Logstash实现ES集群数据迁移实践

一、迁移方案说明
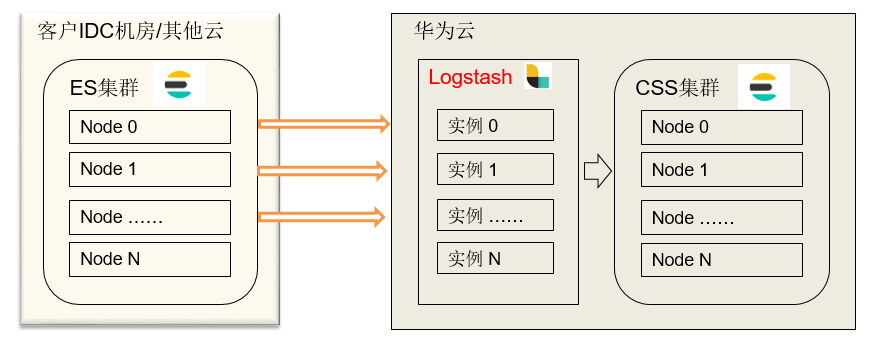
部署Logstash在华为云ECS上,Logstash ECS选择和CSS集群相同的VPC,同时Logstash需要配置大网访问权限,保证Logstash和原集群和目标集群互通。
数据迁移可以全量迁移和增量迁移,首次迁移都是全量迁移后续的增加数据选择增量迁移。增量迁移需要识别客户的增量数据,需要索引有时间戳标志。
迁移性能:
迁移数据读取采用query+sort,使用scroll导出数据;写入时使用_bulk API批量导入。性能数据受限于网络带宽、原集群读取数据速度、目标集群导入能力和Logstash的处理能力。如果用户需要快速导入可以水平扩展Logstash的数量,增加并发量。但是会使原集群承担较大查询压力,有影响业务正常的使用风险。
增量方案原理:
1.对于T时刻的数据,先使用Logstash将T以前的所有数据迁移到华为云ES,假设用时∆T
2.对于T到T+∆T的增量数据,再次使用logstash将数据导入到华为云的ES集群
3.重复上述步骤2,直到∆T足够小,此时将业务切换到华为云,最后完成新增数据的迁移
适用范围:ES的数据中带有时间戳或者其他能够区分新旧数据的标签
工作原理:
Logstash分为三个部分input 、filter、ouput
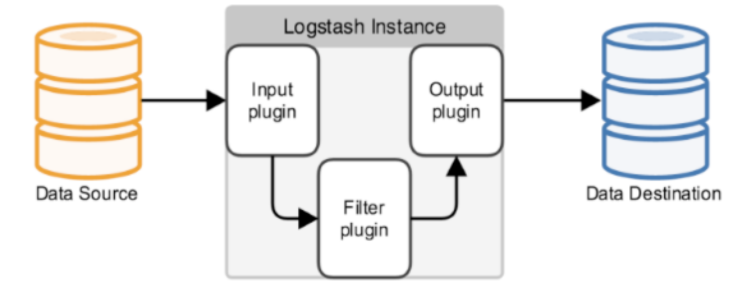
- input处理接收数据,数据可以来源ES,日志文件,kafka等通道.
- filter对数据进行过滤,清洗。
- ouput输出数据到目标设备,可以输出到ES,kafka,文件等。
迁移流程:
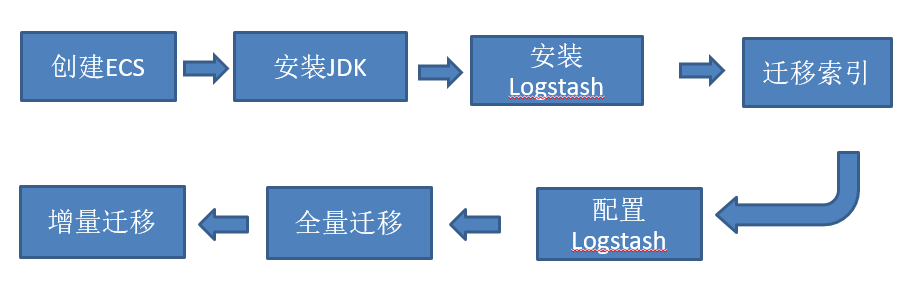
Logstash导入数据到ES参考官网操作指导:
https://support.huaweicloud.cn/usermanual-css/css_01_0048.html
二、迁移方案
安装Logstash:
目前华为云云搜索服务(CSS)已经支持开通Logstash服务,用户可以直接创建Logstash实例迁移数据即可。
如果用户需要自建Logstash,以下提供安装步骤。
- 创建ECS云服务器
登录华为云创建弹性云服务器,Logstash安装机器必须保证和迁移的原集群和目标集群互通。外网迁移需要配置云服务器的大网IP地址。

- 安装JDK
镜像源路径:https://repo.huaweicloud.cn/openjdk/
因为Logstash依赖java,需要先安装jdk。在华为镜像源下载对应版本的jdk,解压安装即可。
修改JDK Path:
# download Openjdk
wget https://repo.huaweicloud.cn/openjdk/11.0.2/openjdk-11.0.2_linux-x64_bin.tar.gz
#修改java path
vi /etc/profile
export JAVA_HOME=/root/jdk-11.0.2
export PATH="/root/jdk-11.0.2/bin:$PATH"
source /etc/profile
- 下载对应版本的Logstash
Logstash版本和ES版本不需要强制一致,一般选择和ES版本接近的Logstash版本。
选择华为云官网镜像源(https://mirrors.huaweicloud.cn/logstash/)下载Logstash版本:
镜像源中可以选择rpm和源码下载直接解压安装包安装。
[root@ecs-497d ~]# rpm -ivh logstash-7.6.2.rpm
warning: logstash-7.6.2.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:logstash-1:7.6.2-1 ################################# [100%]
- 配置/etc/logstash/jvm.options
修改对内存使用,logstash默认的堆内存是1G,根据ECS集群选择合适的内存,可以加快集群数据的迁移效率。
/config/jvm.options
-Xms4g
-Xmx4g
- 启动logstash开始集群数据迁移,启动前需要迁移索引和修改配置
创建Logstash配置文件,拷贝以上的配置,修改对应的参数,启动logstash开始迁移数据。
logstash "--path.settings" "/etc/logstash" -f logstash-simple.conf
索引迁移:
Logstash会帮助用户自动创建索引,但是自动创建的索引和用户本身的索引会有些许差异,导致最终数据的搜索格式不一致,一般索引需要手动创建,保证索引的数据完全一致。
以下提供创建索引的python脚本,用户可以使用该脚本创建需要的索引。
create_mapping.py文件是同步索引的python脚本,config.yaml是集群地址配置文件。
拷贝以下代码保存为 create_mapping.py:
import yaml
import requests
import json
import getopt
import sys
def help():
print
"""
usage:
-h/--help print this help.
-c/--config config file path, default is config.yaml
example:
python create_mapping.py -c config.yaml
"""
def process_mapping(index_mapping, dest_index):
print(index_mapping)
# remove unnecessary keys
del index_mapping["settings"]["index"]["provided_name"]
del index_mapping["settings"]["index"]["uuid"]
del index_mapping["settings"]["index"]["creation_date"]
del index_mapping["settings"]["index"]["version"]
# check alias
aliases = index_mapping["aliases"]
for alias in list(aliases.keys()):
if alias == dest_index:
print(
"source index " + dest_index + " alias " + alias + " is the same as dest_index name, will remove this alias.")
del index_mapping["aliases"][alias]
if index_mapping["settings"]["index"].has_key("lifecycle"):
lifecycle = index_mapping["settings"]["index"]["lifecycle"]
opendistro = {"opendistro": {"index_state_management":
{"policy_id": lifecycle["name"],
"rollover_alias": lifecycle["rollover_alias"]}}}
index_mapping["settings"].update(opendistro)
# index_mapping["settings"]["opendistro"]["index_state_management"]["rollover_alias"] = lifecycle["rollover_alias"]
del index_mapping["settings"]["index"]["lifecycle"]
print(index_mapping)
return index_mapping
def put_mapping_to_target(url, mapping, source_index, dest_auth=None):
headers = {'Content-Type': 'application/json'}
create_resp = requests.put(url, headers=headers, data=json.dumps(mapping), auth=dest_auth)
if create_resp.status_code != 200:
print(
"create index " + url + " failed with response: " + str(create_resp) + ", source index is " + source_index)
print(create_resp.text)
with open(source_index + ".json", "w") as f:
json.dump(mapping, f)
def main():
config_yaml = "config.yaml"
opts, args = getopt.getopt(sys.argv[1:], '-h-c:', ['help', 'config='])
for opt_name, opt_value in opts:
if opt_name in ('-h', '--help'):
help()
exit()
if opt_name in ('-c', '--config'):
config_yaml = opt_value
config_file = open(config_yaml)
config = yaml.load(config_file)
source = config["source"]
source_user = config["source_user"]
source_passwd = config["source_passwd"]
source_auth = None
if source_user != "":
source_auth = (source_user, source_passwd)
dest = config["destination"]
dest_user = config["destination_user"]
dest_passwd = config["destination_passwd"]
dest_auth = None
if dest_user != "":
dest_auth = (dest_user, dest_passwd)
print(source_auth)
print(dest_auth)
# only deal with mapping list
if config["only_mapping"]:
for source_index, dest_index in config["mapping"].iteritems():
print("start to process source index" + source_index + ", target index: " + dest_index)
source_url = source + "/" + source_index
response = requests.get(source_url, auth=source_auth)
if response.status_code != 200:
print("*** get ElasticSearch message failed. resp statusCode:" + str(
response.status_code) + " response is " + response.text)
continue
mapping = response.json()
index_mapping = process_mapping(mapping[source_index], dest_index)
dest_url = dest + "/" + dest_index
put_mapping_to_target(dest_url, index_mapping, source_index, dest_auth)
print("process source index " + source_index + " to target index " + dest_index + " successed.")
else:
# get all indices
response = requests.get(source + "/_alias", auth=source_auth)
if response.status_code != 200:
print("*** get all index failed. resp statusCode:" + str(
response.status_code) + " response is " + response.text)
exit()
all_index = response.json()
for index in list(all_index.keys()):
if index == ".kibana":
continue
print("start to process source index" + index)
source_url = source + "/" + index
index_response = requests.get(source_url, auth=source_auth)
if index_response.status_code != 200:
print("*** get ElasticSearch message failed. resp statusCode:" + str(
index_response.status_code) + " response is " + index_response.text)
continue
mapping = index_response.json()
dest_index = index
if index in config["mapping"].keys():
dest_index = config["mapping"][index]
index_mapping = process_mapping(mapping[index], dest_index)
dest_url = dest + "/" + dest_index
put_mapping_to_target(dest_url, index_mapping, index, dest_auth)
print("process source index " + index + " to target index " + dest_index + " successed.")
if __name__ == '__main__':
main()
拷贝以下配置保存为config.yaml:
# 源端ES集群地址,加上http://
source: http://localhost:9200
source_user: ""
source_passwd: ""
# 目的端ES集群地址,加上http://
destination: http://localhost:9200
destination_user: ""
destination_passwd: ""
# 是否只处理这个文件中mapping地址的索引
# 如果设置成true,则只会将下面的mapping中的索引获取到并在目的端创建
# 如果设置成false,则会取源端集群的所有索引,除去(.kibana)
# 并且将索引名称与下面的mapping匹配,如果匹配到使用mapping的value作为目的端的索引名称
# 如果匹配不到,则使用源端原始的索引名称
only_mapping: false
# 要迁移的索引,key为源端的索引名字,value为目的端的索引名字
mapping:
cs_short_video_3: cs_short_video
cs_music_1: cs_music
以上代码和配置文件准备完成,直接执行 python create_mapping.py 即可完成索引同步。
索引同步完成可以取目标集群的kibana上查看或者执行curl查看索引迁移情况:
curl http://x.x.x.x:9200/_cat/indices?v
配置文件中only_mapping设置true可以迁移指定索引。
源和目标集群如果没有密码可以不填。
Logstash全量迁移数据:
Logstash配置位于config目录下。
用户可以参考配置修改Logstash配置文件,为了保证迁移数据的准确性,一般建议建立多组Logstash,分批次迁移数据,每个Logstash迁移部分数据。
配置集群间迁移配置参考:
input{
elasticsearch{
# 源端地址
hosts => ["http://172.16.156.250:9200", "http://172.16.156.251:9200", "http://172.16.156.252:9200"]
# 安全集群配置登录用户名密码
user => "xxxx"
password => "xxxx"
# 需要迁移的索引列表,以逗号分隔
index => "abmau_edi*,business_test,goods_deploy*, -.kibana*"
# 以下三项保持默认即可,包含线程数和迁移数据大小和logstash jvm配置相关
docinfo=>true
slices => 10
size => 2000
}
}
filter {
# 去掉一些logstash自己加的字段
mutate {
remove_field => ["@timestamp", "@version"]
}
}
output{
elasticsearch{
# 目的端es地址
hosts => ["http://10.100.21.18:9200", "http://10.100.20.60:9200"]
# 目的端索引名称,以下配置为和源端保持一致
index => "%{[@metadata][_index]}"
# 目的端索引type,以下配置为和源端保持一致
document_type => "%{[@metadata][_type]}"
# 目标端数据的_id,如果不需要保留原_id,可以删除以下这行,删除后性能会更好
document_id => "%{[@metadata][_id]}"
ilm_enabled => false
manage_template => false
}
# 调试信息,正式迁移去掉
stdout { codec => rubydebug { metadata => true }}
}
Logstash增量迁移数据:
Logstash增量迁移需要数据增量标志,写出对应ES 的DLS query,可以查出查出增量数据。
开启Logstash定时任务即可触发增量迁移。
增量迁移配置参考:
input {
elasticsearch {
hosts => ["http://172.16.156.250:9200", "http://172.16.156.251:9200",
index => "es-runlog-2019.11.20"
query => '{"query":{"range":{"@timestamp":{"gte":"now-5m","lte":"now/m"}}}}'
size => 5000
scroll => "5m"
docinfo => true
schedule => "* * * * *" #定时任务,每分钟执行一次
}
}
filter {
mutate {
remove_field => ["source", "@version"]
}
}
output {
elasticsearch {
hosts => ["http://10.100.21.18:9200"]
index => "%{[@metadata][_index]}"
document_type => "%{[@metadata][_type]}"
document_id => "%{[@metadata][_id]}"
ilm_enabled => false
manage_template => false
}
}

- 点赞
- 收藏
- 关注作者
评论(0)