机器学习2:KNN决策树探究泰坦尼克号幸存者问题

【摘要】
KNN决策树探究泰坦尼克号幸存者问题
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.metrics import classification_report
import graphviz #决策树可视...
KNN决策树探究泰坦尼克号幸存者问题

import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.metrics import classification_report
import graphviz #决策树可视化
- 1
- 2
- 3
- 4
data = pd.read_csv(r"titanic_data.csv")
data.drop("PassengerId",axis = 1,inplace = True) #删除id这一列
- 1
- 2
data
- 1
| Survived | Pclass | Sex | Age | |
|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 |
| 1 | 1 | 1 | female | 38.0 |
| 2 | 1 | 3 | female | 26.0 |
| 3 | 1 | 1 | female | 35.0 |
| 4 | 0 | 3 | male | 35.0 |
| ... | ... | ... | ... | ... |
| 886 | 0 | 2 | male | 27.0 |
| 887 | 1 | 1 | female | 19.0 |
| 888 | 0 | 3 | female | NaN |
| 889 | 1 | 1 | male | 26.0 |
| 890 | 0 | 3 | male | 32.0 |
891 rows × 4 columns
data.loc[data["Sex"] == "male","Sex"] = 1
data.loc[data["Sex"] == "female","Sex"] = 0
- 1
- 2
data
- 1
| Survived | Pclass | Sex | Age | |
|---|---|---|---|---|
| 0 | 0 | 3 | 1 | 22.0 |
| 1 | 1 | 1 | 0 | 38.0 |
| 2 | 1 | 3 | 0 | 26.0 |
| 3 | 1 | 1 | 0 | 35.0 |
| 4 | 0 | 3 | 1 | 35.0 |
| ... | ... | ... | ... | ... |
| 886 | 0 | 2 | 1 | 27.0 |
| 887 | 1 | 1 | 0 | 19.0 |
| 888 | 0 | 3 | 0 | NaN |
| 889 | 1 | 1 | 1 | 26.0 |
| 890 | 0 | 3 | 1 | 32.0 |
891 rows × 4 columns
data.fillna(data["Age"].mean(),inplace = True) #用均值来填充缺失值
- 1
data
- 1
| Survived | Pclass | Sex | Age | |
|---|---|---|---|---|
| 0 | 0 | 3 | 1 | 22.000000 |
| 1 | 1 | 1 | 0 | 38.000000 |
| 2 | 1 | 3 | 0 | 26.000000 |
| 3 | 1 | 1 | 0 | 35.000000 |
| 4 | 0 | 3 | 1 | 35.000000 |
| ... | ... | ... | ... | ... |
| 886 | 0 | 2 | 1 | 27.000000 |
| 887 | 1 | 1 | 0 | 19.000000 |
| 888 | 0 | 3 | 0 | 29.699118 |
| 889 | 1 | 1 | 1 | 26.000000 |
| 890 | 0 | 3 | 1 | 32.000000 |
891 rows × 4 columns
Dtc = DecisionTreeClassifier(max_depth = 5,random_state =8) #构建决策树
Dtc.fit(data.iloc[:,1:],data["Survived"]) #模型训练
pre = Dtc.predict(data.iloc[:,1:]) #模型预测
- 1
- 2
- 3
print(classification_report(pre,data["Survived"])) #混淆矩阵
- 1
precision recall f1-score support 0 0.88 0.84 0.86 573 1 0.73 0.79 0.76 318 accuracy 0.82 891 macro avg 0.81 0.82 0.81 891
weighted avg 0.83 0.82 0.82 891
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
pre == data["Survived"] #比较模型预测值与实际值是否一致
- 1
0 True
1 True
2 True
3 True
4 True ...
886 True
887 True
888 False
889 False
890 True
Name: Survived, Length: 891, dtype: bool
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
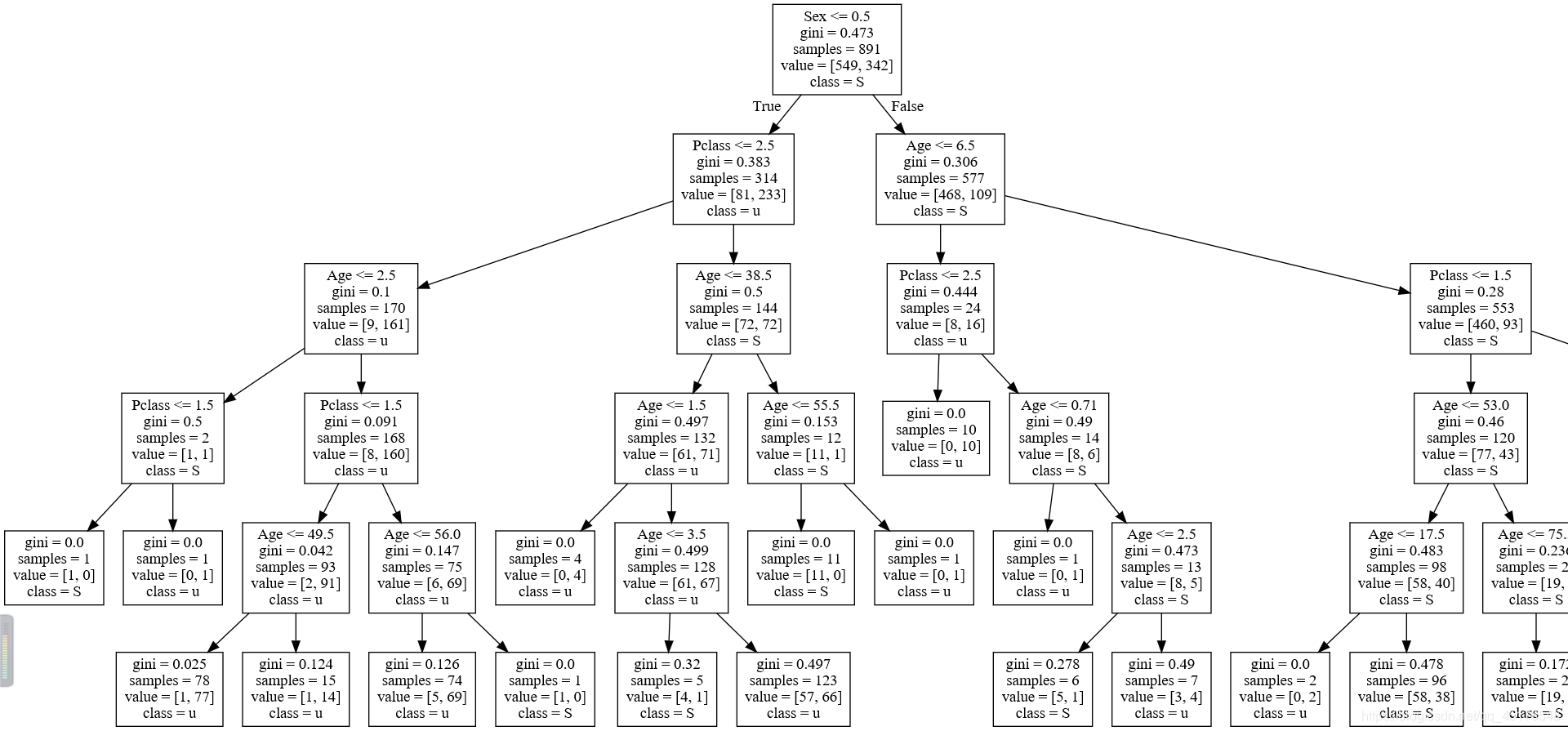
可视化
dot_data = export_graphviz(Dtc,feature_names = ["Pclass","Sex","Age"],class_names="Survive")
- 1
graph = graphviz.Source(dot_data)
graph
- 1
- 2
文章来源: blog.csdn.net,作者:北山啦,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_45176548/article/details/112060492

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)