:模型评估 - 损失函数
【单个特征】: xcp
收集和查看训练数据

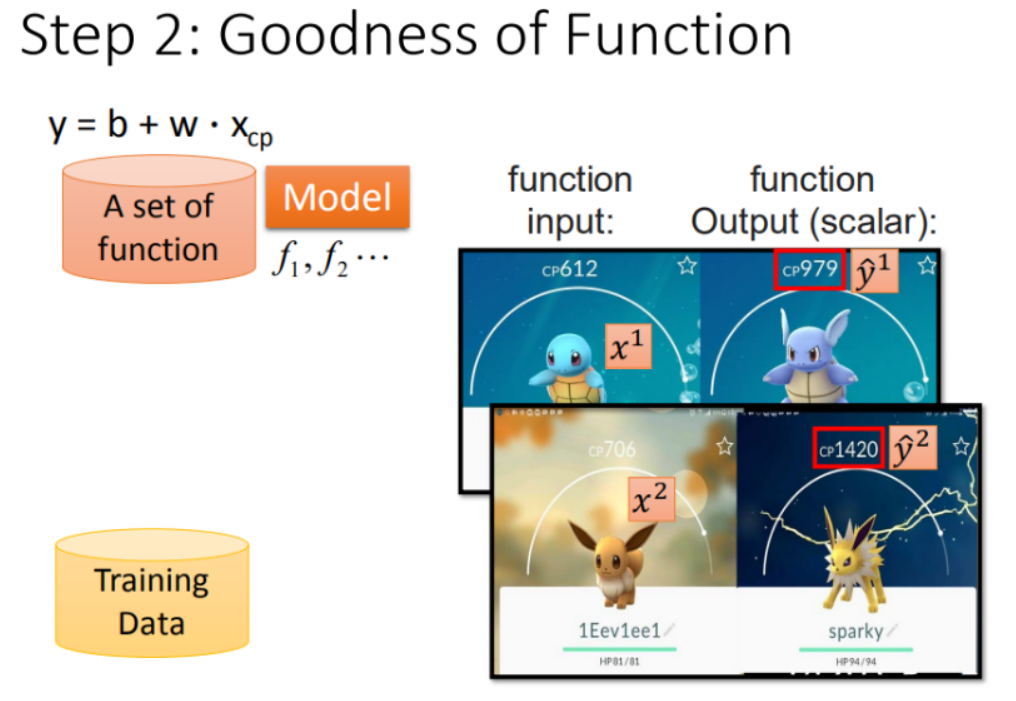
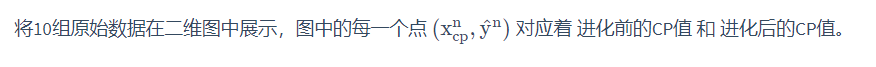
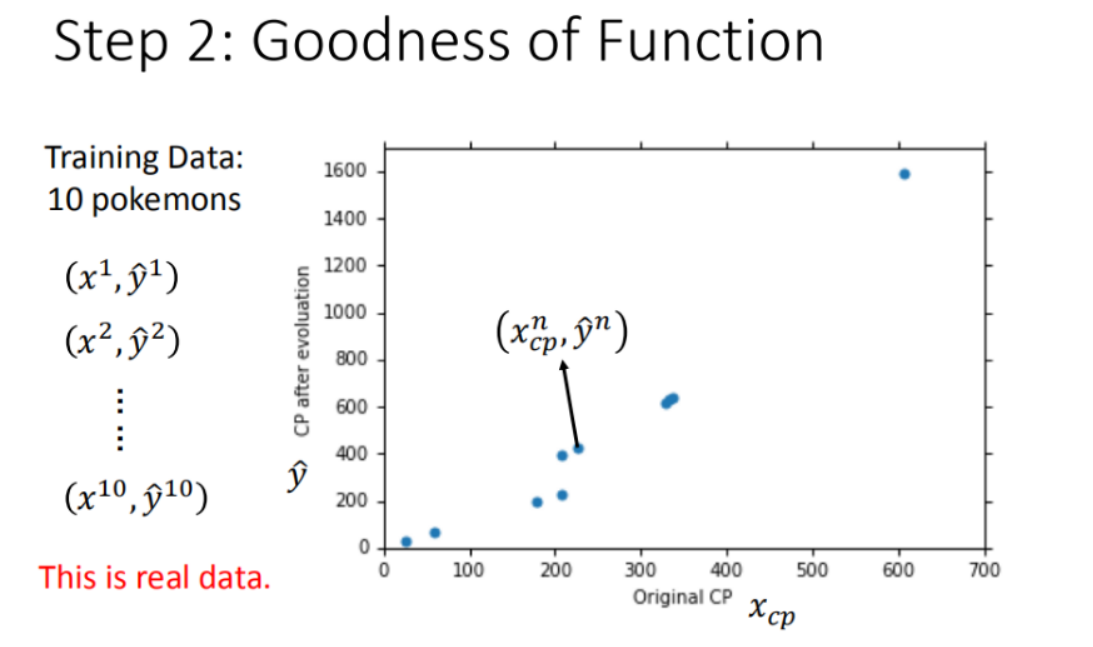
如何判断众多模型的好坏
通过求差,即通过损失函数来定义模型的好坏。统计十组原始数据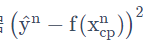 的和,和越小模型越好。
的和,和越小模型越好。

公式推导过程如下:
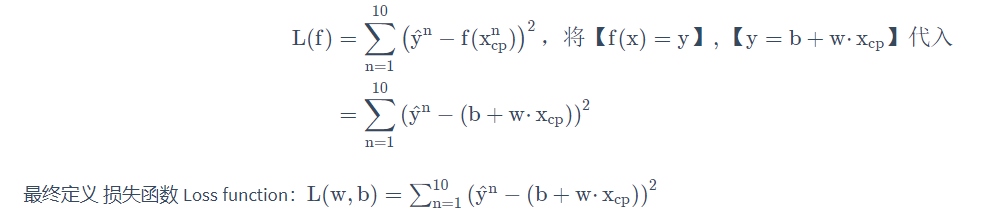
Step 3:最佳模型 - 梯度下降
定义:梯度下降法(英语:Gradient descent)是一个一阶最优化算法,通常也称为最陡下降法,但是不该与近似积分的最陡下降法(英语:Method of steepest descent)混淆。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。
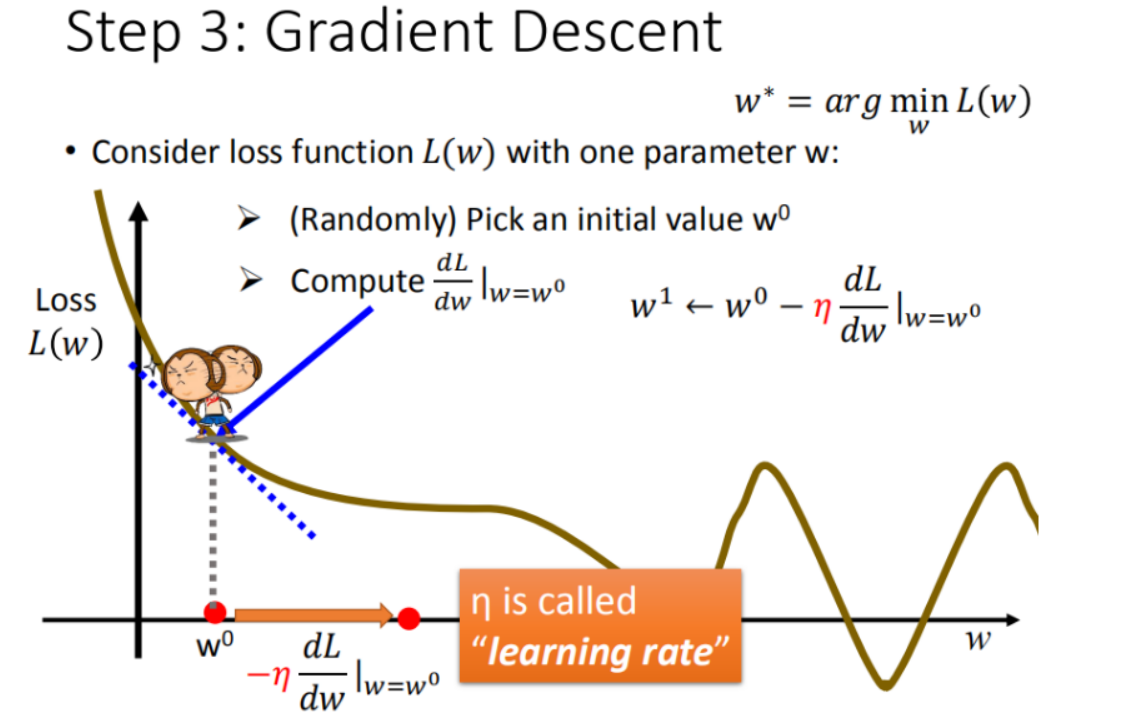

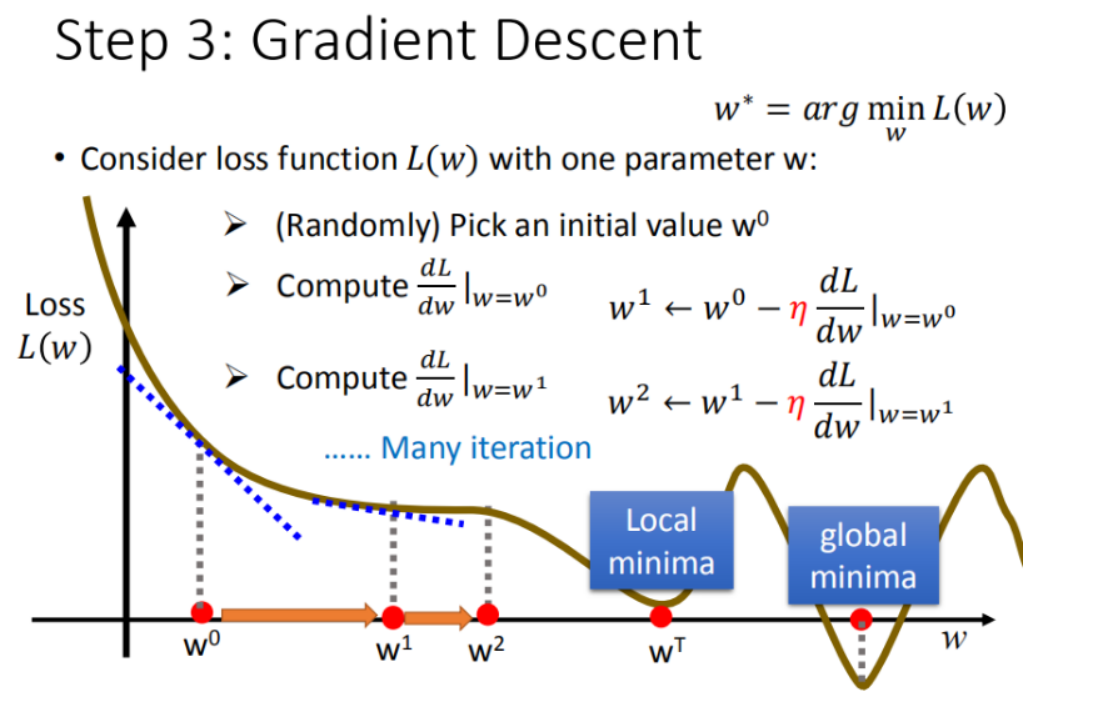
步骤1中,我们随机选取一个 ,如图8所示,我们有可能会找到当前的最小值,但并不是全局的最小值。
解释完单个模型参数w,引入2个模型参数 w 和 , 其实过程是类似的,需要做的是偏微分:

整理成一个更简洁的公式:
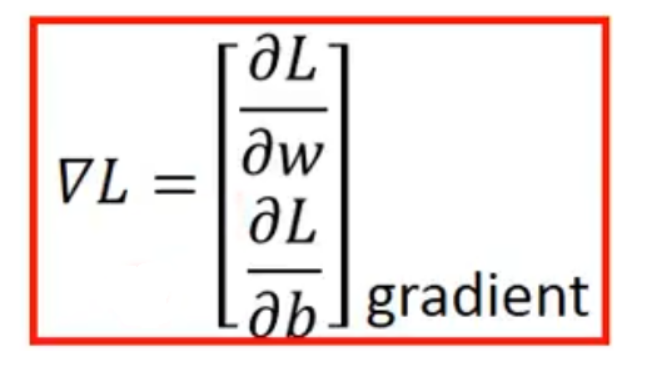
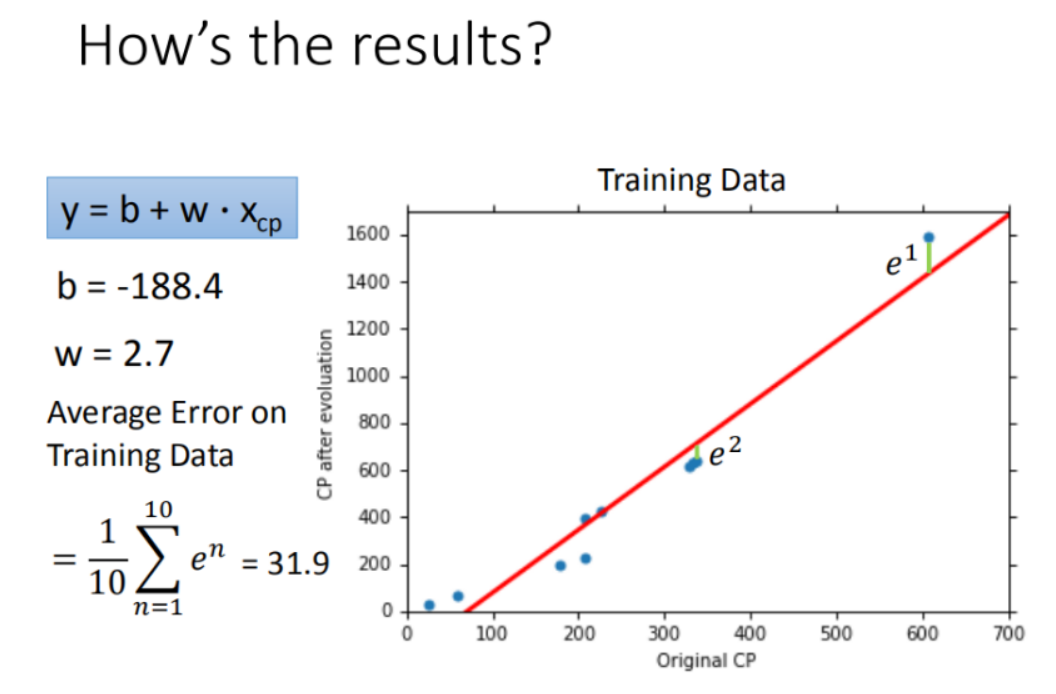
验证训练好的模型的好坏
使用训练集和测试集的平均误差来验证模型的好坏 我们使用将10组原始数据,训练集求得平均误差为31.9,如图所示:
然后再使用10组Pokemons测试模型,测试集求得平均误差为35.0 如图所示:
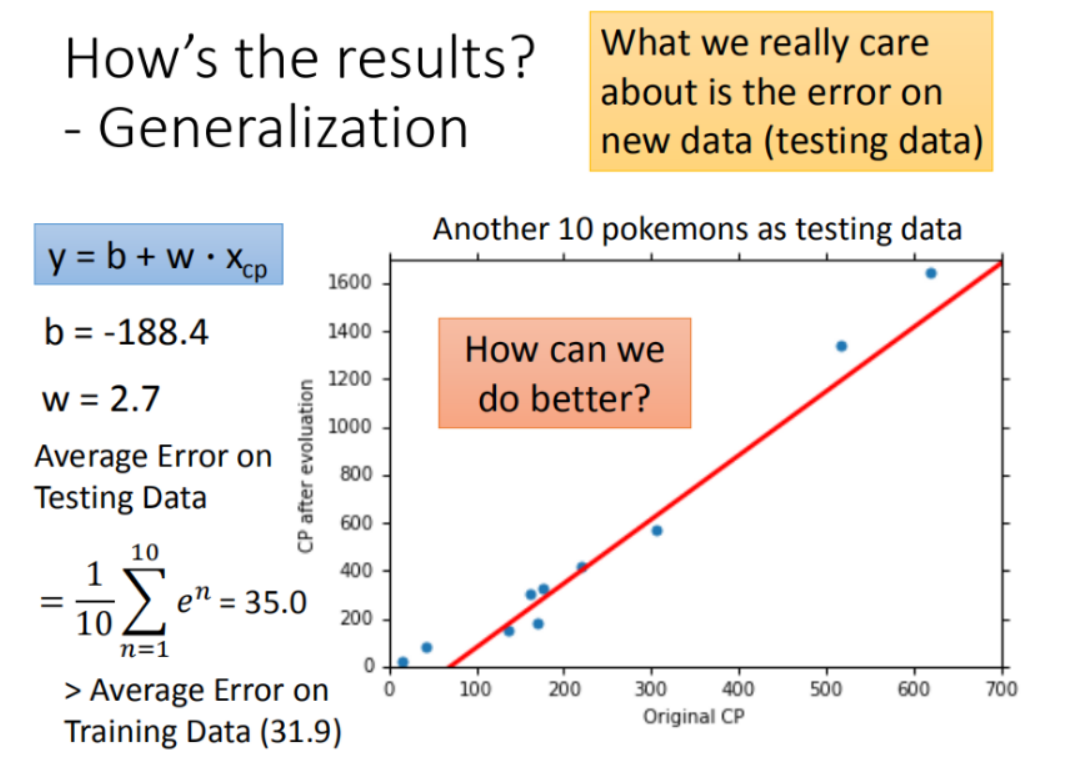
在此处,李宏毅老师介绍了可以通过一元N次线性模型来减小训练集和测试集的平均误差:
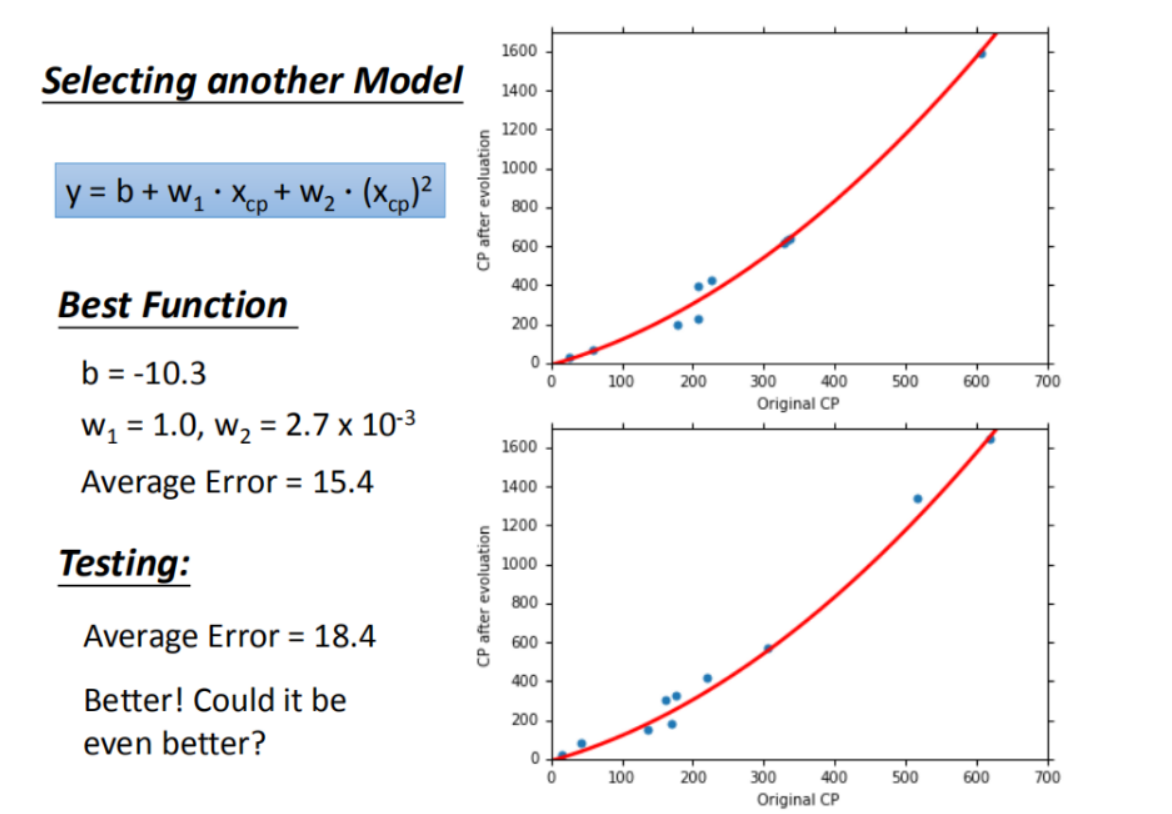
过拟合问题出现
在训练集表现较好,在测试集表现较差,这就是过拟合的出现。
步骤优化
Step1优化:2个输入的四个线性模型是合并到一个线性模型中
将 4个线性模型 合并到一个线性模型中
Step2优化:希望模型更强大表现更好(更多参数,更多输入)
Step3优化:加入正则化
更多特征,但是权重 w可能会使某些特征权值过高,仍旧导致过拟合,所以加入正则化
总结
本篇文章是对回归任务的一个概述,重点描述了线性模型这个基础模型,涉及到梯度下降、正则化等公式推导部分将在以后笔记中更新。

- 点赞
- 收藏
- 关注作者
评论(0)