使用 plt.scatter() 在 Python 中可视化数据【生长吧!Python!】

目录
处理数据的一个重要部分是能够将其可视化。Python 有多个可用于数据可视化的第三方模块。最受欢迎的模块之一是Matplotlib及其子模块pyplot,通常使用别名来引用plt。Matplotlib 提供了一个非常通用的工具plt.scatter(),它允许您创建基本和更复杂的散点图。
下面,您将通过几个示例向您展示如何有效地使用该功能。
在本教程中,您将学习如何:
- 创建散点图使用
plt.scatter() - 使用必需和可选的输入参数
- 为基本和更高级的图自定义散点图
- 在散点图上表示两个以上的维度
要从本教程中获得最大收益,您应该熟悉Python 编程的基础知识以及NumPy及其ndarray对象的基础知识。您无需熟悉 Matplotlib 即可学习本教程,但如果您想了解有关该模块的更多信息,请查看Python Plotting With Matplotlib (Guide)。
创建散点图
甲散点图是两个如何的视觉表示的变量之间的相互关系。您可以使用散点图来探索两个变量之间的关系,例如通过查找它们之间的任何相关性。
在本教程的这一部分中,您将熟悉使用 Matplotlib 创建基本散点图。在后面的部分中,您将学习如何进一步自定义绘图以使用两个以上的维度来表示更复杂的数据。
入门 plt.scatter()
在开始使用 之前plt.scatter(),您需要安装 Matplotlib。您可以使用 Python 的标准包管理器pip,通过在控制台中运行以下命令来执行此操作:
$ python -m pip install matplotlib现在您已经安装了 Matplotlib,请考虑以下用例。一家咖啡馆出售六种不同类型的瓶装橙汁饮料。店主想了解饮品的价格与他每款售出多少杯之间的关系,因此他会记录每天每款售出多少杯。您可以将这种关系可视化如下:
import matplotlib.pyplot as plt
price = [2.50, 1.23, 4.02, 3.25, 5.00, 4.40]
sales_per_day = [34, 62, 49, 22, 13, 19]
plt.scatter(price, sales_per_day)
plt.show()在此Python脚本,你导入的pyplot使用别名从Matplotlib子模块plt。该别名通常按惯例用于缩短模块和子模块名称。然后,您可以为所售出的六种橙色饮料中的每一种创建包含价格和每天平均销售额的列表。
最后,您通过使用plt.scatter()您希望比较的两个变量作为输入参数来创建散点图。当您使用 Python 脚本时,您还需要使用plt.show().
当您使用交互式环境时,例如控制台或Jupyter Notebook,您不需要调用plt.show(). 在本教程中,所有示例都将采用脚本的形式,并将包括对plt.show().
这是此代码的输出:
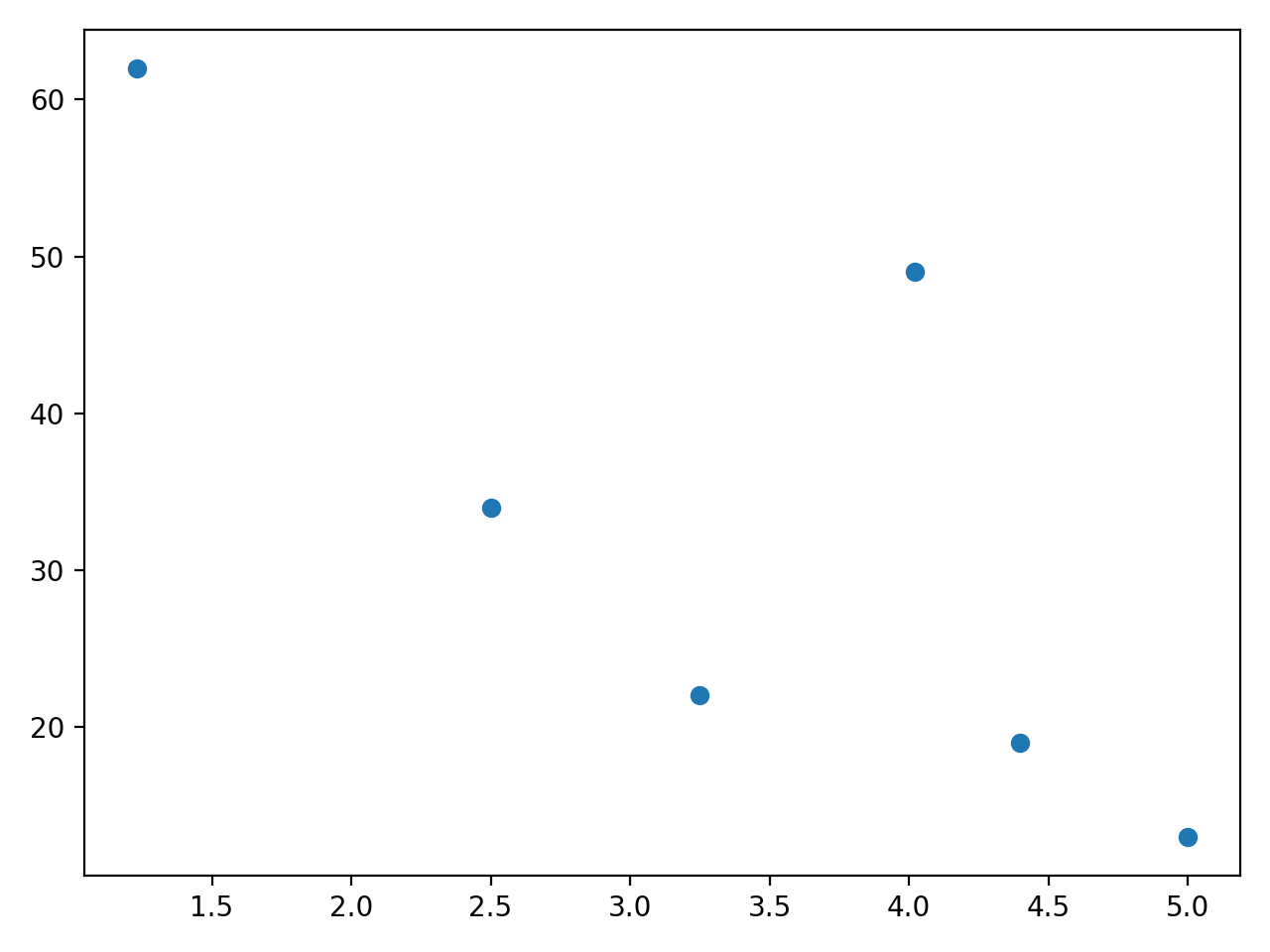
该图显示,一般来说,饮料越贵,售出的商品就越少。然而,售价 4.02 美元的饮料是一个异常值,这可能表明它是一种特别受欢迎的产品。以这种方式使用散点图时,仔细检查可以帮助您探索变量之间的关系。然后您可以进行进一步的分析,无论是使用线性回归还是其他技术。
比较plt.scatter()和plt.plot()
您还可以使用 中的另一个函数生成上面显示的散点图matplotlib.pyplot。Matplotlibplt.plot()是一个通用绘图函数,可让您创建各种不同的线图或标记图。
您可以plt.plot()使用相同的数据通过以下对 的调用获得与您在上一节中获得的散点图相同的散点图:
plt.plot(price, sales_per_day, "o")
plt.show()在这种情况下,您必须将标记"o"作为第三个参数包含在内,否则plt.plot()将绘制折线图。您使用此代码创建的绘图与您之前使用plt.scatter().
在某些情况下,对于您在此示例中绘制的基本散点图,使用plt.plot()可能更可取。您可以使用timeit模块比较两个函数的效率:
import timeit
import matplotlib.pyplot as plt
price = [2.50, 1.23, 4.02, 3.25, 5.00, 4.40]
sales_per_day = [34, 62, 49, 22, 13, 19]
print(
"plt.scatter()",
timeit.timeit(
"plt.scatter(price, sales_per_day)",
number=1000,
globals=globals(),
),
)
print(
"plt.plot()",
timeit.timeit(
"plt.plot(price, sales_per_day, 'o')",
number=1000,
globals=globals(),
),
)不同计算机上的性能会有所不同,但是当您运行此代码时,您会发现它plt.plot()比plt.scatter(). 在我的系统上运行上面的示例时,plt.plot()速度提高了七倍以上。
如果您可以使用 来创建散点图plt.plot(),而且速度也快得多,为什么还要使用plt.scatter()?您将在本教程的其余部分找到答案。您将在本教程中学到的大多数自定义和高级用法只有在使用plt.scatter(). 以下是您可以使用的经验法则:
- 如果您需要基本散点图,请使用
plt.plot(),尤其是在您想优先考虑性能时。 - 如果要使用更高级的绘图功能自定义散点图,请使用
plt.scatter().
在下一节中,您将开始探索plt.scatter().
自定义散点图中的标记
您可以通过自定义标记在二维散点图上可视化两个以上的变量。散点图中使用的标记有四个主要功能,您可以使用它们进行自定义plt.scatter():
- 尺寸
- 颜色
- 形状
- 透明度
在本教程的这一部分,您将学习如何修改所有这些属性。
改变大小
让我们回到您在本教程前面遇到的咖啡馆老板。他销售的不同橙汁来自不同的供应商,利润率也不同。您可以通过调整标记的大小在散点图中显示此附加信息。在此示例中,利润率以百分比形式给出:
import matplotlib.pyplot as plt
import numpy as np
price = np.asarray([2.50, 1.23, 4.02, 3.25, 5.00, 4.40])
sales_per_day = np.asarray([34, 62, 49, 22, 13, 19])
profit_margin = np.asarray([20, 35, 40, 20, 27.5, 15])
plt.scatter(x=price, y=sales_per_day, s=profit_margin * 10)
plt.show()您可以注意到第一个示例中的一些更改。您现在使用的是NumPy 数组而不是列表。您可以对数据使用任何类似数组的数据结构,而 NumPy 数组通常用于这些类型的应用程序,因为它们支持高效执行的逐元素操作。NumPy 模块是 Matplotlib 的一个依赖项,这就是您不需要手动安装它的原因。
您还使用命名参数作为函数调用中的输入参数。参数x和y是必需的,但所有其他参数都是可选的。
该参数s表示标记的大小。在此示例中,您使用利润率作为变量来确定标记的大小,然后乘以它10以更清楚地显示大小差异。
您可以在下面看到此代码创建的散点图:
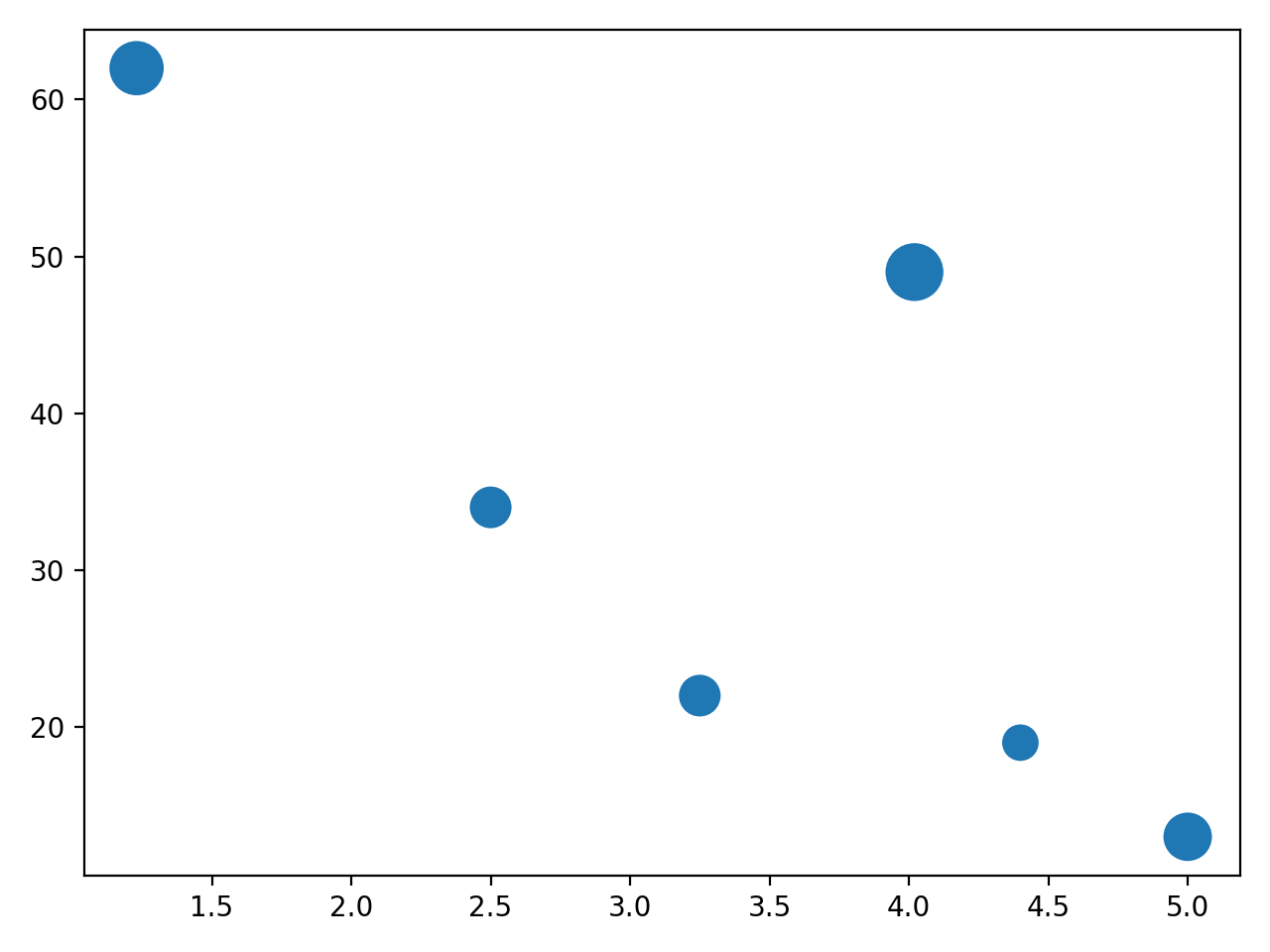
标记的大小表示每个产品的利润率。销量最高的两种橙汁饮料也是利润率最高的。这对咖啡馆老板来说是个好消息!
改变颜色
咖啡馆的许多顾客喜欢仔细阅读标签,尤其是要了解他们购买的饮料的含糖量。咖啡馆老板想在下一次营销活动中强调他对健康食品的选择,因此他根据含糖量对饮料进行分类,并使用交通灯系统来指示饮料的低、中或高糖含量。
您可以为散点图中的标记添加颜色以显示每种饮料的糖含量:
# ...
low = (0, 1, 0)
medium = (1, 1, 0)
high = (1, 0, 0)
sugar_content = [low, high, medium, medium, high, low]
plt.scatter(
x=price,
y=sales_per_day,
s=profit_margin * 10,
c=sugar_content,
)
plt.show()您将变量low、medium和定义high为元组,每个元组包含三个值,依次代表红色、绿色和蓝色分量。这些是RGB 颜色值。对于元组low,medium和high绿色,黄色和红色,分别代表。
然后您定义了变量sugar_content来对每种饮料进行分类。您可以c在函数调用中使用可选参数来定义每个标记的颜色。这是此代码生成的散点图:
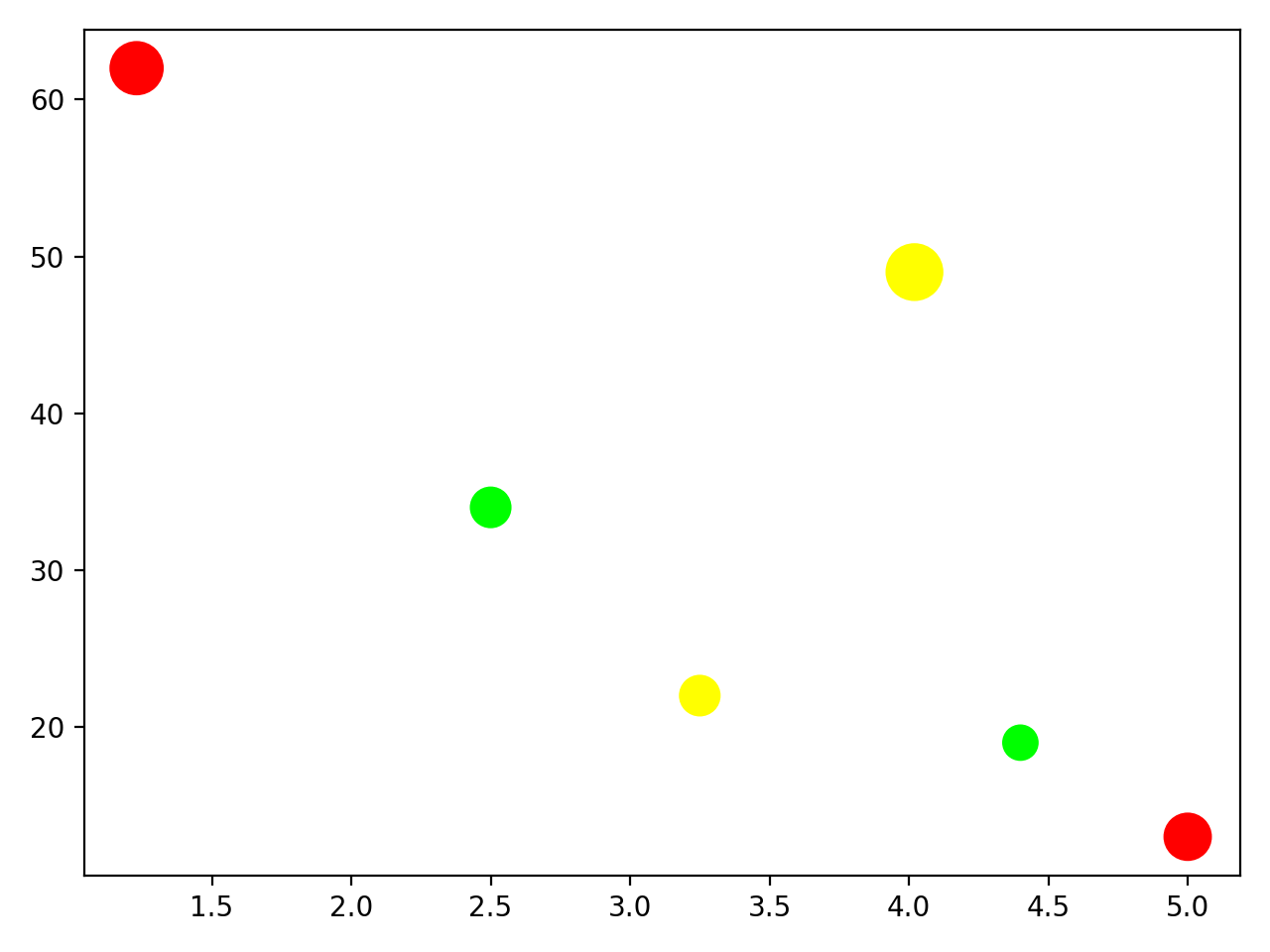
咖啡馆老板已经决定从菜单中删除最昂贵的饮料,因为它卖得不好,而且含糖量高。他是否也应该停止储存最便宜的饮料以提高企业的健康资质,即使它卖得很好并且利润率很高?
改变形状
咖啡馆老板发现这个练习非常有用,他想研究另一种产品。除了橙汁饮料,您现在还可以绘制咖啡馆中可用谷物棒范围的类似数据:
import matplotlib.pyplot as plt
import numpy as np
low = (0, 1, 0)
medium = (1, 1, 0)
high = (1, 0, 0)
price_orange = np.asarray([2.50, 1.23, 4.02, 3.25, 5.00, 4.40])
sales_per_day_orange = np.asarray([34, 62, 49, 22, 13, 19])
profit_margin_orange = np.asarray([20, 35, 40, 20, 27.5, 15])
sugar_content_orange = [low, high, medium, medium, high, low]
price_cereal = np.asarray([1.50, 2.50, 1.15, 1.95])
sales_per_day_cereal = np.asarray([67, 34, 36, 12])
profit_margin_cereal = np.asarray([20, 42.5, 33.3, 18])
sugar_content_cereal = [low, high, medium, low]
plt.scatter(
x=price_orange,
y=sales_per_day_orange,
s=profit_margin_orange * 10,
c=sugar_content_orange,
)
plt.scatter(
x=price_cereal,
y=sales_per_day_cereal,
s=profit_margin_cereal * 10,
c=sugar_content_cereal,
)
plt.show()在此代码中,您重构变量名称以考虑您现在拥有两种不同产品的数据。然后在一个图中绘制两个散点图。这给出了以下输出:
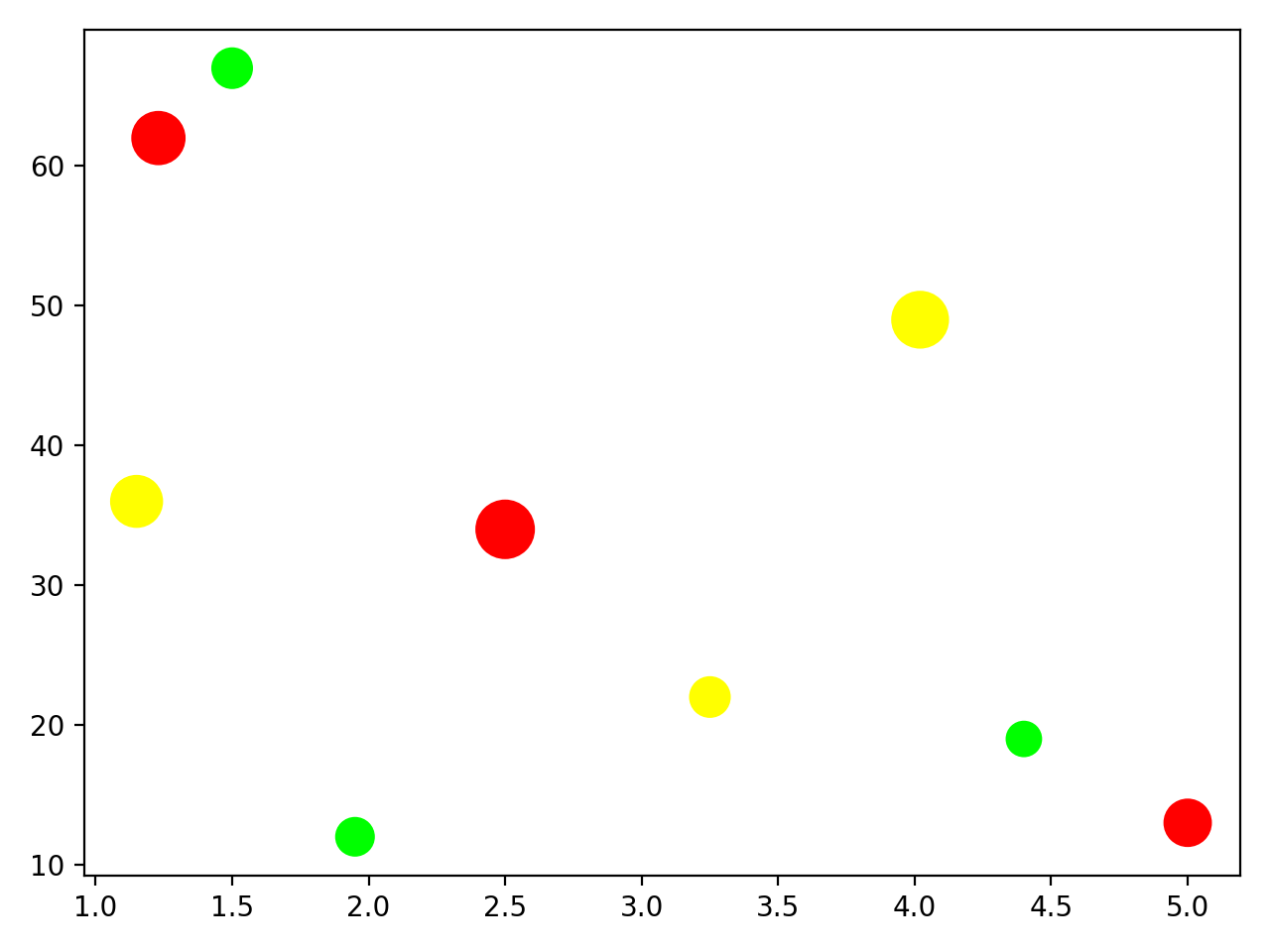
不幸的是,您无法再弄清楚哪些数据点属于橙汁饮料,哪些属于谷物棒。您可以更改散点图之一的标记形状:
import matplotlib.pyplot as plt
import numpy as np
low = (0, 1, 0)
medium = (1, 1, 0)
high = (1, 0, 0)
price_orange = np.asarray([2.50, 1.23, 4.02, 3.25, 5.00, 4.40])
sales_per_day_orange = np.asarray([34, 62, 49, 22, 13, 19])
profit_margin_orange = np.asarray([20, 35, 40, 20, 27.5, 15])
sugar_content_orange = [low, high, medium, medium, high, low]
price_cereal = np.asarray([1.50, 2.50, 1.15, 1.95])
sales_per_day_cereal = np.asarray([67, 34, 36, 12])
profit_margin_cereal = np.asarray([20, 42.5, 33.3, 18])
sugar_content_cereal = [low, high, medium, low]
plt.scatter(
x=price_orange,
y=sales_per_day_orange,
s=profit_margin_orange * 10,
c=sugar_content_orange,
)
plt.scatter(
x=price_cereal,
y=sales_per_day_cereal,
s=profit_margin_cereal * 10,
c=sugar_content_cereal,
marker="d",
)
plt.show()您保留橙色饮料数据的默认标记形状。默认标记是"o",它代表一个点。对于谷物棒数据,您将标记形状设置为"d",代表菱形标记。您可以在标记的文档页面中找到可以使用的所有标记的列表。这是叠加在同一图上的两个散点图:
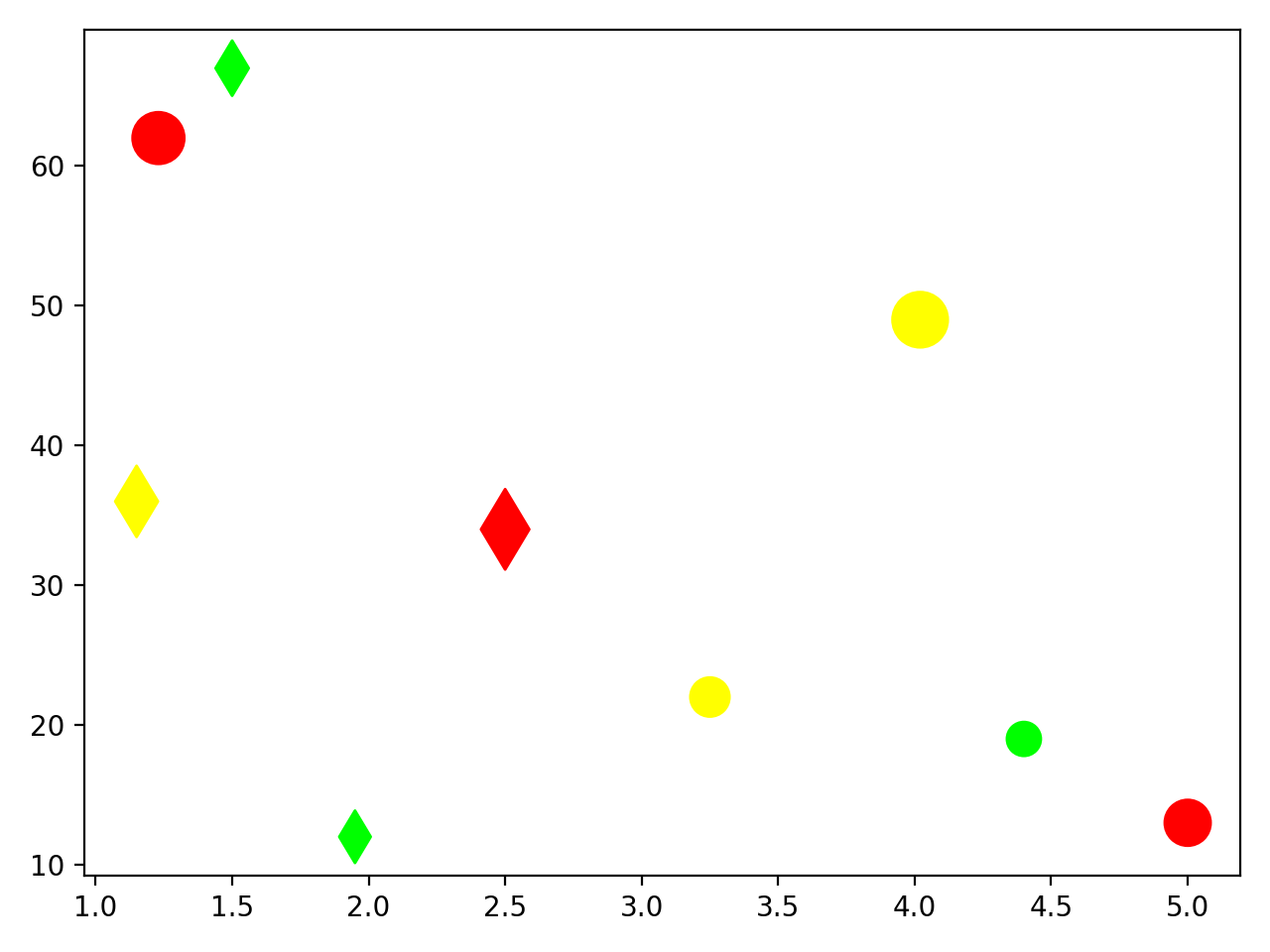
您现在可以将橙汁饮料的数据点与谷物棒的数据点区分开来。但是您创建的最后一个图存在一个问题,您将在下一节中探讨。
更改透明度
橙色饮料的数据点之一已经消失。应该有六个橙汁饮料,但图中只能看到五个圆形标记。麦片棒数据点之一是隐藏橙汁饮料数据点。
您可以通过使用alpha 值使数据点部分透明来解决此可视化问题:
# ...
plt.scatter(
x=price_orange,
y=sales_per_day_orange,
s=profit_margin_orange * 10,
c=sugar_content_orange,
alpha=0.5,
)
plt.scatter(
x=price_cereal,
y=sales_per_day_cereal,
s=profit_margin_cereal * 10,
c=sugar_content_cereal,
marker="d",
alpha=0.5,
)
plt.title("Sales vs Prices for Orange Drinks and Cereal Bars")
plt.legend(["Orange Drinks", "Cereal Bars"])
plt.xlabel("Price (Currency Unit)")
plt.ylabel("Average weekly sales")
plt.text(
3.2,
55,
"Size of marker = profit margin\n" "Color of marker = sugar content",
)
plt.show()您已将alpha两组标记的值设置为0.5,这意味着它们是半透明的。您现在可以看到此图中的所有数据点,包括那些重合的数据点:
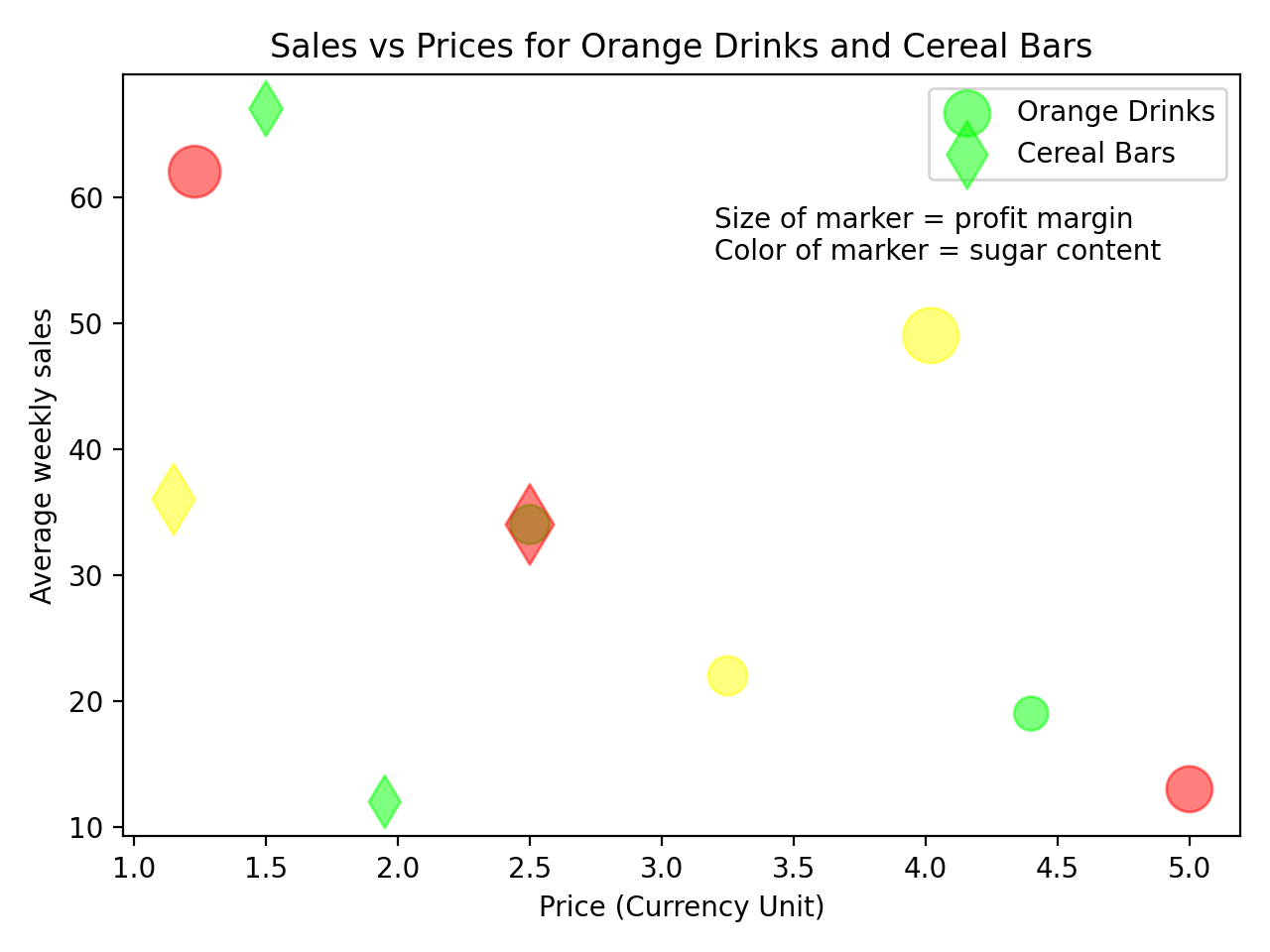
您还向图中添加了标题和其他标签,以使用有关所显示内容的更多信息来完成图。
自定义颜色图和样式
在您目前创建的散点图中,您使用了三种颜色来表示饮料和谷物棒的低、中或高糖含量。您现在将更改它,以便颜色直接代表项目的实际糖含量。
您首先需要重构变量sugar_content_orange,sugar_content_cereal以便它们代表糖含量值而不仅仅是 RGB 颜色值:
sugar_content_orange = [15, 35, 22, 27, 38, 14]
sugar_content_cereal = [21, 49, 29, 24]这些现在是包含每个项目中每日推荐糖量百分比的列表。其余代码保持不变,但您现在可以选择要使用的颜色图。这将值映射到颜色:
# ...
plt.scatter(
x=price_orange,
y=sales_per_day_orange,
s=profit_margin_orange * 10,
c=sugar_content_orange,
cmap="jet",
alpha=0.5,
)
plt.scatter(
x=price_cereal,
y=sales_per_day_cereal,
s=profit_margin_cereal * 10,
c=sugar_content_cereal,
cmap="jet",
marker="d",
alpha=0.5,
)
plt.title("Sales vs Prices for Orange Drinks and Cereal Bars")
plt.legend(["Orange Drinks", "Cereal Bars"])
plt.xlabel("Price (Currency Unit)")
plt.ylabel("Average weekly sales")
plt.text(
2.7,
55,
"Size of marker = profit margin\n" "Color of marker = sugar content",
)
plt.colorbar()
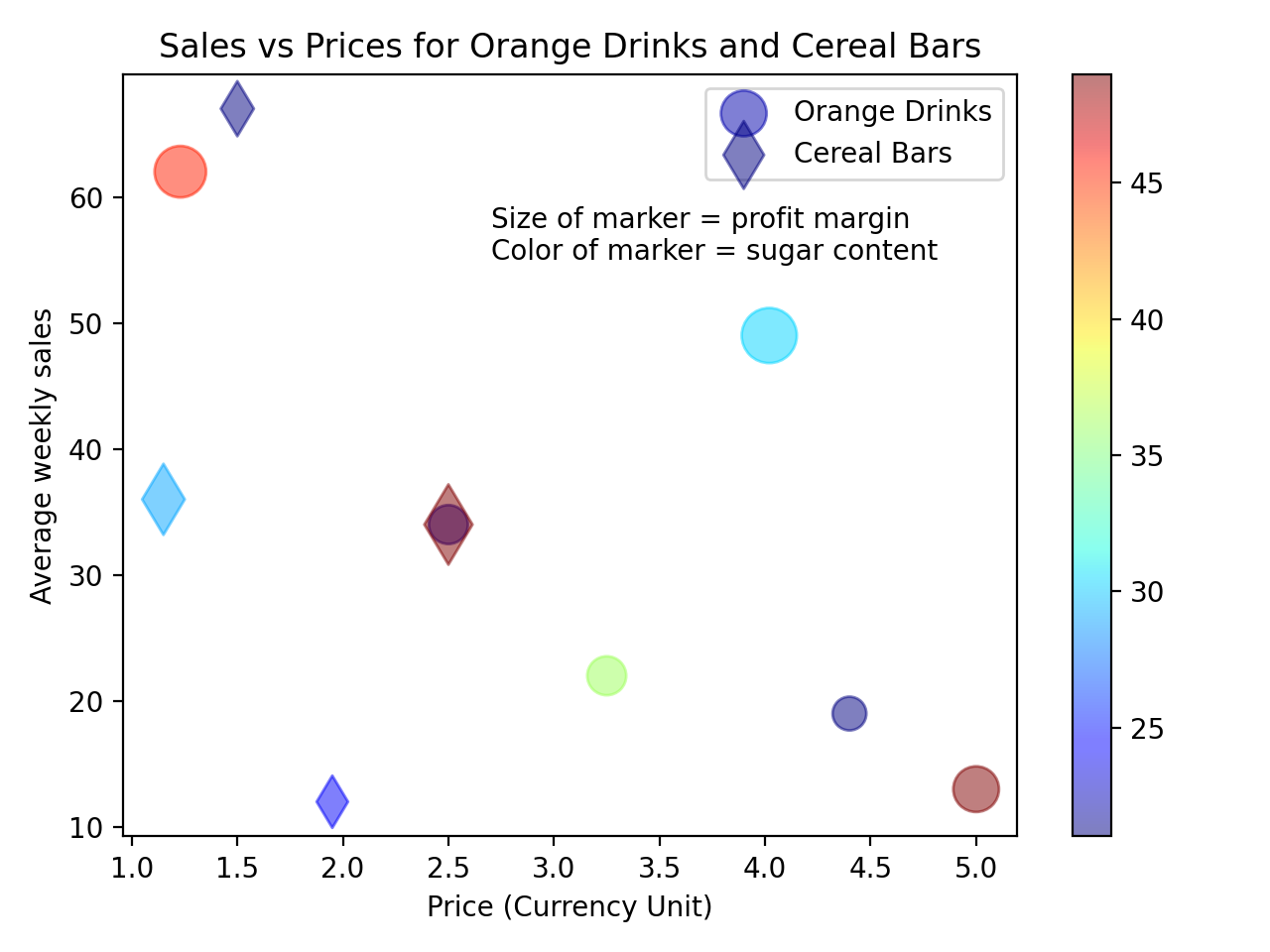
plt.show()标记的颜色现在是基于一个连续的规模,你还展示了彩条充当标记的色彩的传奇人物。这是生成的散点图:
到目前为止,您绘制的所有图都以原生 Matplotlib 样式显示。您可以使用多个选项之一更改此样式。您可以使用以下命令显示可用样式:
>>> plt.style.available
[
"Solarize_Light2",
"_classic_test_patch",
"bmh",
"classic",
"dark_background",
"fast",
"fivethirtyeight",
"ggplot",
"grayscale",
"seaborn",
"seaborn-bright",
"seaborn-colorblind",
"seaborn-dark",
"seaborn-dark-palette",
"seaborn-darkgrid",
"seaborn-deep",
"seaborn-muted",
"seaborn-notebook",
"seaborn-paper",
"seaborn-pastel",
"seaborn-poster",
"seaborn-talk",
"seaborn-ticks",
"seaborn-white",
"seaborn-whitegrid",
"tableau-colorblind10",
]您现在可以在使用 Matplotlib 时更改绘图样式,方法是在调用之前使用以下函数调用plt.scatter():
import matplotlib.pyplot as plt
import numpy as np
plt.style.use("seaborn")
# ...这将样式更改为另一个第三方可视化包Seaborn的样式。您可以通过使用 Seaborn 样式绘制上面显示的最终散点图来查看不同的样式:
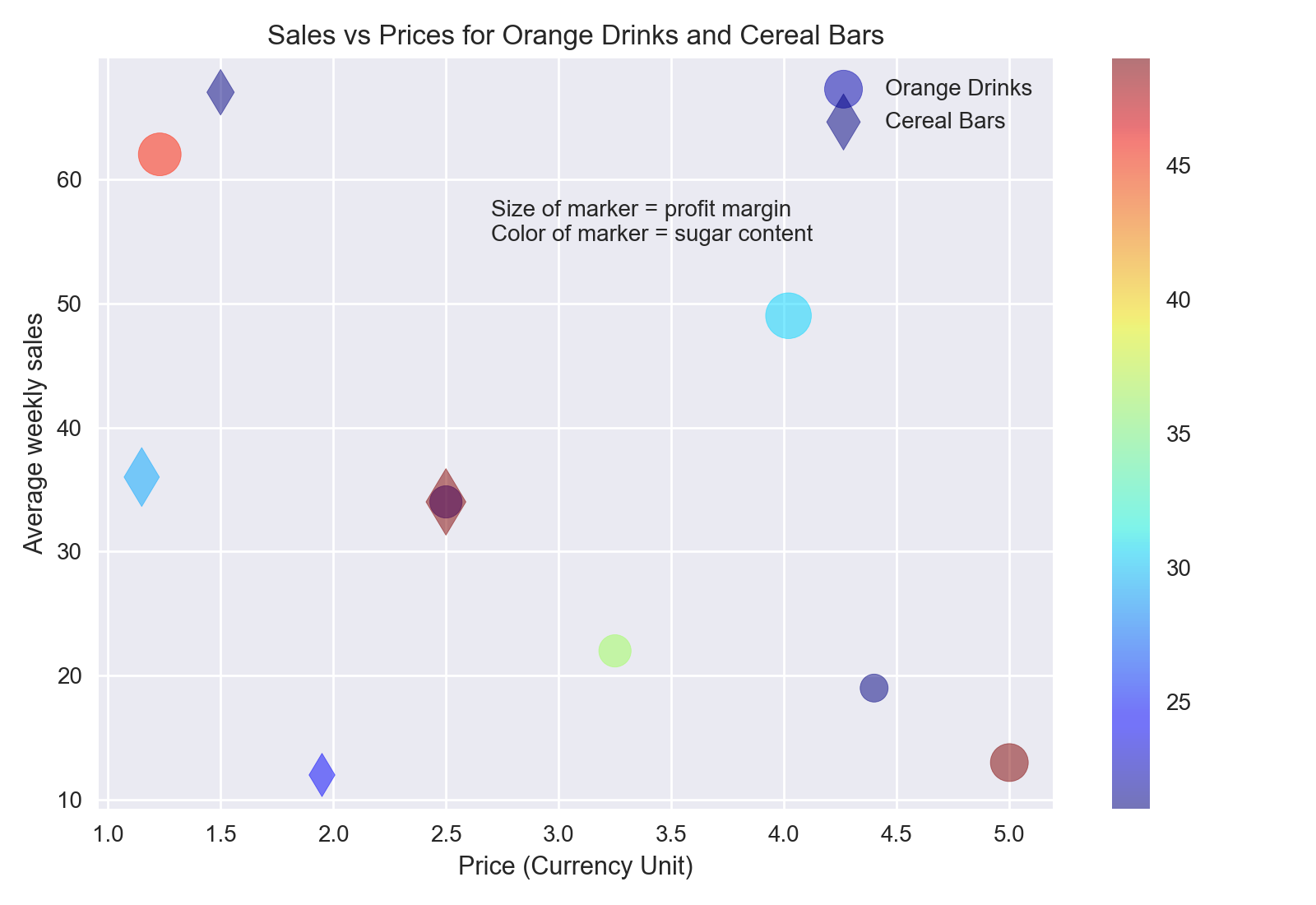
您可以阅读有关在 Matplotlib 中自定义绘图的更多信息,并且在Matplotlib 文档页面上还有更多教程。
使用plt.scatter()创建散点图可以显示两个以上的变量。以下是此示例中表示的变量:
| 多变的 | 代表人 |
|---|---|
| 价格 | X轴 |
| 平均销售数量 | Y轴 |
| 利润率 | 标记尺寸 |
| 产品类别 | 标记形状 |
| 含糖量 | 标记颜色 |
表示两个以上变量的能力是plt.scatter()一个非常强大和通用的工具。
plt.scatter进一步探索()
plt.scatter()在自定义散点图方面提供了更大的灵活性。在本节中,您将通过一个示例探索如何使用 NumPy 数组和散点图来屏蔽数据。在此示例中,您将生成随机数据点,然后将它们分成同一散点图中的两个不同区域。
一位热衷于收集数据的通勤者在六个月的时间里整理了她当地公交车站的公交车到达时间。时间表上的到达时间是一小时后的 15 分钟和 45 分钟,但她注意到真正的到达时间遵循以下时间的正态分布:
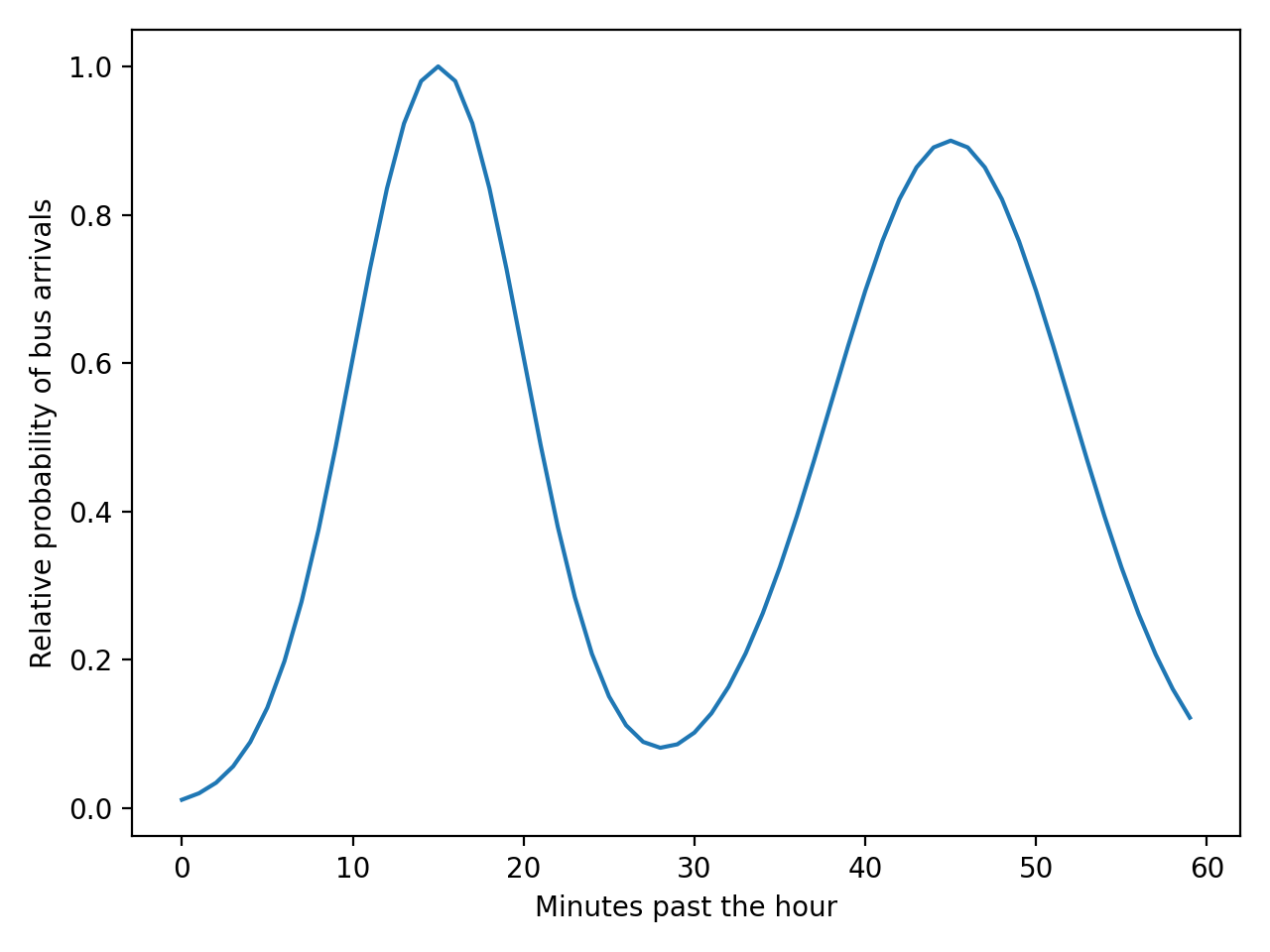
此图显示了公交车在一小时内每分钟到达的相对可能性。这个概率分布可以用 NumPy 和 来表示np.linspace():
import matplotlib.pyplot as plt
import numpy as np
mean = 15, 45
sd = 5, 7
x = np.linspace(0, 59, 60) # Represents each minute within the hour
first_distribution = np.exp(-0.5 * ((x - mean[0]) / sd[0]) ** 2)
second_distribution = 0.9 * np.exp(-0.5 * ((x - mean[1]) / sd[1]) ** 2)
y = first_distribution + second_distribution
y = y / max(y)
plt.plot(x, y)
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()
您已经创建了两个以小时为中心的正态分布,15并将45它们相加。您将最可能的到达时间设置为1除以最大值后的值。
您现在可以使用此分布模拟公交车到达时间。为此,您可以使用内置random模块创建随机时间和随机相对概率。在下面的代码中,您还将使用列表推导式:
import random
import matplotlib.pyplot as plt
import numpy as np
n_buses = 40
bus_times = np.asarray([random.randint(0, 59) for _ in range(n_buses)])
bus_likelihood = np.asarray([random.random() for _ in range(n_buses)])
plt.scatter(x=bus_times, y=bus_likelihood)
plt.title("Randomly chosen bus arrival times and relative probabilities")
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()您已经模拟了40公交车到达,您可以使用以下散点图对其进行可视化:
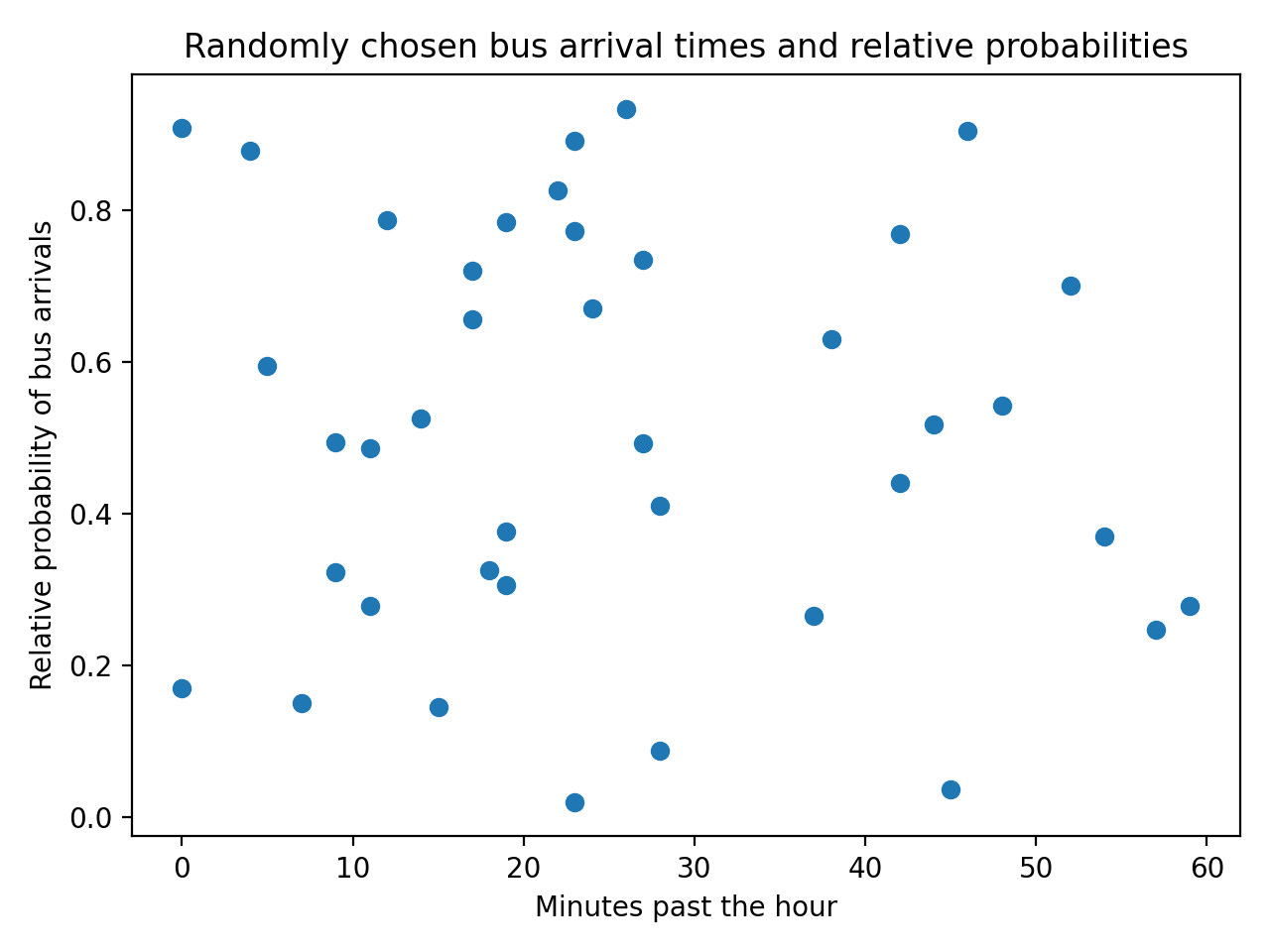
由于您生成的数据是随机的,因此您的绘图看起来会有所不同。然而,并非所有这些点都可能接近通勤者从她收集和分析的数据中观察到的现实。您可以绘制她从模拟公交车到站数据中获得的分布:
import random
import matplotlib.pyplot as plt
import numpy as np
mean = 15, 45
sd = 5, 7
x = np.linspace(0, 59, 60)
first_distribution = np.exp(-0.5 * ((x - mean[0]) / sd[0]) ** 2)
second_distribution = 0.9 * np.exp(-0.5 * ((x - mean[1]) / sd[1]) ** 2)
y = first_distribution + second_distribution
y = y / max(y)
n_buses = 40
bus_times = np.asarray([random.randint(0, 59) for _ in range(n_buses)])
bus_likelihood = np.asarray([random.random() for _ in range(n_buses)])
plt.scatter(x=bus_times, y=bus_likelihood)
plt.plot(x, y)
plt.title("Randomly chosen bus arrival times and relative probabilities")
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()
这给出了以下输出:
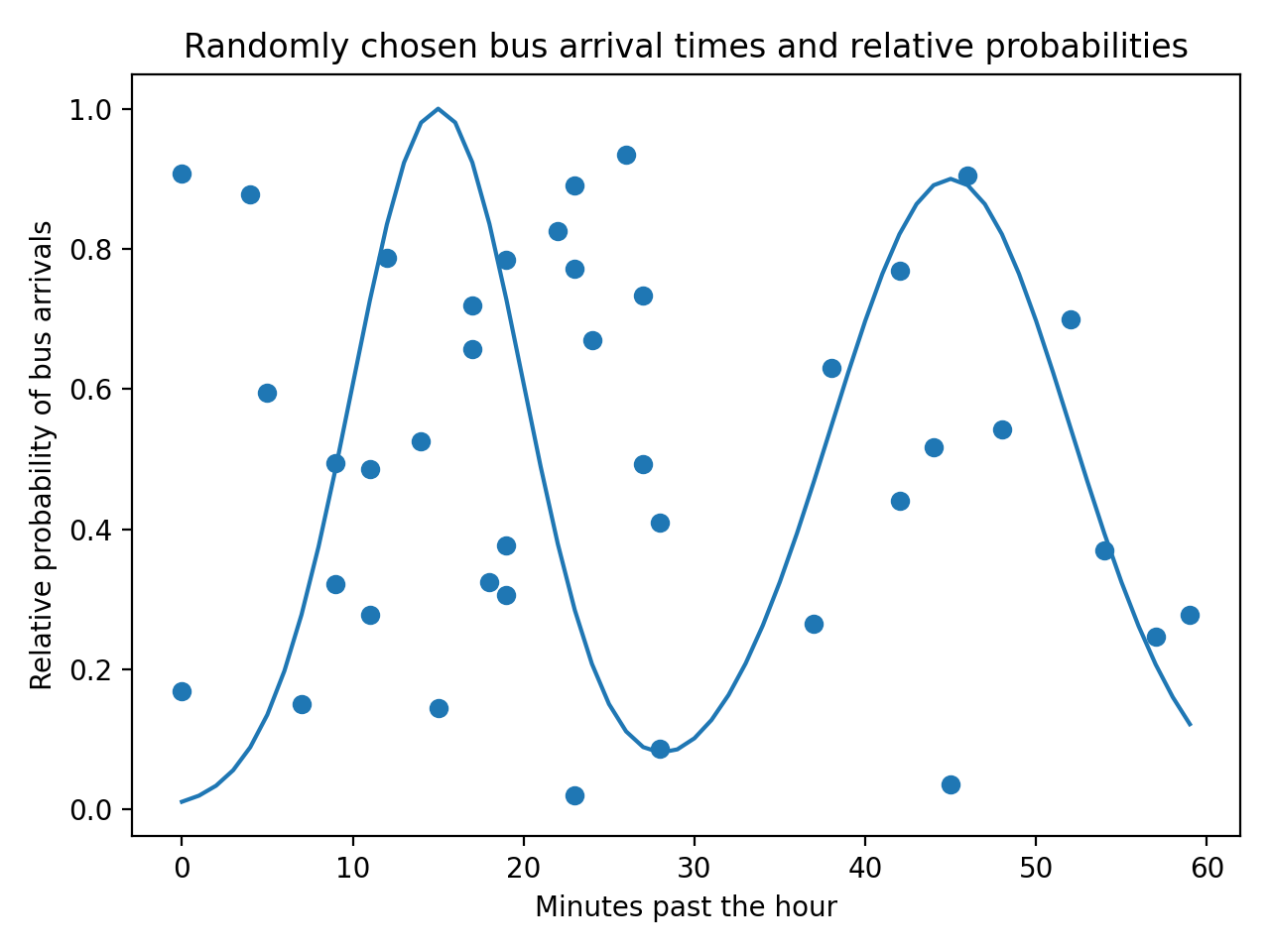
为了使模拟保持真实,您需要确保随机到达的公交车与数据以及从这些数据中获得的分布相匹配。您可以通过仅保留落在概率分布内的点来过滤随机生成的点。您可以通过为散点图创建掩码来实现此目的:
# ...
in_region = bus_likelihood < y[bus_times]
out_region = bus_likelihood >= y[bus_times]
plt.scatter(
x=bus_times[in_region],
y=bus_likelihood[in_region],
color="green",
)
plt.scatter(
x=bus_times[out_region],
y=bus_likelihood[out_region],
color="red",
marker="x",
)
plt.plot(x, y)
plt.title("Randomly chosen bus arrival times and relative probabilities")
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()变量in_region和out_region是包含布尔值的NumPy 数组,基于随机生成的似然是高于还是低于分布y。然后绘制两个单独的散点图,一个是分布在分布内的点,另一个是分布在分布外的点。落在分布之上的数据点不代表真实数据:
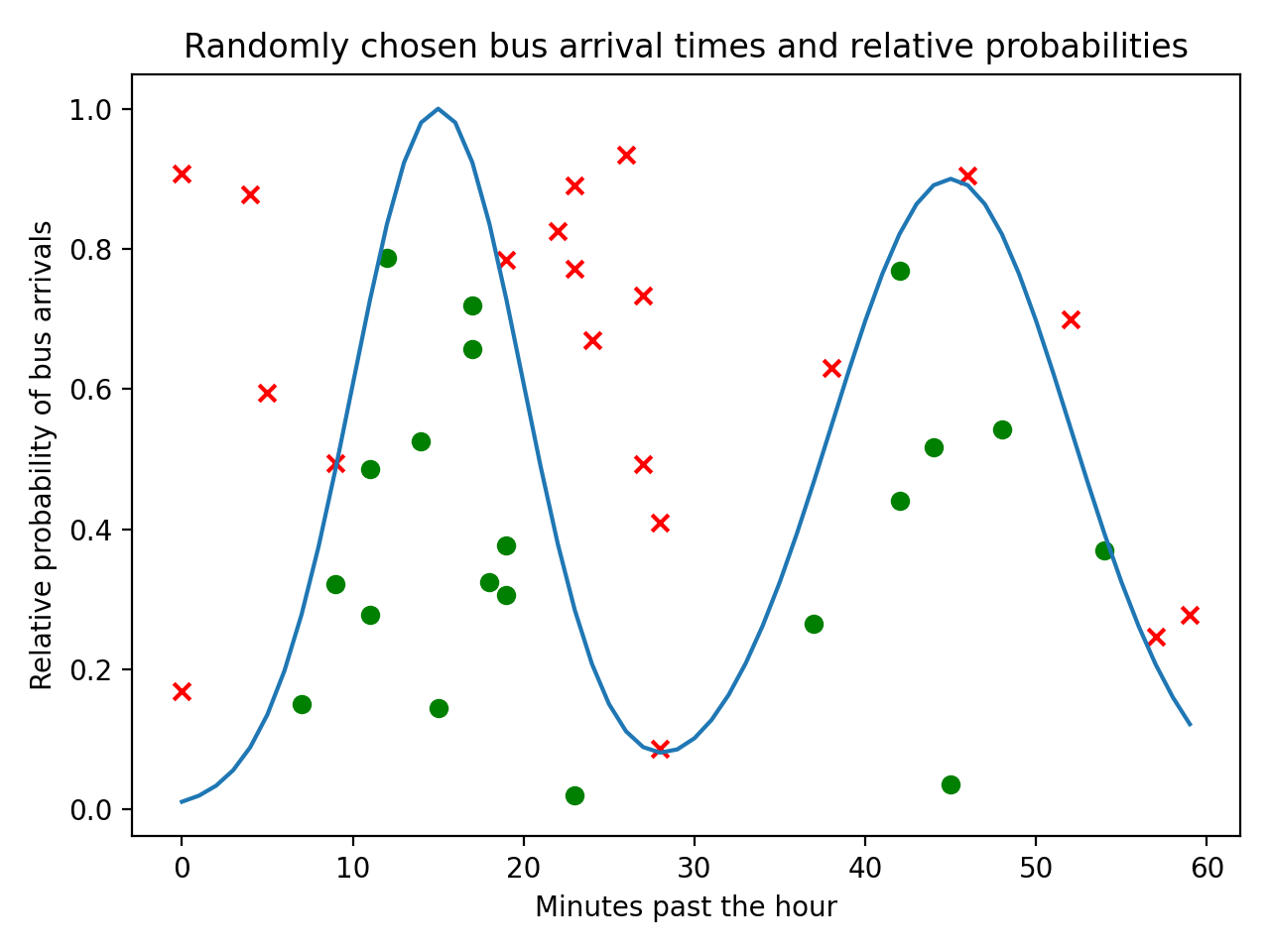
您已根据原始散点图中的数据点是否落在分布范围内对其进行分割,并使用不同的颜色和标记来识别两组数据。
查看关键输入参数
您已经在上面的部分中了解了用于创建散点图的主要输入参数。以下是关于主要输入参数要记住的要点的简要总结:
| 范围 | 描述 |
|---|---|
x 和 y |
这些参数代表两个主要变量,可以是任何类似数组的数据类型,例如列表或 NumPy 数组。这些是必需的参数。 |
s |
此参数定义标记的大小。如果所有标记具有相同的大小,则它可以是浮点数,如果标记具有不同的大小,则它可以是类似数组的数据结构。 |
c |
此参数表示标记的颜色。它通常是一个颜色数组,例如 RGB 值,或者是将使用参数映射到颜色图的值序列cmap。 |
marker |
该参数用于自定义标记的形状。 |
cmap |
如果参数使用一系列值c,则此参数可用于选择值和颜色之间的映射,通常使用标准颜色图或自定义颜色图之一。 |
alpha |
此参数是一个浮点数,可以在0和之间取任何值1,表示标记的透明度,其中1表示不透明标记。 |
这些不是唯一可用的输入参数plt.scatter()。您可以从文档中访问完整的输入参数列表。
结论
既然您知道如何使用 来创建和自定义散点图plt.scatter(),您就可以开始使用自己的数据集和示例进行练习了。这种多功能功能使您能够探索数据并以清晰的方式呈现您的发现。
在本教程中,您学习了如何:
- 使用()创建散点图
plt.scatter - 使用必需和可选的输入参数
- 为基本和更高级的图自定义散点图
- 代表两个以上的尺寸与
plt.scatter()
plt.scatter()通过详细了解 Matplotlib 中的所有功能并使用 NumPy 处理数据,您可以充分利用可视化。
【生长吧!Python】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/278897

- 点赞
- 收藏
- 关注作者
评论(0)