华为云数据库GaussDB(for Cassandra)揭秘第一期:初识GaussDB(for Cassandra)

“local quorum查询某个分区键的条数,每次查询,条数都不一样。”
“按这个分区键的token修复,直接瞬间修复结束。但是再查,还是每次查询条数不一致。”
“之前遇到墓碑丢失的问题,单个token查询结果不一致,修复也解决不了”
…..
不用再为数据不一致苦恼,因为强一致的Cassandra来了,DBA们不用加班修数据了。
GaussDB(for Cassandra)是一款基于华为自主研发的计算存储分离架构的分布式云数据库服务。是一个强一致性的系统,在华为云高性能、高可用、高可靠、高安全、可弹性伸缩的基础上,提供了一键部署、备份恢复、监控报警等服务能力。高度兼容开源Cassandra接口,并提供高读写性能,具有高性价比,适用于IoT、气象、互联网、游戏等领域。
本文将从架构、主要特性、竞争力、应用场景等方面进行介绍。
设计架构:
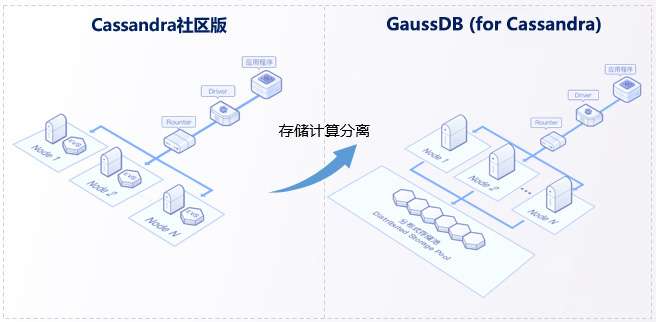
GaussDB(for Cassandra)基于计算存储分离架构,该架构基于华为内部强大且广泛使用的自研分布式存储系统DFV(数据功能虚拟化/Data Function Virtualisation),实现了一套Share Everything的云开源架构,充分发挥了云开源的弹性伸缩、资源共享的优势,高度兼容Cassandra协议,拥有超强写入性能,同时相比社区版具有分钟级计算扩容、秒级存储扩容、数据强一致等优势,性能更强更稳定,数据更可靠,扩容更敏捷,适用于IoT、实时推荐、金融反欺诈检测等场景。
GaussDB(for Cassandra)牛在哪?
高可靠:数据强一致,提供企业级数据可靠性
开源Cassandra读写数据采用最终一致性,此处用读场景举例:如果读一致性要求为ONE,会立即返回离客户端最近的一份数据副本,那么这意味着第一次读取到的数据可能不是最新的数据。如果读一致性要求为QUORUM(即读取任一数据中心中quorum数量的节点的结果,返回合并后timestamp最新的结果),则内核会自动触发读修复,然后返回给客户端。假如此时有副本所在节点出现坏盘,在gc_graces的周期内没有完成数据修复,部分副本属于坏盘节点的业务数据,业务查询过程中发现数据会概率性不正确。
GaussDB(for Cassandra)采用存算分离架构,数据的副本在DFV存储平台保证,对计算节点来说数据单副本、数据强一致,查询只需要从协调节点直接到数据节点取数据即可完成,规避了数据不一致修复数据造成的人力成本、业务查询过程中发现数据会概率性不正确等问题。另外支持N-1个节点故障容忍,提供10倍以上的故障重构性能和备份恢复性能,保证数据的可靠性。
高扩展:秒级扩容,快速更神速
开源Cassandra采用一致性Hash算法对数据进行分区打散,整个环代表数据从负无穷到正无穷区间。集群中每个节点会有虚拟节点(Token)在环上,虚拟节点的数量可配置。黄圈代表节点1,蓝圈代表要扩容的节点2,2个Token之间组成整个数据的其中一段Range区间,扩容后加入了新的Token,会产生新的Range,这些Range中的一部分会归新节点2管理。那么就需要把数据从节点1迁移到新节点2上去。迁移是通过读取节点1上的数据写入到节点2上,迁移的速度可以通过配置参数调整,整体迁移的时间由数据量与迁移过程中的读写速率有关。
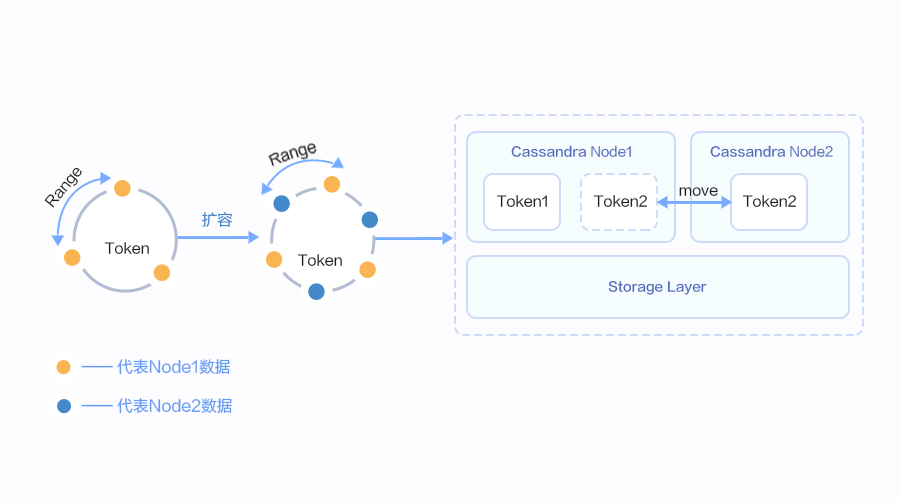
GaussDB(for Cassandra)把多副本策略下沉到共享存储,大幅提升弹性伸缩能力,如图右侧展示,新扩容的节点2只需要重新映射Token2到节点2,就可以完成,无需做数据的读取与写入的搬迁动作,实现分钟级计算扩容,相比开源扩容时间提升几十倍。随着业务的不断增长,Cassandra可以分钟级水平弹性资源扩展。在类似圣诞节等热门节日,提前1天进行弹性扩容,为业务高峰预留资源,业务高峰过后进行缩容,这些对业务无感知。计算节点可以通过文件系统控制集群在DFV中的数据使用量,扩容缩容磁盘时通过重新分配最大使用量,可实现秒级存储扩容,单实例支持海量数据存储。
高性能:超高写入,读性能数倍提升
GaussDB(for Cassandra)在超强写入性能的基础上,通过使用C语言重构存储引擎,减少系统GC,实现了数倍读性能提升,拓宽了使用场景的外延,使其不仅仅适用于写密集型的业务场景,在读密集的场景中也具备了强竞争优势,整体性能超越开源自建2~3倍。
高安全:构筑多层保护,为数据安全保驾护航
GaussDB(for Cassandra)通过VPC、子网、安全组、DDoS防护以及SSL安全访问等多层安全防护体系,帮助用户抵御网络攻击,让用户上云无忧。
为什么选择GaussDB(for Cassandra)?
| 能力 |
技术能力对比 |
|
| 开源自建Cassandra |
GaussDB(for Cassandra) |
|
| 自动备份能力、PITR |
× |
√ |
| 超大数据量及复杂查询支持 |
× |
√ |
| 流表(数据变更捕获) |
× |
√ |
| 离线分析 |
不完善 |
√ |
| 高可靠:双向数据同步、无损升级 |
× |
√ |
| 分钟级扩容 |
× |
√ |
| 全局索引 |
不完善 |
√ |
| 数据强一致 |
× |
√ |
适用多种场景
工业制造&气象业
随着科技进度,采集的气象数据指数增长,需要一种系统对地面、高空、海洋、重要天气报、闪电、环境监测等卫星、雷达采集的数据能够高性能写入、查询、在线、离线分析。
- 需要存储对地面、高空、海洋、重要天气报、闪电、环境监测等卫星、雷达等降雨量、湿度、温度等PB级数据量
- 支撑来自各气象采集点数据高并发写入到Cassandra,GaussDB(for Cassandra)集群性能高于自建2~3倍,更适合高并发写入读取
- GaussDB(for Cassandra)数据能够支撑实时在线分析,为气象算法、天气预报做到实时精准分析
- 访问数据库进行离线数据分析,GaussDB(for Cassandra)能将离线分析时效缩短到60%
互联网
GaussDB(for Cassandra)具备高并发写入性能和高可扩展性,保障集群高可用和业务连续稳定性,非常适用于写入规模量较大的互联网大数据场景,如记录大规模的用户行为数据等。
- 存放用户画像数据,能够完美解决特征:数据量大、可以应对数据结构Scheme频繁变更
- 查询性能要求高;比如要买一双鞋,搜索出的鞋子数据会根据用户画像的特征做一定的排序展示,那么要求查询用户特征表的查询性能非常高
- 推荐系统:根据用户最近浏览的数据做分析之后,推荐相关资源给用户
- 点赞系统:点赞计数系统
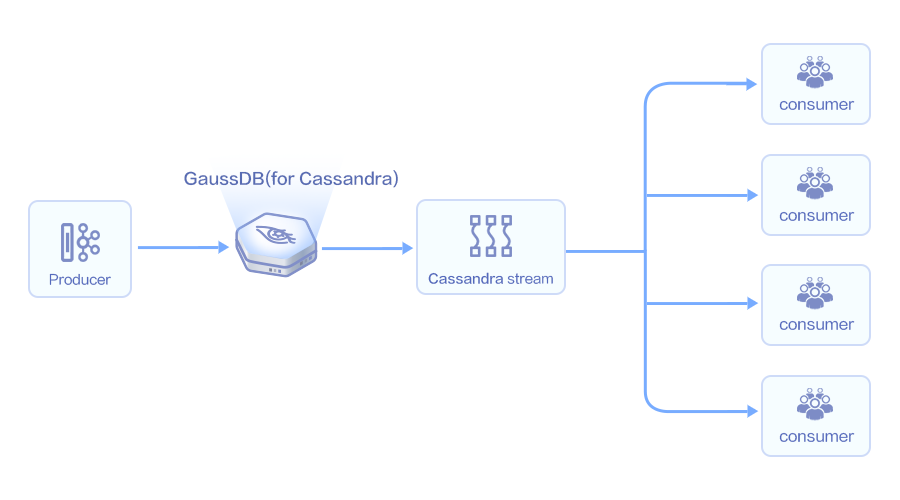
实时数据分析场景
GaussDB(for Cassandra)群组今天新来了一个成员,或者yutou今天发布一篇新文章,华为云数据库官方自动向该用户发出欢迎邮件。
昵称为yutou的同学今天发布了一组新照片,那么另外一个程序自动向yutou的好友发送通知。
原生不具备的数据变更捕获能力,GaussDB(for Cassandra)具有变更捕获能力,能对数据的变更做实时在线分析,提供秒级的实时推送动作做出相应处理;具有完善的离线分析解决方案,可以将离线分析时效缩短到60%,为商家争取更多的时间做出相应决策。
购买建议
GaussDB(for Cassandra)性能为开源2倍以上,存储空间仅需开源自建1/3,帮助客户节省成本,举例如下:开源自建8u32g * 3节点 数据量:90G(三副本),购买GaussDB(for Cassandra)可选择创建4u16g * 3节点 数据量:30G(DFV存储三副本)
本文作者:华为云GaussDB(for Cassandra)团队
产品首页:
GaussDB for Cassandra-华为云https://www.huaweicloud.cn/product/gaussdbforcassandra.html
欢迎加入我们!
华为云GaussDB(for Cassandra)团队(深圳、西安、杭州)zhaojuan.zhao@huawei.com

- 点赞
- 收藏
- 关注作者
评论(0)