Python脚本配合Github Actions自动更新Markdown文章到WordPress 丨【生长吧!Python】

用Github Actions写Markdown文章,自动更新到WordPress
-
写博客最舒服的格式是Markdown;
-
管理博客站最省心的方式是WordPress;
-
推广博客站最好的平台是Github;
这个Python脚本可以让你用Markdown写博客,push更新到Github后,Github Actions自动将文章更新到WordPress, 并将WordPres站的文章索引更新到Github仓库的README.md,供搜索引擎收录。
Python源码
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts, NewPost, EditPost
from urllib.parse import urlparse
import frontmatter
import time
import os
from hashlib import md5, sha1
import json
import markdown
import re
config_file_txt = ""
if((os.path.exists(os.path.join(os.getcwd(), "diy_config.txt")) == True)):
config_file_txt = os.path.join(os.getcwd(), "diy_config.txt")
else:
config_file_txt = os.path.join(os.getcwd(), "config.txt")
config_info = {}
with open (config_file_txt, 'rb') as f:
config_info = json.loads(f.read())
username = config_info["USERNAME"]
password = config_info["PASSWORD"]
xmlrpc_php = config_info["XMLRPC_PHP"]
try:
if(os.environ["USERNAME"]):
username = os.environ["USERNAME"]
if(os.environ["PASSWORD"]):
password = os.environ["PASSWORD"]
if(os.environ["XMLRPC_PHP"]):
xmlrpc_php = os.environ["XMLRPC_PHP"]
except:
print("无法获取github的secrets配置信息,开始使用本地变量")
url_info = urlparse(xmlrpc_php)
domain_name = url_info.netloc
wp = Client(xmlrpc_php, username, password)
# 获取已发布文章id列表
def get_posts():
print(time.strftime('%Y-%m-%d-%H-%M-%S')+"开始从服务器获取文章列表...")
posts = wp.call(GetPosts({'post_type': 'post', 'number': 1000000000}))
post_link_id_list = []
for post in posts:
post_link_id_list.append({
"id": post.id,
"link": post.link
})
print(post_link_id_list)
print(len(post_link_id_list))
return post_link_id_list
# 创建post对象
def create_post_obj(title, content, link, post_status, terms_names_post_tag, terms_names_category):
post_obj = WordPressPost()
post_obj.title = title
post_obj.content = content
post_obj.link = link
post_obj.post_status = post_status
post_obj.comment_status = "open"
print(post_obj.link)
post_obj.terms_names = {
#文章所属标签,没有则自动创建
'post_tag': terms_names_post_tag,
#文章所属分类,没有则自动创建
'category': terms_names_category
}
return post_obj
# 新建文章
def new_post(title, content, link, post_status, terms_names_post_tag, terms_names_category):
post_obj = create_post_obj(
title = link,
content = content,
link = link,
post_status = post_status,
terms_names_post_tag = terms_names_post_tag,
terms_names_category = terms_names_category)
# 先获取id
id = wp.call(NewPost(post_obj))
# 再通过EditPost更新信息
edit_post(id, title,
content,
link,
post_status,
terms_names_post_tag,
terms_names_category)
# 更新文章
def edit_post(id, title, content, link, post_status, terms_names_post_tag, terms_names_category):
post_obj = create_post_obj(
title,
content,
link,
post_status,
terms_names_post_tag,
terms_names_category)
res = wp.call(EditPost(id, post_obj))
print(res)
# 获取markdown文件中的内容
def read_md(file_path):
content = ""
metadata = {}
with open(file_path) as f:
post = frontmatter.load(f)
content = post.content
metadata = post.metadata
print("==>>", post.content)
print("===>>", post.metadata)
return (content, metadata)
# 获取特定目录的markdown文件列表
def get_md_list(dir_path):
md_list = []
dirs = os.listdir(dir_path)
for i in dirs:
if os.path.splitext(i)[1] == ".md":
md_list.append(os.path.join(dir_path, i))
print(md_list)
return md_list
# 计算sha1
def get_sha1(filename):
sha1_obj = sha1()
with open(filename, 'rb') as f:
sha1_obj.update(f.read())
result = sha1_obj.hexdigest()
print(result)
return result
# 将字典写入文件
def write_dic_info_to_file(dic_info, file):
dic_info_str = json.dumps(dic_info)
file = open(file, 'w')
file.write(dic_info_str)
file.close()
return True
# 将文件读取为字典格式
def read_dic_from_file(file):
file_byte = open(file, 'r')
file_info = file_byte.read()
dic = json.loads(file_info)
file_byte.close()
return dic
# 获取md_sha1_dic
def get_md_sha1_dic(file):
result = {}
if(os.path.exists(file) == True):
result = read_dic_from_file(file)
else:
write_dic_info_to_file({}, file)
return result
# 重建md_sha1_dic,将结果写入.md_sha1
def rebuild_md_sha1_dic(file, md_dir):
md_sha1_dic = {}
md_list = get_md_list(md_dir)
for md in md_list:
key = os.path.basename(md)
value = get_sha1(md)
md_sha1_dic[key] = value
md_sha1_dic["update_time"] = time.strftime('%Y-%m-%d-%H-%M-%S')
write_dic_info_to_file(md_sha1_dic, file)
def post_link_id_list_2_link_id_dic(post_link_id_list):
link_id_dic = {}
for post in post_link_id_list:
link_id_dic[post["link"]] = post["id"]
return link_id_dic
def href_info(link):
return "<br/><br/><br/>\n\n\n\n## 本文永久更新地址: \n[" + link + "](" + link + ")"
# 在README.md中插入信息文章索引信息,更容易获取google的收录
def insert_index_info_in_readme():
# 获取_posts下所有markdown文件
md_list = get_md_list(os.path.join(os.getcwd(), "_posts"))
# 生成插入列表
insert_info = ""
md_list.sort(reverse=True)
# 读取md_list中的文件标题
for md in md_list:
(content, metadata) = read_md(md)
title = metadata.get("title", "")
insert_info = insert_info + "[" + title +"](" + "https://"+domain_name + "/p/" + os.path.basename(md).split(".")[0] +"/" + ")\n\n"
# 替换 ---start--- 到 ---end--- 之间的内容
insert_info = "---start---\n## 目录(" + time.strftime('%Y年%m月%d日') + "更新)" +"\n" + insert_info + "---end---"
# 获取README.md内容
with open (os.path.join(os.getcwd(), "README.md"), 'r', encoding='utf-8') as f:
readme_md_content = f.read()
print(insert_info)
new_readme_md_content = re.sub(r'---start---(.|\n)*---end---', insert_info, readme_md_content)
with open (os.path.join(os.getcwd(), "README.md"), 'w', encoding='utf-8') as f:
f.write(new_readme_md_content)
print("==new_readme_md_content==>>", new_readme_md_content)
return True
def main():
# 1. 获取网站数据库中已有的文章列表
post_link_id_list = get_posts()
print(post_link_id_list)
link_id_dic = post_link_id_list_2_link_id_dic(post_link_id_list)
print(link_id_dic)
# 2. 获取md_sha1_dic
# 查看目录下是否存在md_sha1.txt,如果存在则读取内容;
# 如果不存在则创建md_sha1.txt,内容初始化为{},并读取其中的内容;
# 将读取的字典内容变量名,设置为 md_sha1_dic
md_sha1_dic = get_md_sha1_dic(os.path.join(os.getcwd(), ".md_sha1"))
# 3. 开始同步
# 读取_posts目录中的md文件列表
md_list = get_md_list(os.path.join(os.getcwd(), "_posts"))
for md in md_list:
# 计算md文件的sha1值,并与md_sha1_dic做对比
sha1_key = os.path.basename(md)
sha1_value = get_sha1(md)
# 如果sha1与md_sha1_dic中记录的相同,则打印:XX文件无需同步;
if((sha1_key in md_sha1_dic.keys()) and (sha1_value == md_sha1_dic[sha1_key])):
print(md+"无需同步")
# 如果sha1与md_sha1_dic中记录的不同,则开始同步
else:
# 读取md文件信息
(content, metadata) = read_md(md)
# 获取title
title = metadata.get("title", "")
terms_names_post_tag = metadata.get("tags", domain_name)
terms_names_category = metadata.get("categories", domain_name)
post_status = "publish"
link = sha1_key.split(".")[0]
content = markdown.markdown(content + href_info("https://"+domain_name+"/p/"+link+"/"), extensions=['tables', 'fenced_code'])
# 如果文章无id,则直接新建
if(("https://"+domain_name+"/p/"+link+"/" in link_id_dic.keys()) == False):
new_post(title, content, link, post_status, terms_names_post_tag, terms_names_category)
# 如果文章有id, 则更新文章
else:
# 获取id
id = link_id_dic["https://"+domain_name+"/p/"+link+"/"]
edit_post(id, title, content, link, post_status, terms_names_post_tag, terms_names_category)
# 4. 重建md_sha1_dic
rebuild_md_sha1_dic(os.path.join(os.getcwd(), ".md_sha1"), os.path.join(os.getcwd(), "_posts"))
# 5. 将链接信息写入insert_index_info_in_readme
insert_index_info_in_readme()
main()
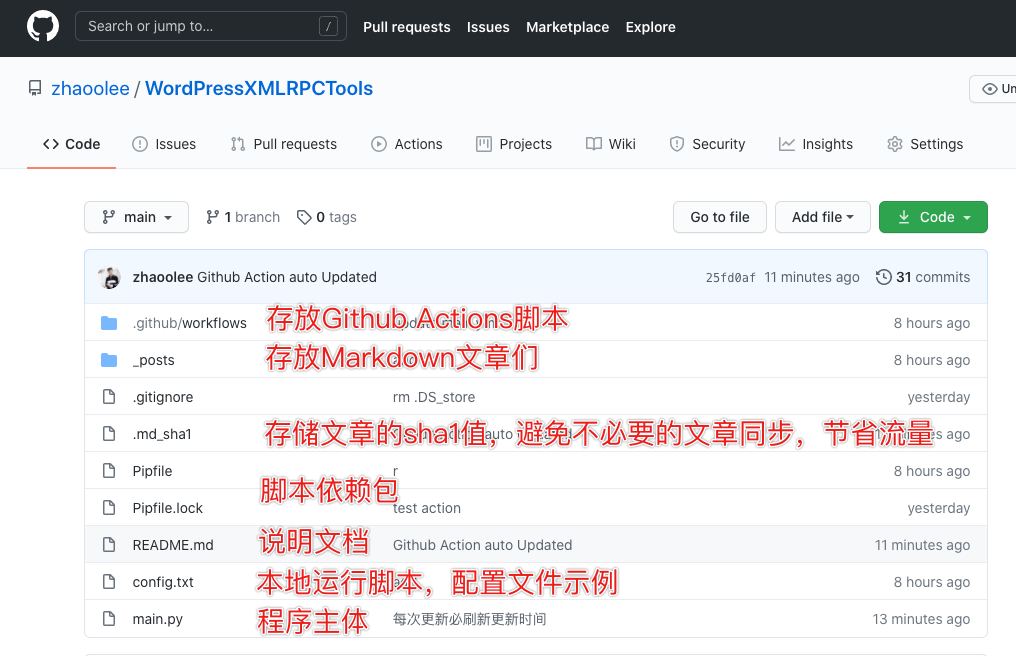
Python脚本永久开源更新地址
https://github.com/zhaoolee/WordPressXMLRPCTools
如何实现WordPress登录授权?
WordPress默认开启了xmlrpc服务,xmlrpc是一套的统用的博客更新标准,允许用户以POST方式自动对文章内容进行增删改查。授权方式为 用户名 和 密码, 在WordPress中是后台登录的账户名和密码
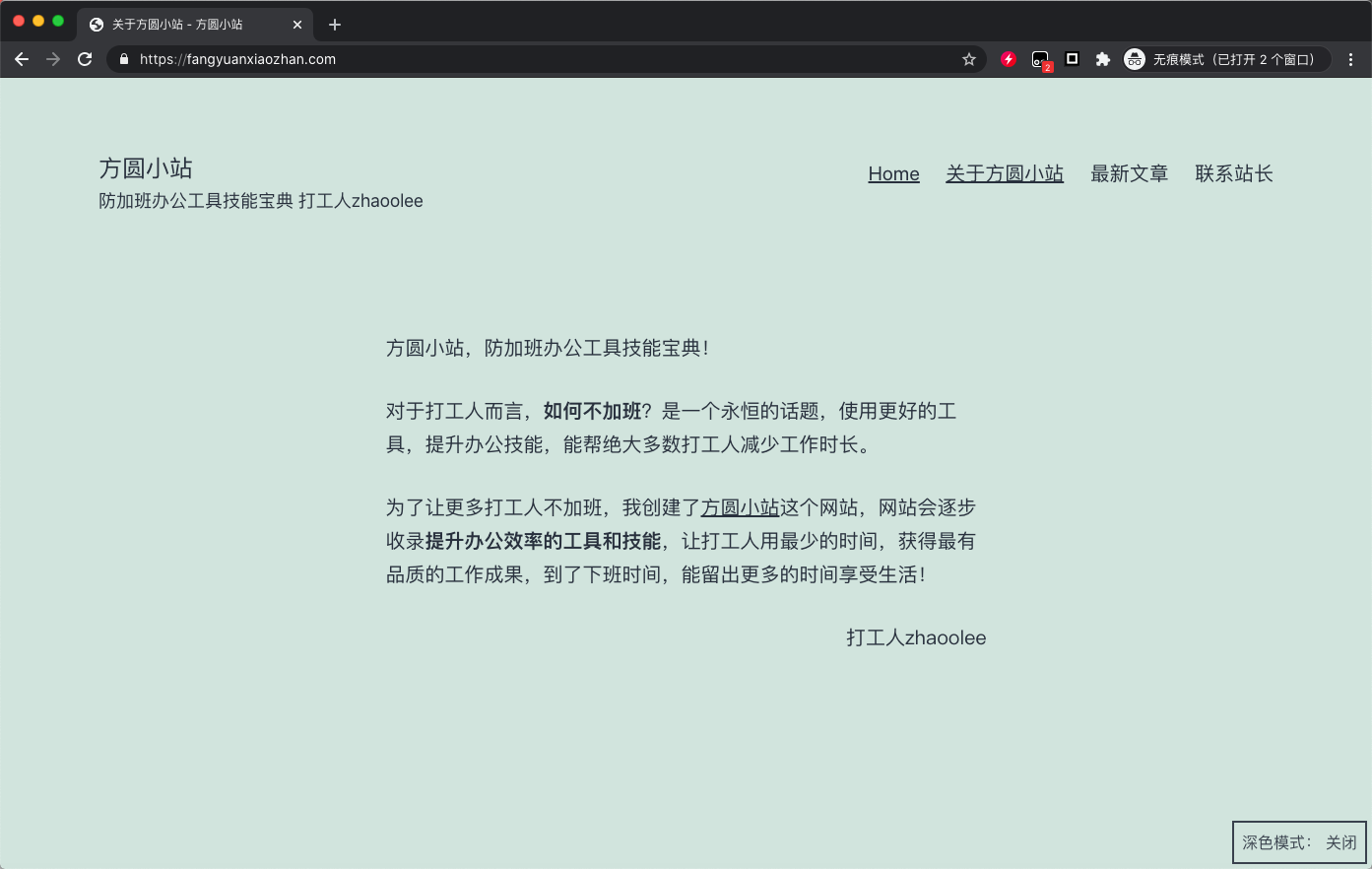
我的WordPress网站为 https://fangyuanxiaozhan.com
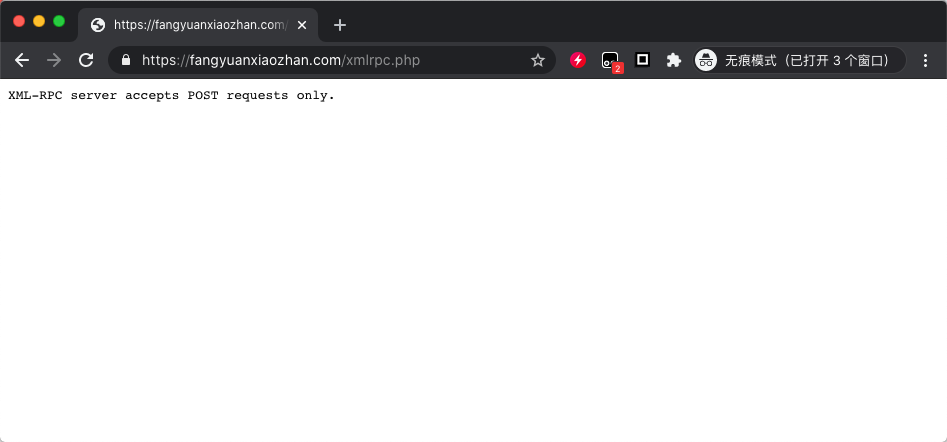
它的xmlrpc服务地址为 https://fangyuanxiaozhan.com/xmlrpc.php
使用Github Actions 有什么好处?
Github Actions 可以让我们无需安装开发环境,即可完成代码的运行。
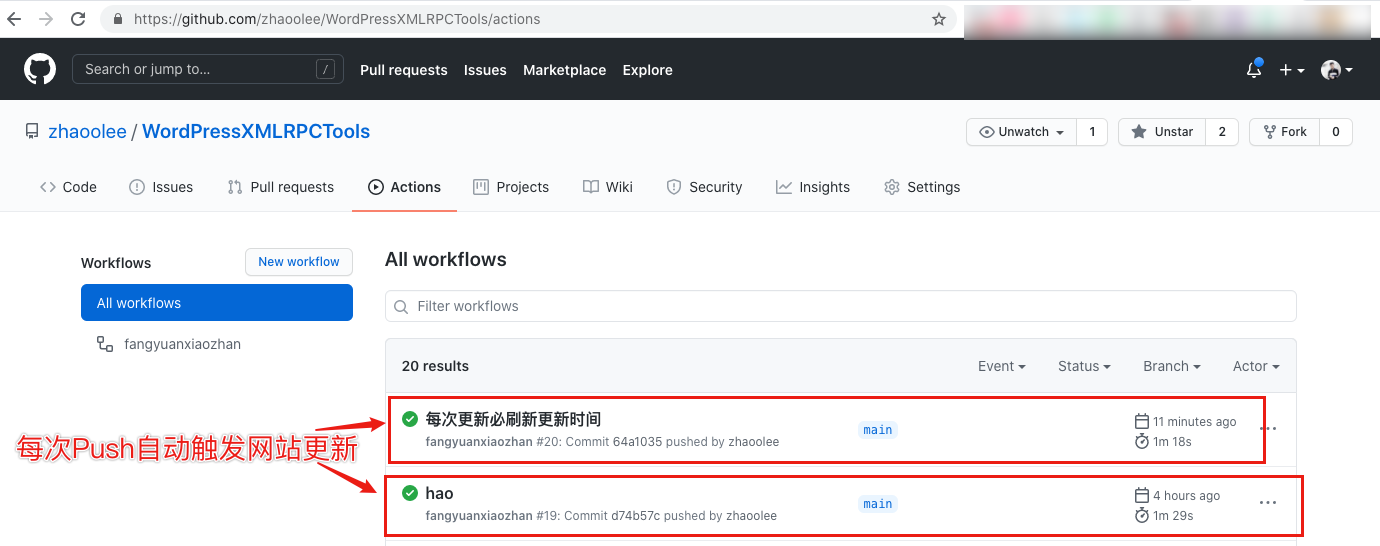
对于本项目而言,我可以用手机版Git App,或者Github网页完成新建文章, 然后push到仓库,Github Actions会自动帮我完成相关代码运行,代码可以帮我更新文章到WordPress网站,并生成新的文章目录索引,并自动给你更新到README.md, 供搜索引擎收录。
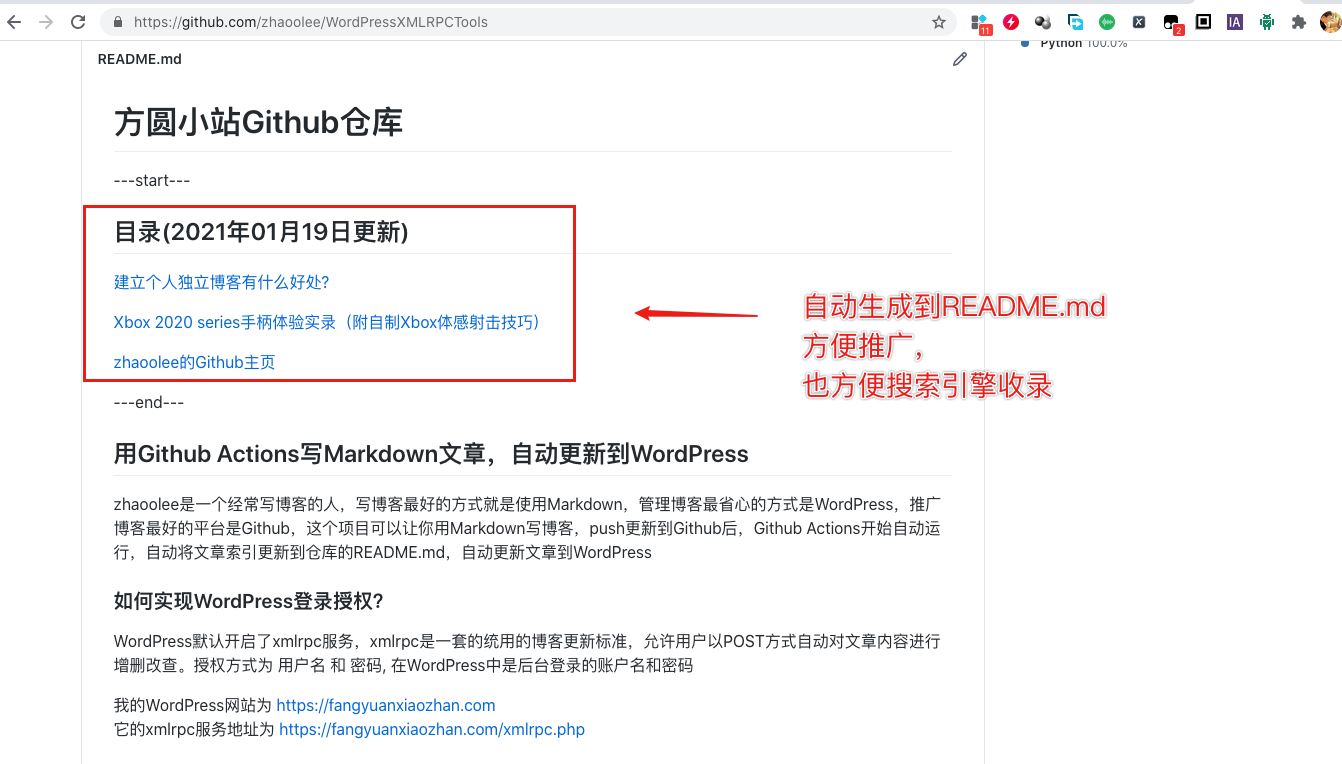
如何保护自己的WordPress账户密码?
Github 有一个secrets 功能,可以将用户名密码等关键信息保护起来,只有Github Actions可以读取到关键信息。
本项目需要设置三个secret
- WordPress登录用户名, 变量名为 USERNAME
- WordPress登录密码,变量名为 PASSWORD
- WordPress的xmlrpc.php,变量名为 XMLRPC_PHP
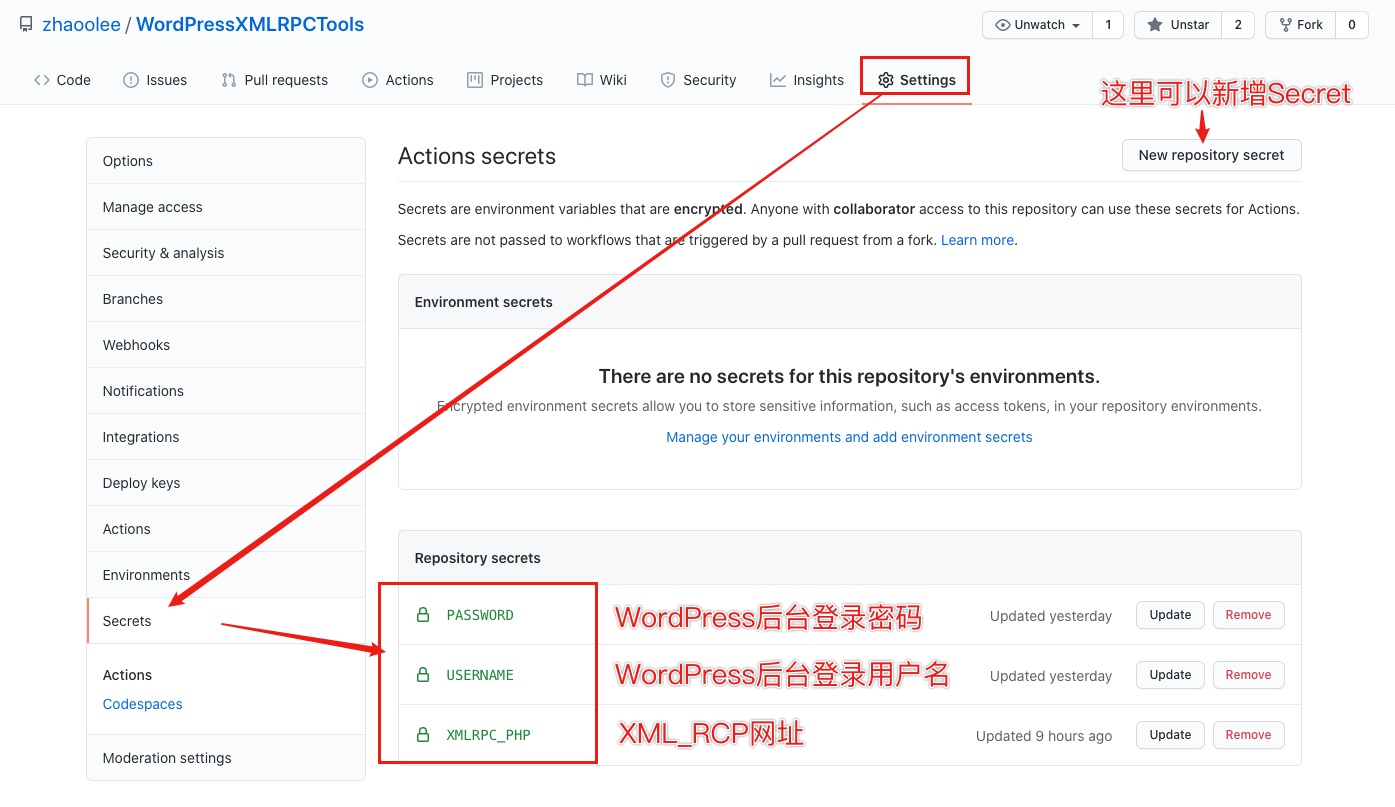
如何新建文章?
在_post 目录下新建 后缀为 .md 的markdown文件即可
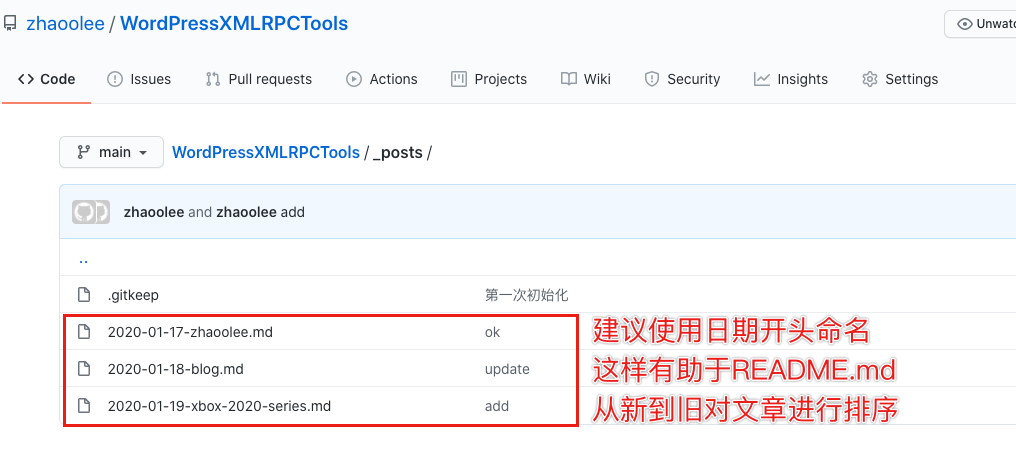
文章管理:如何为文章分类/加关键词标签?
在 .md 文件顶部填写以下初始化信息,即可完成标题(title),标签(tags),分类(categories)的设置,其中title为必填项目(这些关键词不是我定义的,我借用了著名静态博客构建工具 hexo 的标准)
---
title: 我是标题
tags:
- 我是0号标签关键词
- 我是1号标签关键词
- 我是2号标签关键词
categories:
- 我是1号分类
- 我是2号分类
---
标签(tags)和分类(categories)有什么区别?
标签(tags)是针对单篇文章的关键词,比如香蕉的标签有 黄色,味甜 (标签是香蕉的属性)
分类(categories)是本篇文章的归属,比如香蕉的分类为 水果,植物
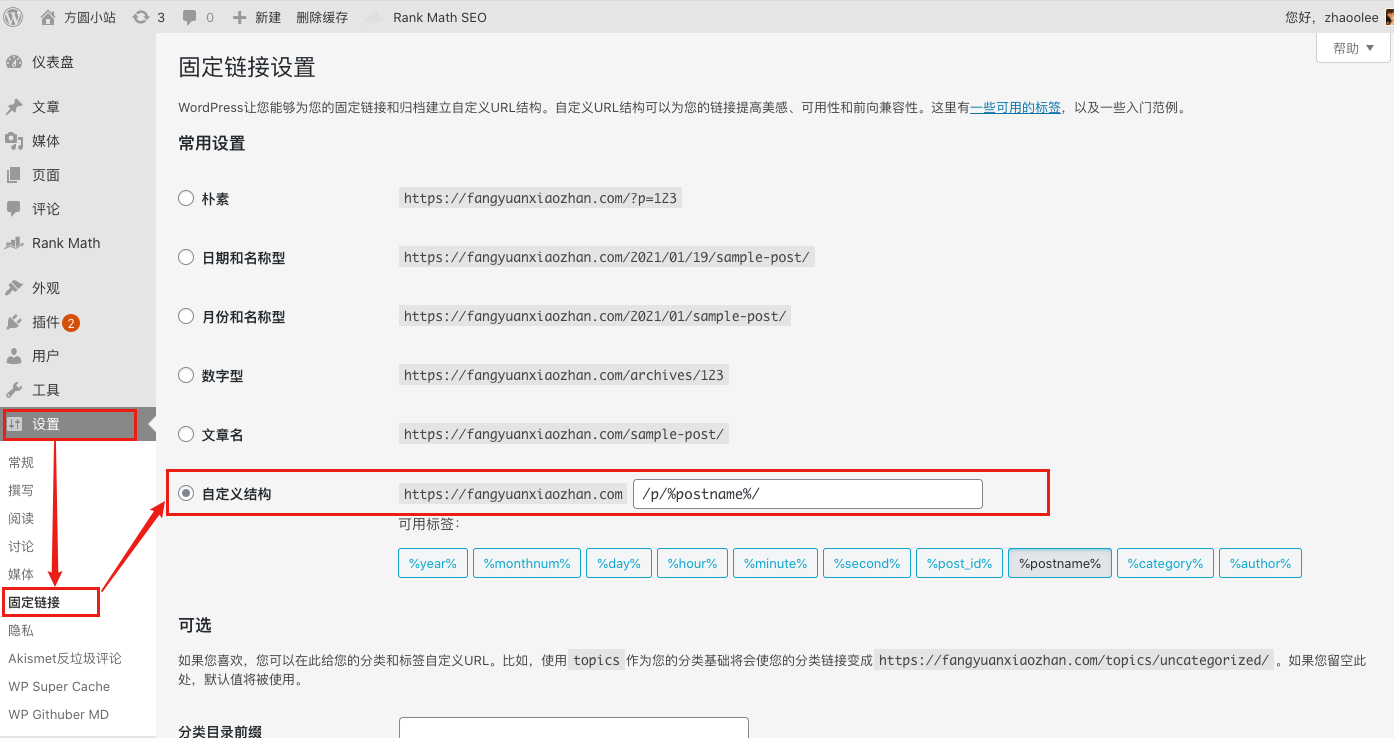
如何设置固定链接?
对于博客而言,文章拥有一个固定的链接,是很重要的,我经过各种尝试,最终借鉴了 简书 的文章url形式,域名后加 /p/ , 再加英文文件名,只要不改变英文文件名,文章就有固定的链接,我在_posts 目录下新建一个 2020-01-18-blog.md 文件,同步后的文章url为
https://fangyuanxiaozhan.com/p/2020-01-18-blog/
文件名与网站url严格对应,既方便了修改,又可以在网站数据库出事故后,迅速从github仓库迅速恢复文章内容(容灾),连url都不会变。
如何使用?
完成以上配置后
每次在_posts 文件夹新增或更新文章后,运行
git pull && git add _posts && git commit -m "update" && git push
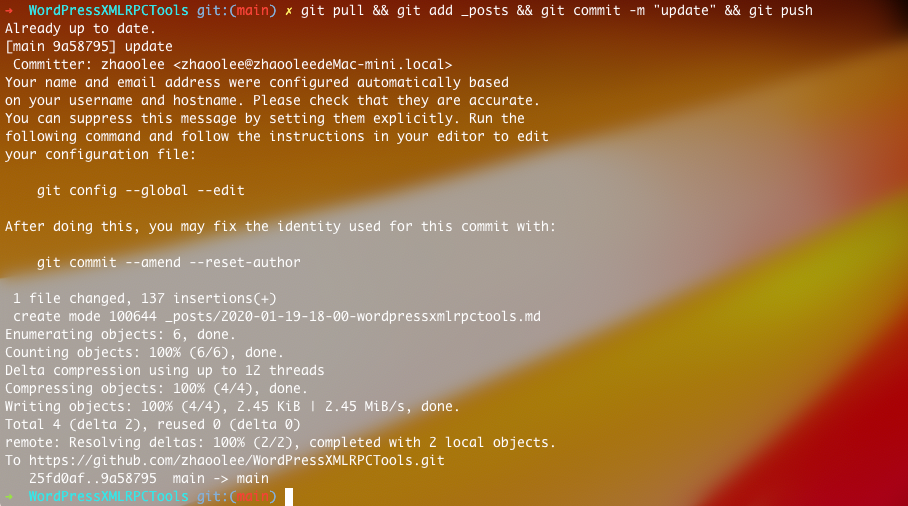
即可!
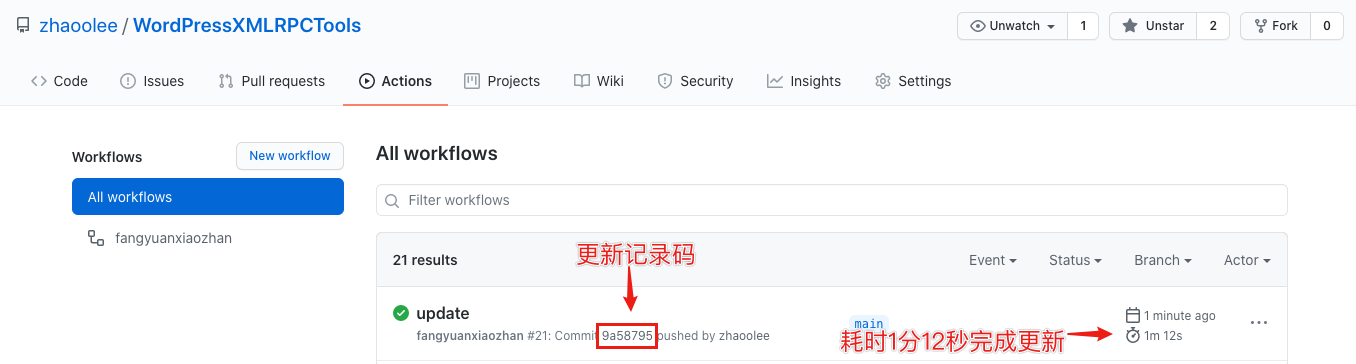
Github README.md显示效果,(新增的文章排在首位)
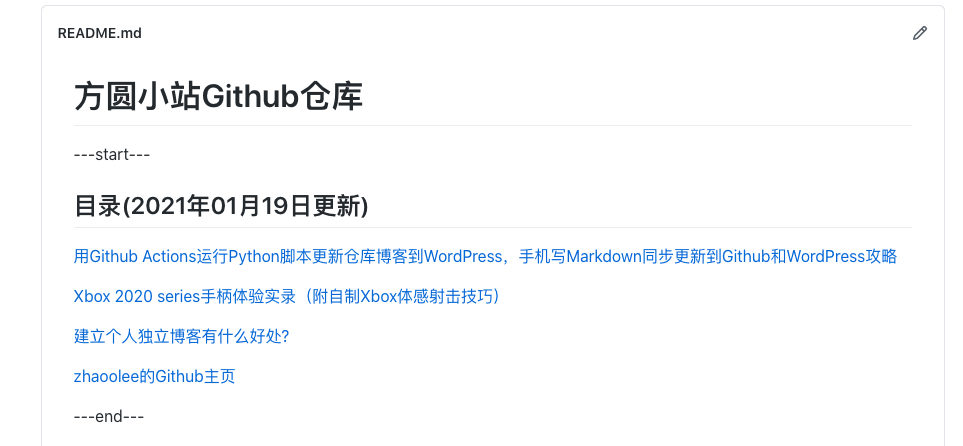
WordPress网站也同步发布了文章
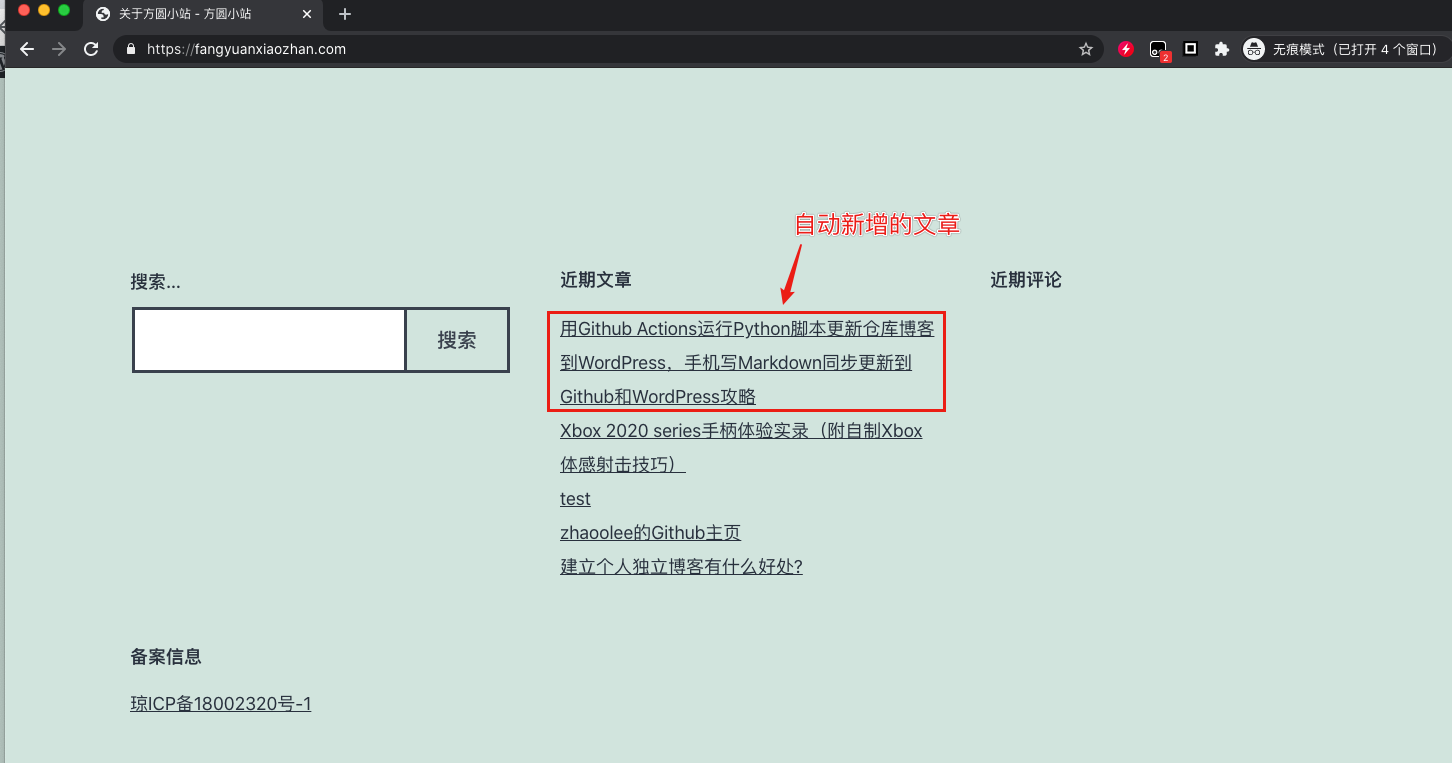
https://fangyuanxiaozhan.com/p/2020-01-19-18-00-wordpressxmlrpctools/
如何用手机完成博客更新操作?

用锤子便签,可以优雅舒适地写Markdown,手机App很好用,还有网页版可以用,有5GB的免费空间,能写到锤子倒闭。
如果遇到插入图片的问题,可以使用 免费图床图壳
Pocket Git 和 MT管理器可以配合完成Git 文件的新增更新和上传。
当我们把毕生所学,通过几十年如一日的博客更新,逐步开源到互联网上时,将会造福更多志同道合的人。
【生长吧!Python】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/278897

- 点赞
- 收藏
- 关注作者
评论(0)