[Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解 | 【生长吧!Python】

欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了数据库操作知识,包括MySQL安装、SQL语句和Python操作数据库知识,这将为后续网络爬虫存储至数据库奠定基础。本文详细介绍Selenium基础技术,涉及基础入门、元素定位、常用方法和属性、鼠标操作、键盘操作和导航控制。基础性文章,希望对您有所帮助。
下载地址:
前文赏析:
第一部分 基础语法
第二部分 网络爬虫
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解
Selenium是一款用于测试Web应用程序的经典工具,它直接运行在浏览器中,仿佛真正的用户在操作浏览器一样,主要用于网站自动化测试、网站模拟登陆、自动操作键盘和鼠标、测试浏览器兼容性、测试网站功能等,同时也可以用来制作简易的网络爬虫。本文主要介绍Selenium Python API技术,它以一种非常直观的方式来访问Selenium WebDriver的所有功能,包括定位元素、自动操作键盘鼠标、提交页面表单、抓取所需信息等。
Selenium是ThoughtWorks公司专门为Web应用程序编写的一个验收测试工具,它提供的API支持多种语言,包括Python、Java、C#等,本书主要介绍Python环境下的Selenium技术。Python语言提供了Selenium扩展包,它是使用Selenium WebDriver(网页驱动)来编写功能、验证测试的一个API接口。
通过Selenium Python API,读者能够以一种直观的方式来访问Selenium WebDriver的所有功能。Selenium Python支持多种浏览器,诸如Chrome、火狐、IE、360等浏览器,也支持PhantomJS特殊的无界面浏览器引擎。

Selenium WebDriver API接口提供了一种定位网页中元素(Locate Elements)的策略,本书将使用Selenium Python讲解网络数据爬取知识,本章主要介绍Selenium技术的基础知识,后面的章节结合实例讲解如何利用Selenium定位网页元素、自动爬取、设计爬虫等。
类似于BeautifulSoup技术,Selenium制作的爬虫也是先分析网页的HTML源码和DOM树结构,再通过其所提供的方法定位到所需信息的结点位置,并获取其文本内容。
读者可以访问PyPI网站来下载Selenium扩展包,例如图2所提供的selenium 3.4.3,对应的网址为:
- https://pypi.python.org/pypi/selenium
我们点击“Downloads”按钮下载该Selenium扩展包,解压下载的文件后,在解压目录下执行下面的命令进行安装Selenium包。
C:\selenium\selenium3.4.3> python3 setup.py install
PyPI全称是Python Package Index,是Python官方的第三方库的仓库,所有人都可以下载第三方库或上传自己开发的库到PyPI。

同时,作者更推荐大家使用pip工具来安装Selenium库,PyPI官方也推荐使用pip管理器来下载第三方库。Python3.6标准库中自带pip,Python2.x需要自己单独安装。前文介绍了pip工具的安装过程及基础用法。安装好pip工具后,直接调用命令即可安装Selenium:
- pip install selenium
调用命令“pip install selenium”安装Selenium包如图3所示。

安装过程中的会显示安装配置相关包的百分比,直到出现“Successfully installed selenium-2.47.1”提示,表示安装成功,如图4所示。

此时的Selenium包已经安装成功,接下来需要调用浏览器来进行定位或爬取信息,而使用浏览器的过程中需要安装浏览器驱动。作者推荐使用Firefox浏览器、Chrome浏览器或PhantomJS浏览器,下面将结合实例讲解三种浏览器驱动的配置过程。
Selenium需要安装浏览器驱动,才能调用浏览器进行自动爬取或自动化测试,常见的包括Chrome、Firefox、IE、PhantomJS等浏览器。表1是部分浏览器驱动下载页面。

注意:驱动下载解压后,将chromedriver.exe、geckodriver.exe、Iedriver.exe置于Python的安装目录下,例如Python的安装目录为“C:\python”,则将驱动文件放置于该文件夹下;然后将Python的安装目录添加到系统环境变量路径(Path)中,打开Python IDLE输入不同的代码来启动不同的浏览器。
- Firefox浏览器
加载火狐浏览器的核心代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com/')
输出结果如下图所示:

- chrome浏览器
加载谷歌览器的核心代码如下,其中驱动置于chrome浏览器目录下,如代码所示。
import os
from selenium import webdriver
chromedriver = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
browser.get('http://www.baidu.com/')
- IE浏览器
加载微软IE览器的核心代码如下:
from selenium import webdriver
browser = webdriver.Ie()
browser.get('http://www.baidu.com/')
PhantomJS是一个服务器端的 JavaScript API 的开源的浏览器引擎(WebKit)。它支持各种Web标准,包括DOM树分析、CSS选择器、JSON和SVG等。PhantomJS常用于页面自动化、网络监测、网页截屏以及无界面测试等。在官网http://phantomjs.org/下载PhantomJS解压后如图5所示。

调用时如果报错“Unable to start phantomjs with ghostdriver”,则需要设置PhantomJS的路径,或者配置到Scripts目录环境下。当Selenium安装成功并且PhantomJS下载配置好后,下面这代代码是调用方法。其中executable_path参数设置PhantomJS的路径。
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path="F:\phantomjs-1.9.1-windows\phantomjs.exe")
driver.get("http://www.baidu.com")
data = driver.title
print(data)
代码含义为:
- 首先导入Selenium.webdriver扩展包,它提供了webdriver实现方法。
- 然后创建driver实例,调用webdriver.PhantomJS方法配置路径。
- 通过driver.get(“http://www.baidu.com”) 代码打开百度网页,webdriver会等待网页元素加载完成之后才把控制权交回脚本。
- 最后获取文章标题(title)并赋值给data变量输出,其值为“百度一下,你就知道”。
运行结果如图6所示,Python3效果一样。

注意,webdriver中提供的save_sceenshot()函数可以对网页进行截图,代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
data = driver.title
driver.save_screenshot('baidu.png')

网页通常采用文档对象模型树结构进行存储,并且这些节点都是成对出现的,如“< html >”对应“</ html >”、“< table >”对应“</ table >”、“< div >”对应“</ div >”等。Selenium技术通过定位节点的特定属性,如class、id、name等,可以确定当前节点的位置,再获取相关网页的信息。
下面代码是定位百度搜索框并进行自动搜索,它作为我们的快速入门代码。
#-*- coding:utf-8 -*-
#By:Eastmount 2021-05-29
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#启动驱动
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
assert "百度" in driver.title
print(driver.title)
#查找元素并输入内容
elem = driver.find_element_by_name("wd")
elem.send_keys("数据分析")
elem.send_keys(Keys.RETURN)
#截图并退出
time.sleep(10)
driver.save_screenshot('baidu.png')
driver.close()
driver.quit()
运行结果如下图所示,调用Firefox浏览器并搜索“数据分析”关键词,最后对浏览的网页进行截图操作。所以,Selenium常用于自动化测试领域。

下面对这部分代码进行详细讲解。
- from selenium import webdriver
导入Selenium.webdriver模板,它提供了webdriver的实现方法,目前支持这些方法的浏览器有Firefox、Chrome、IE和Remote等。 - from selenium.webdriver.common.keys import Keys
导入Keys类,它提供了操作键盘的快捷键,如回车键、空格键、ctrl键等操作。 - driver = webdriver.Firefox()
创建Firefox webdriver实例,定义火狐浏览器(Firefox)驱动,其他浏览器如Chrome可能还需要设置驱动参数和配置路径。 - driver.get(“http://www.baidu.com”)
接下来通过driver.get()函数打开百度url网页,webdriver会等待网页元素加载完成之后才把控制权交回脚本。 - assert “百度” in driver.title
接下来使用断言(assert)判断文章的标题title是否包含了“百度”字段。对应爬取的标题是“百度一下,你就知道”,所以包含了“百度”,否则会出现断言报错。断言主要用于判断结果是否成功返回,从而更好地执行下一步定位操作。 - elem = driver.find_element_by_name(“wd”)
webdriver提供了很多形如“find_element_by_*”的方法来匹配要查找的元素。如利用name属性来查找的方法是find_element_by_name,这里通过该方法来定位百度输入框,即审查元素name为“wd”的节点。
图8是百度首页审查元素的反馈结果,其中输入框input元素对应属性name为“kw”,所以定位其节点代码为:
- driver.find_element_by_id(“kw”)

- elem.send_keys(“数据分析”)
send_keys()方法可以用来模拟键盘操作,相当于是在搜索框中输入“数据分析”字段。 - elem.send_keys(Keys.RETURN)
调用send_keys()函数输入回车键操作,其中Keys类提供了常见的键盘按键,如Keys.RETURN表示回车键。但在引用Keys类及其方法之前,需要注意先导入Keys类,即使用“from selenium.webdriver.common.keys import Keys”代码导入。 - driver.save_screenshot(‘baidu.png’)
调用save_screenshot()函数进行截图,并将截图保存至本地,名称为为“baidu.png”。 - driver.close()
调用close()方法关闭驱动。 - driver.quit()
调用quit()方法退出驱动。它与close()方法的区别在于:quit()方法会退出浏览器,而close()方法只是关闭页面,但如果只有一个页面被打开,close()方法同样会退出浏览器。
Selenium Python提供了一种用于定位元素(Locate Elements)的策略,你可以根据所爬取网页的HTML结构选择最适合的方案,表8.2是Selenium提供的各种方法。定位多个元素时,只需将方法“element”后加s,这些元素将会以一个列表的形式返回。

本节将结合下面这段关于李白简介的HTML代码(blog09.html)进行讲解。
<html>
<head>
<title>李白简介</title>
</head>
<body>
<p class="title"><b>静夜思</b></p>
<p class="content">
窗前明月光,<br />
疑似地上霜。 <br />
举头望明月,<br />
低头思故乡。 <br />
</p>
<div class="other" align="left" name="d1" id="nr">
李白(701年-762年),字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
<a href="http://test.com/dufu" class="poet" id="link" name="dufu">
杜甫</a>
并称为“李杜”,为了与另两位诗人
<a href="http://test.com/lsy" class="poet" id="link" name="lsy">
李商隐</a>、
<a href="http://test.com/dumu" class="poet" id="link" name="dumu">
杜牧</a>
即“小李杜”区别,杜甫与李白又合称“大李杜”。
其人爽朗大方,爱饮酒...
</div>
<p class="story">...</p>
</body>
</html>
该网页打开运行如下图9所示。

下面结合这个实例分别介绍各种元素定位方法,并以定位单个元素为主。
该方法是通过网页标签的id属性定位元素,它将返回第一个用id属性值匹配定位的元素。如果没有元素匹配id值,将会返回一个NoSuchElementException异常。
假设需要通过id属性定位页面中的杜甫、李商隐、杜牧三个超链接,HTML核心代码如下:

如果需要获取div布局,则使用如下代码:
- test_div = driver.find_element_by_id(‘nr’)
- print(test_div.text)
如果写成如下代码,则返回第一个诗人的信息。
- test_poet = driver.find_element_by_id(‘link’)
- print(test_poet.text)
- 杜甫
其中test_poet是获取的值,通常为“<selenium.webdriver…>”形式,而text是获取其文本内容,即“杜甫”。如果想通过id元素获取多个链接,比如杜甫、李商隐、杜牧三位诗人对应的超链接,则需要使用:
- find_elements_by_id()
注意“elements”表示获取多个值。三个超链接都使用同一个id名称“link”,通过find_elements_by_id()函数定位获取之后,再调用for循环输出结果,如下所示:
#-*- coding:utf-8 -*-
#By:Eastmount 2021-05-29
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#启动驱动
driver = webdriver.Firefox()
driver.get("file://C:/Users/xiuzhang/Desktop/09.selenium/blog09.html")
print(driver.title)
#查找元素并输入内容
test_div = driver.find_elements_by_id('link')
for t in test_div:
print(t.text)
输出结果如下图所示:

该方法是通过网页标签的name属性定位元素,它将返回第一个用name属性值匹配定位的元素。如果没有元素匹配name值,将会返回一个NoSuchElementException异常。
下面介绍通过name属性定位页面中的杜甫、李商隐、杜牧三个超链接的方法,HTML源码如下:
<div class="other" align="left" name="d1" id="nr">
<a href="http://test.com/dufu" class="poet" id="link" name="dufu">杜甫</a>
<a href="http://test.com/lsy" class="poet" id="link" name="lsy">李商隐</a>
<a href="http://test.com/dumu" class="poet" id="link" name=”dumu”>杜牧</a>
</div>
如果需要分别获取杜甫、李商隐、杜牧三个超链接,则使用代码如下:
test_poet1 = driver.find_element_by_name('dufu')
test_poet2 = driver.find_element_by_name('lsy')
test_poet3 = driver.find_element_by_name('dumu')
此时不能调用find_elements_by_name()函数获取多个元素,因为三位诗人对应超链接的name属性都是不同的,即“dufu”、“lsy”、“dumu”,如果name属性相同,则该方法可以获取同一name属性的多个元素。
XPath是用于定位XML文档中节点的技术,HTML\XML都采用网页DOM树状标签的结构进行编写的,所以可以通过XPath方法分析其节点信息。Selenium Python也提供了类似的方法来跟踪网页中的元素。
XPath定位元素方法不同于按照ID或Name属性的定位方法,前者更加的灵活、方便。 比如想通过ID属性定位第三个诗人“杜牧”的超链接信息,但是三位诗人的ID属性值都是相同的,即“link”,如果没有其他属性,那我们怎么实现呢?此时可以借助XPath方法进行定位元素。这也体现了XPath方法的一个优点:
- 当没有一个合适的ID或Name属性来定位所要查找的元素时,你可以使用XPath去定位这个绝对元素(但作者不建议定位绝对元素),或者定位一个有ID或Name属性的相对元素位置。
XPath方法也可以通过除了ID和Name属性以外的其他属性进行定位元素,其完整函数为:
- find_element_by_xpath()
- find_elements_by_xpath()
下面开始通过实例进行讲解,HTML代码如下:

test_div = driver.find_element_by_xpath("/html/body/div[1]")
test_div = driver.find_element_by_xpath("//div[1]")
test_div = driver.find_element_by_xpath("//div[@id='nr']")
- 第一句是使用绝对路径定位,从HTML代码的根节点开始定位元素,但如果HTML代码有稍微的改动,其结果就会被被破坏,此时可以通过后面两种方法进行定位。
- 第二句是获取HTML代码中的第一个div布局元素。但是如果所要爬取的div节点位置太深,难道我们从第一个div节点数下去吗?显然不是的。此时我们可以通过寻找附近一个元素的ID或Name属性进行定位,从而追踪到所需要的元素。
- 第三句是调用find_element_by_xpath()方法,定位ID属性值为“nr”的div布局元素,此时可以定位介绍三位著名诗人的简介信息。
三个语句输出test_div.text内容,都如下所示:
- 李白(701年-762年),字太白,号青莲居士,又号“谪仙人”, 唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与 杜甫 并称为“李杜”,为了与另两位诗人 李商隐、 杜牧 即“小李杜”区别,杜甫与李白又合称“大李杜”。 其人爽朗大方,爱饮酒…
如需定位第三位诗人“杜牧”超链接的内容,则使用如下所示的三种方法。
username = driver.find_element_by_xpath("//div[a/@name='dumu']")
username = driver.find_element_by_xpath("//div[@id='nr']/a[3]")
username = driver.find_element_by_xpath("//a[@name='dumu']")
- 第一句是定位div节点下的一个超链接a元素,且a元素的name属性为“dumu”。
- 第二句是定位“id=nr”的div元素,再找到它的第三个超链接a子元素。
- 第三句是定位name属性为“dumu”的第一个超链接a元素。
同时,如果是按钮控件且name属性相同,假设HTML代码如下:
<form id="loginForm">
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
则定位value值为“Clear”按钮元素的方法如下:
clearb = driver.find_element_by_xpath("//input[@name='continue'][@type='button']")
clearb = driver.find_element_by_xpath("//form[@id='loginForm']/input[2]")
- 第一句是定位属性name为“continue”且属性type为“button”的input控件。
- 第二句是定位属性“id=loginForm”的form节点下的第二个input子元素。
XPath定位方法作为最常用的定位元素方法之一,后面章节的实例中将会被反复利用,而本小节只是介绍了些基础知识,更多知识请读者在W3Schools XPath Tutorial、W3C XPath Recommendation或Selenium官方文档中学习。
当你需要定位一个锚点标签内的链接文本(Link Text)时就可以使用该方法。该方法将返回第一个匹配这个链接文本值的元素。如果没有元素匹配这个链接文本,将抛出一个NoSuchElementException异常。下面介绍调用该方法定位页面中的杜甫、李商隐、杜牧三个超链接,假设HTML源码如下:
- blog09_02.html
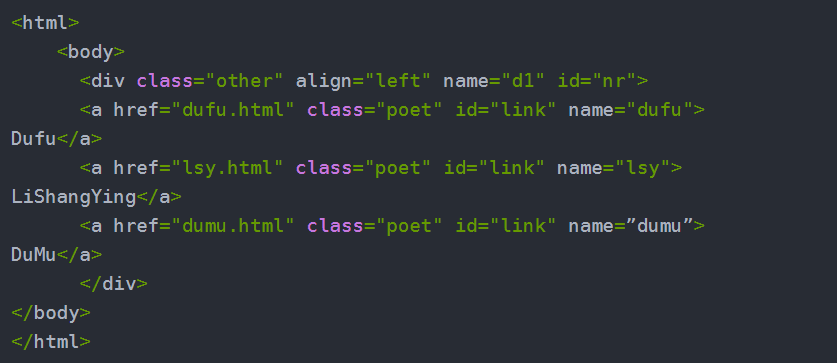
如果需要分别获取杜甫、李商隐、杜牧三个超链接,则使用如下代码。
#-*- coding:utf-8 -*-
#By:Eastmount 2021-05-29
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#启动驱动
driver = webdriver.Firefox()
driver.get("file://C:/Users/xiuzhang/Desktop/09.selenium/blog09_02.html")
print(driver.title)
#分别定位三个超链接
test_poet1 = driver.find_element_by_link_text('Dufu')
print(test_poet1.text)
test_poet2 = driver.find_element_by_link_text('LiShangYing')
print(test_poet2.text)
test_poet3 = driver.find_element_by_link_text('DuMu')
print(test_poet3.text)
#定位超链接部分元素
test_poet4 = driver.find_element_by_partial_link_text('Du')
print(test_poet4.text)
#定位超链接部分元素且定位多个元素
test_poet5 = driver.find_elements_by_partial_link_text('Du')
for t in test_poet5:
print(t.text)
其中,find_element_by_link_text()函数是使用锚点标签的链接文本进行定位的,partial表示部分匹配,获取多个元素的方法则使用:
- find_elements_by_partial_link_text()
代码运行截图如图10所示,其中地址也可以为放在本地Apache服务器中的blog09_02.html文件,内容为上面的HTML源码。
- http://localhost:8080/blog09_02.html

该方法是通过标签名(Tag Name)定位元素,它将返回第一个用Tag Name匹配定位的元素。如果没有元素匹配,将会返回一个NoSuchElementException异常。假设HTML源码如下:
- blog09_03.html
<html>
<head>
<title>李白简介</title>
</head>
<body>
<h1>静夜思</h1>
<p class='content'>窗前明月光,疑是地上霜。举头望明月,低头思故乡。</p>
</body>
</html>
定位元素h1和段落p的方法如下:
- test1 = driver.find_element_by_tag_name(‘h1’)
- test2 = driver.find_element_by_tag_name(‘p’)
该方法是通过类属性名(Class Attribute Name)定位元素,它将返回第一个用类属性名匹配定位的元素。如果没有元素匹配,将会返回一个NoSuchElementException异常。
blog09_03.html代码中通过class属性值定位段落p元素的方法如下:
- test1 = driver.find_element_by_class_name(‘content’)
该方法是通过CSS选择器(CSS Selectors)定位元素,它将返回第一个与CSS选择器匹配的元素。如果没有元素匹配,将会返回一个NoSuchElementException异常。blog09_03.html代码中通过CSS选择器定位段落p元素的方法如下:
- test1 = driver.find_element_by_css_selector(‘p.content’)
如果存在多个相同class值得content标签,则可以使用下面方法进行定位获取:
- test1 = driver.find_element_by_css_selector(*.content)
- test2 = driver.find_element_by_css_selector(.content)
CSS选择器定位方法是比较难的一个方法,推荐读者下来自行研究,同时作者更推荐大家使用ID、Name、XPath等常用定位方法。
讲述完定位元素(Locate Elements)之后,我们需要对已经定位好的对象进行操作,这些操作的交互行为通常需要通过WebElement接口来实现,常见操作元素方法如表3所示。

下面作者举一个自动登录百度首页的示例讲解常用的操作元素方法,包括clear()、send_keys()、click()、submit()等方法。
首先我们通过火狐浏览器打开百度首页,找到“登录”按钮,并右键鼠标点击“审查元素”,可以看到百度首页“登录”按钮对应的HTML源代码如图11所示。

“登录”按钮节点其实是一个name值为“tj_login”的超链接,我们可以通过下面的代码定位到该节点,再调用click()函数自动点击它,并跳转到登录页面。
- login = driver.find_element_by_name(“tj_login”)
- login.click()

新版百度又增加了“用户名登录”的选择,我们需要进一步捕获该位置并点击。

点击按钮后弹出界面如图13所示,接下来需要分析用户名和密码的HTML源码,并找到其节点位置后实现自动登录操作。

接着再审查登录页面,获取“用户名”和“密码”元素,对应HTML核心代码如下:
<input id="TANGRAM__PSP_10__userName" type="text" value=""
autocomplete="off" class="pass-text-input pass-text-input-userName"
name="userName" placeholder="手机/邮箱/用户名"></input>
<input id="TANGRAM__PSP_10__password" type="password" value=""
class="pass-text-input pass-text-input-password"
name="password" placeholder="密码"></input>
通过find_element_by_name()定位元素,调用函数clear()清除输入框默认内容,如“请输入密码”等提示,并调用send_keys()函数输入正确的用户名和密码后点击登录。核心代码如下:
name = driver.find_element_by_name("userName")
name.send_keys("admin")
pwd = driver.find_element_by_name("password")
pwd.send_keys("123456")
pwd.send_keys(Keys.RETURN)
错误提示
在自动登录百度首页时,可能会提示错误“selenium.common exceptions ElementNotInteractable Exception: could not be scrolled into view”,这是因为某些情况下,元素的visibility为hidden或者display属性为none,我们在页面上看不到但是实际是存在页面的一些隐藏元素,这时候用 is_displayed() 来判断并设置时间等待。

完整代码如下:
#-*- coding:utf-8 -*-
#By:Eastmount CSDN 2021-05-29
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
#打开浏览器
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
time.sleep(1)
#点击登录链接
logins = driver.find_elements_by_name("tj_login")
for login in logins:
print(login.text)
print(login.get_attribute('href'))
if login.is_displayed():
login.click()
time.sleep(1)
#通过二次定位寻找用户名登录按钮
uesrlogins = driver.find_elements_by_xpath("//div[@class='tang-pass-footerBar']/p")
for uesrlogin in uesrlogins:
print(uesrlogin.text)
if uesrlogin.is_displayed():
uesrlogin.click()
#输入密码并登陆
name = driver.find_element_by_name("userName")
name.clear
name.send_keys("Eastmount")
pwd = driver.find_element_by_name("password")
pwd.clear
pwd.send_keys("12345678")
#暂停输入验证码 按回车键登录
time.sleep(5)
pwd.send_keys(Keys.RETURN)
driver.close()
注意:如果登录过程中需要输入验证码,则使用time.sleep(5)暂停函数,手动输入验证码“报表”后,程序会执行send_keys(Keys.RETURN)函数,输入回车键实现百度网自动登录。

最终,该部分代码会自动输入指定的用户名和密码,然后输入回车键实现登录操作。但需要注意,由于部分页面是动态加载的,而实际操作时可能无法捕获其节点,同时百度网页的HTML源码也会不定期变化,但是其原理知识更为重要,希望读者掌握类似的分析方法,在后面爬取微博、知乎、B站等案例时,也会再结合实例详细讲解自动登录爬虫。

通过WebElement接口可以获取常用的值,其中常见属性值如下表所示。

该部分代码如下:
#-*- coding:utf-8 -*-
#By:Eastmount CSDN 2021-05-29
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
print(driver.title)
print(driver.current_url)
# 百度一下,你就知道
# https://www.baidu.com/
news = driver.find_element_by_xpath("//div[@id='u1']/a[1]")
print(news.text)
print(news.get_attribute('href'))
print(news.location)
# 新闻
# http://news.baidu.com/
# {'y': 19.0, 'x': 456.0}
输出结果如下图所示:

- driver.title是输出网页的标题“百度一下,你就知道”,driver.current_url输出当前页面的超链接;
- 再通过find_element_by_xpath("//div[@id=‘u1’]/a[1]")函数定位百度首页右上角“新闻”链接;
- 然后调用news.text代码输出其内容;
- 最后get_attribute(‘href’)函数是获取超链接,news.location是输出其网页坐标位置。
Selenium技术另一个特点就是可以自动化操作鼠标和键盘,所以它更多的应用是自动化测试领域,通过自动操作网页,反馈响应的结果从而检测网站的健壮性和安全性。
在Selenium提供的Webdriver库中,其子类Keys提供了所有键盘按键操作,比如回车键、Tab键、空格键,同时也包括一些常见的组合按键操作,如Ctrl+A(全选)、Ctrl+C(复制)、Ctrl+V(粘贴)等。常用键盘操作如下:
- send_keys(Keys.ENTER):按下回车键,最常用按键操作
- send_keys(Keys.TAB):按下Tab制表键
- send_keys(Keys.SPACE):按下空格键Space
- send_keys(Kyes.ESCAPE):按下回退键Esc
- send_keys(Keys.BACK_SPACE):按下删除键BackSpace
- send_keys(Keys.SHIFT):按下Shift键
- send_keys(Keys.CONTROL):按下Ctrl键
- send_keys(Keys.CONTROL,‘a’):按下组合键全选Ctrl+A
- send_keys(Keys.CONTROL,‘c’):按下组合键复制Ctrl+C
- send_keys(Keys.CONTROL,‘x’):按下组合键剪切Ctrl+X
- send_keys(Keys.CONTROL,‘v’):按下组合键粘贴Ctrl+V
下面举一个百度自动搜索“Python”关键字的简单示例,代码如下:
#-*- coding:utf-8 -*-
#By:Eastmount CSDN 2021-05-29
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
elem = driver.find_element_by_id("kw")
elem.send_keys("Python")
elem.send_keys(Keys.RETURN)
首先需要定位百度搜索框的HTML源代码,分析结果如图14所示,百度搜索框对应的HTML标签为input且其ID属性为“kw”,故定位代码为:
- driver.find_element_by_id(“kw”)

然后调用elem.send_keys(“Python”)输入关键字“Pyhon”,elem.send_keys(Keys.RETURN)代码表示输入回车键,相当于点击“百度一下”按钮,反馈结果如图15所示。

同样可以自动搜索作者“Eastmount”的信息,哈哈~

Selenium操作鼠标技术也常用于自动化测试中,它位于ActionChains类中,最常用的是click()函数,该函数表示单击鼠标左键操作。常见的鼠标操作如下:
- click():点击鼠标左键一次
- context_click(elem):右击鼠标点击元素elem,比如在弹出的快捷键菜单中选择“另存为”等命令
- double_click(elem):击鼠标点击元素elem
- drag_and_drop(source,target):鼠标拖动操作。在源元素source位置下按下鼠标左键,并移动至目标元素target释放鼠标
- send_keys(Keys.BACK_SPACE):按下删除键BackSpace
- move_to_element(elem):将鼠标光标移动到元素elem上
- click_and_hold(elem):按下鼠标左键并悬停在元素elem上
- perform():执行ActionChains类中的存储操作,弹出对话框
下面的示例代码是定位百度的logo图片,再执行鼠标右键另存为图片操作。

弹出对话框如下图所示,新版本尝试输入k键也能另存为网页。

前一小节讲述了Python操作键盘和鼠标,建议读者一定要自己去实现该部分代码,从而更好地应用到实际项目中去。本小节主要介绍Selenium的导航控制操作,包括页面交互、表单操作和对话框间移动。
前面讲述的百度搜索案例就是一个页面交互的过程,包括:
- 调用driver.find_element_by_xpath()函数定位元素。
- 调用send_keys(key)输入关键词或键盘按键,如输入Keys.RETURN回车键。
- 调用click()函数点击左键,右键点击“另存为图片”等。
这里我们将补充页面交互的切换下拉菜单的实例。定位“name”下拉菜单标签之后,我们调用SELECT类选中选项,同时select_by_visible_text()用于显示选中菜单,也可以提交Form表单。
from selenium.webdriver.support.ui import Select
name = driver.find_element_by_name('name')
select = Select(name)
select.select_by_index(index)
select.select_by_visible_text("text")
select.select_by_value(value)
如果读者想取消已经选中的选项,则使用如下代码:
from selenium.webdriver.support.ui import Select
name = driver.find_element_by_name('name')
select = Select(name)
all_selected_options = select.all_selected_options
获取所有的可用选项则调用select.options即可,当读者填写完表单后,可以通过submit()函数提交,或者找到提交按钮后调用下面函数提交表单。
- driver.find_element_by_id(“submit”).click()
网站通常都是由多个窗口组成的,称为多帧Web应用,WebDriver提供了方法switch_to_window来支持命名窗口间的移动切换。比如:
- driver.switch_to_window(“windowName”)
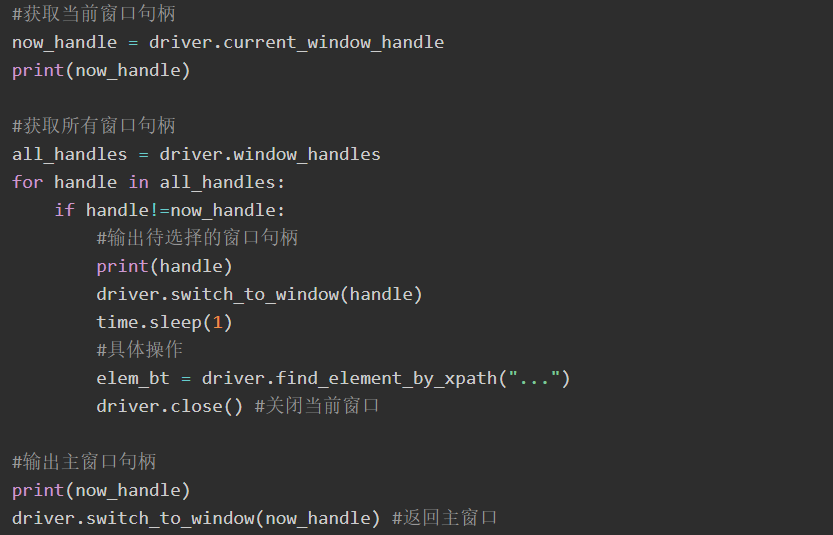
现在driver的所有操作将会针对特定的窗口。但是怎么才能知道窗口的名字呢?可以通过定位其HTML源码中的超链接,或者给switch_to_window()方法传递一个“窗口句柄”,常用的方法是循环遍历所有的窗口,再获取指定的句柄进行定位操作,核心代码如下:
for handle in driver.window_handles:
driver.switch_to_window(handle)
在帧与帧(Iframe)之间切换使用driver.switch_to_frame(“frameName”)函数。对于弹出式对话框,Selenium WebDriver提供了内建支持,通过switch_to_alert()函数将返回当前打开的alert对象,通过该对象您可以进行确认同意或反对操作,也可以读取它的内容。
- alert = driver.switch_to_alert()
更多知识推荐读者阅读官方文档,下面是捕获弹出式对话框内容的核心代码。
后续实例也会介绍一种窗口句柄转义的方法。
Selenium库分析和定位节点的方法和BeautifulSoup库类似,它们都能够利用类似于XPath技术来定位标签,都拥有丰富的操作函数来爬取数据。但不同之处在于:
- Selenium能方便的操控键盘、鼠标以及切换对话框、提交表单等,当我们的目标网页需要验证登录之后才能爬取、所爬取的数据位于弹出来的对话框中或者所爬取的数据通过超链接跳转到了新的窗体时,Selenium技术的优势就体现出来了,它通过控制鼠标模拟登录或提交表单从而爬取数据,但其缺点是爬取效率较低,BeautifulSoup速度更快些。
Selenium用得更广泛的领域是自动化测试,它直接运行在浏览器中(如Firefox、Chrome、IE等),就像真实用户操作一样,对开发的网页进行各式各样的测试,它更是自动化测试方向的必备工具。希望读者能掌握这种技术的爬取方法,尤其是目标网页需要验证登录等情形。
该系列所有代码下载地址:
感谢在求学路上的同行者,不负遇见,勿忘初心。这周的留言感慨~

希望能与大家一起在华为云社区共同承载,原文地址:https://blog.csdn.net/Eastmount/article/details/117376267
【生长吧!Python】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/278897
(By:娜璋之家 Eastmount 2021-07-13 夜于武汉 )

- 点赞
- 收藏
- 关注作者
评论(0)