华为云GaussDB专场直播第5期:SQL优化解读

1.前言
在关系型数据库中,优化器是数据库的核心组件之一,由于一些列因素都会影响语句的执行,优化器综合权衡各个因素,在众多的执行计划中选择认为是最佳的执行计划。随着大数据时代的到来,像电商、游戏、电信等行业都大规模的应用,单一数据库节点是难以应对数据规模的不断增长并确保性能的需要,业务面临“存不下、算得慢、算不准”的问题。而GaussDB采用了可横向扩展的分布式架构,可以很好满足大规模海量数据的存储和计算的需求,其通过目标SQL执行计划的CBO成本,从目标SQL的诸多执行计划中选取成本值最小的执行路径为其执行计划,各执行路径的成本值是根据目标SQL中涉及到的表、索引、列等相关对象的统计信息计算出来的,实际反应执行目标SQL所要消耗的I/O、CPU和网络资源的一个估计值。
- I/O资源:把表的数据从磁盘读入内存时所需代价
- CPU资源:处理内存中表的数据所需的代价
- 网络资源:需要DN间数据交互的分布式SQL,在实际执行时所需要的数据并不在本地DN中(需要从其他DN中取数据),便会将网络资源消耗折算成对等的I/O资源消耗再进行估算。
本文结合第5场直播内容从分布式并行执行框架、分布式执行计划等方面进行介绍。
2.分布式并行执行框架
2.1 执行器:PIPELINE模型
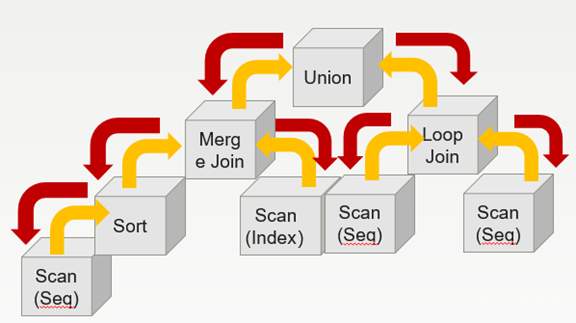
GaussDB的执行器特点是:按照查询计划树从底往上执行,基于火山模型执行,即每个节点执行返回一行记录给父节点。
火山模型的最大优点就是可以按需请求,每次只取出一条元组,在处理本条元组后,系统将会取出下一条满足条件的元组,直到取出所有满足条件的元组为止。从这种方式的运行机制可以看出,其每次执行时对于系统资源的需求都非常小。
2.2 高性能分布式查询引擎
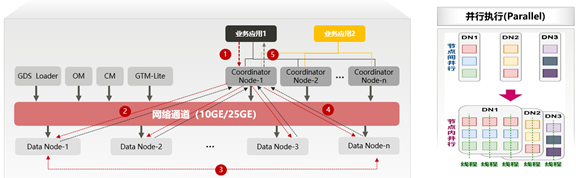
GaussDB充分利用当前多核特点,通过多线程并发执行,提高系统吞吐量。众所周知,在传统的分布式 MPP 数据库中,因数据的重分布,也就是数据shuffle的代价非常昂贵,从而限制了用户使用场景范围。
GaussDB能充分利用当前多核特点,采用并行执行机制,在SQL执行优化方面有多年的沉淀,并提供了三种stream流(广播流、聚合流和重分布流)来降低数据在DN节点间的流动,突破了传统分布式 MPP 数据库因为数据shuffle代价高昂带来的用户使用场景限制,即使是复杂的SQL、事务分析混合(HTAP)场景也能得到最佳执行。
GaussDB的大致执行过程:
- 业务应用下发SQL给Coordinator ,SQL可以包含对数据的CRUD操作;
- Coordinator利用数据库的优化器生成执行计划,每个DN会按照执行计划的要求去处理数据;
- 数据基于一致性Hash算法分布在每个DN,因此DN在处理数据的过程中,可能需要从其他DN获取数据,GaussDB提供三种stream流(广播流、聚合流和重分布流)实现数据在DN间的流动,使得join无需抽取到CN执行;
- DN将结果集返回给Coordinate进行汇总;
- Coordinator将汇总后的结果返回给业务应用。
3.分布式执行计划
CN根据表的分布列信息和关联列信息进行判定,SQL语句是否可以直接在各个DN上执行而且不需要数据交流,如果是,CN采用LIGHT_QUERY或FQS_QUERY流程,保持了事不关己的态度,你发给我什么我就下发什么,直接将整个query命令下发给DN执行,执行完成后直接输出;如果需要在各个DN之间进行数据交互,则会选择使用stream算子;如果发现无法使用stream算子时,就回到了原始的PGXC流程。
3.1 LIGHT_QUERY
- 场景:语句可以直接在一个DN执行(单shard语句,点查场景)。
- 原理:CN直接下发语句QPBE报文到对应DN,这样的做的好处是,执行效率高,线性扩展比好。
create table t1 ( col1 int, col2 varchar ) distribute by hash(col1);
create table t2 ( col1 int, col2 varchar ) distribute by hash(col1);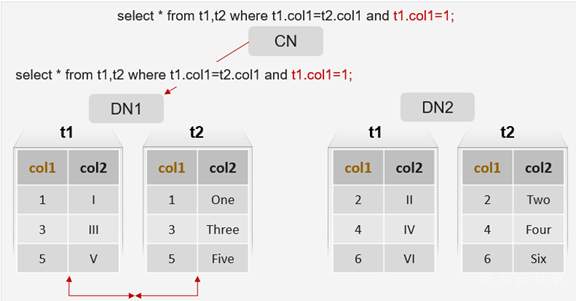
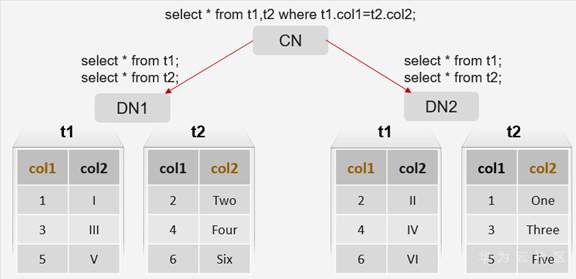
3.2 FQS_QUERY
- 场景:当语句可以完全下推到多个DN上执行,且DN之间不需要数据交互时。
- 原理:CN不通过优化器,直接生成RemoteQuery计划,走执行器逻辑下发到DN,各DN根据下推语句生成执行计划并进行执行,执行结果在CN上进行汇总。
create table t1 ( col1 int, col2 varchar ) distribute by hash(col1);
create table t2 ( col1 int, col2 varchar ) distribute by hash(col1);
LIGHT_QUERY和FQS_QUERY的最大异同点在于,虽然CN都是经过判定后直接把收到的query下发给DN进行处理,但是LIGHT_QUERY只涉及到单DN进行操作,而FQS_QUERY涉及到多个DN分别进行操作,它们都不会涉及到DN间的数据交互。
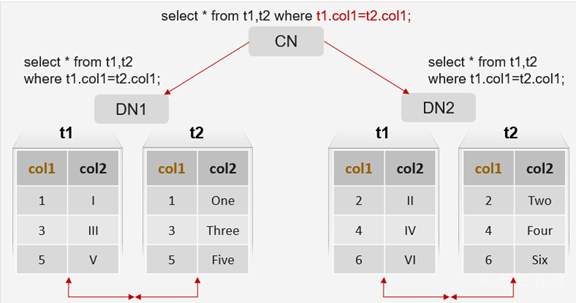
3.3 STREAM GATHER
- 场景:需要各DN之间进行数据交互。
- 原理:CN根据原语句通过优化器生成带stream算子的执行计划,下发给DN进行执行,DN执行过程中存在数据交互(stream节点),stream算子在DN之间建立连接进行数据交互,CN汇总执行结果并承担大部分计算。
create table t1 ( col1 int, col2 varchar ) distribute by hash(col1);
create table t2 ( col1 int, col2 varchar ) distribute by hash(col2);

3.4 STREAM REDISTRIBUTE
- 场景:需要各DN之间进行数据交互。
- 原理:CN根据原语句通过优化器生成带stream算子的执行计划,下发给DN进行执行,各DN执行过程中存在数据交互(stream节点),stream算子在DN之间建立连接进行数据交互,CN汇总执行结果并承担大部分计算。
create table t1 ( col1 int, col2 varchar ) distribute by hash(col1);
create table t2 ( col1 int, col2 varchar ) distribute by hash(col2);

3.5 STREAM BROADCAST
- 场景:需要各DN之间进行数据交互。
- 原理:CN根据原语句通过优化器生成带stream算子的执行计划,下发给DN进行执行,各DN执行过程中存在数据交互(stream节点),stream算子在DN之间建立连接进行数据交互,CN汇总执行结果并承担大部分计算。
create table t1 ( col1 int, col2 varchar ) distribute by hash(col1);
create table t2 ( col1 int, col2 varchar ) distribute by hash(col2);
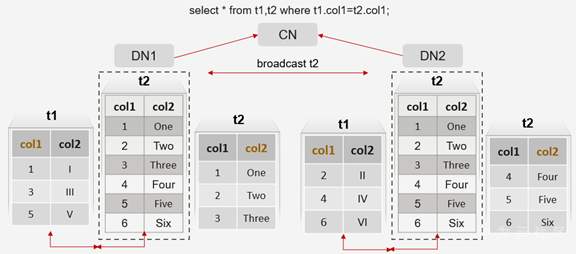
使用REDISTRIBUTE算子时,数据进行重分布可以充分利用多个节点的算力,而BROADCAST算子主要用于stream的子计划产生的数据量较少的情况,此时BROADCAST的代价较少。
3.6 PGXC
- 场景:不能满足前面处理方式的极端场景,性能非常差。
- 原理:CN通过优化器把原语句中的部分语句生成RemoteQuery计划,把每个RemoteQuery下发到DN,DN执行后把中间结果数据发送给CN,CN收集后进行剩余执行计划的执行计算,CN承担了大部分计算。
总结
综上所述,GaussDB作为自主研发的新一代金融级分布式关系型数据库,采用可横向扩展的分布式架构,通过SQL优化器生成分布式算子以及分布式执行计划,提供了三种stream流(广播流、聚合流和重分布流)来降低数据在DN节点间的流动;执行引擎是一个分布式并行执行框架,支持节点间并行和节点内并行能力,充分利用当前多核特点,通过并发执行,提高系统吞吐量,具备大数据下高性能查询能力。
Ps:更多精彩内容,请点击回播链接进行观看:https://bbs.huaweicloud.cn/live/cloud_live/202107061900.html

- 点赞
- 收藏
- 关注作者
评论(0)