华为云企业级Redis揭秘第三期:一场由fork引发的超时,让我们重新探讨了Redis抖动问题

【最新活动】企业级Redis专场热销中!首月免费,包年仅需4折!
背景介绍
GaussDB(for Redis)服务团队在支撑某客户业务上云的过程中,发现一次由fork引发的时延抖动问题,本着对客户负责任的态度,我们详细探究了fork这个系统调用的性能影响,并且在最新的GaussDB(for Redis)版本已解决了这个抖动问题,清零了内部的fork使用,与原生Redis相比,彻底解决了fork的性能隐患。
问题焦点
- 华为云GaussDB(for Redis) 服务在某客户上云线调测过程中发现,系统上量后规律性的出现每5分钟1次的时延抖动问题。
- 华为云GaussDB(for Redis)团队经过攻关,最终确认抖动原因是fork导致并解决了这个问题。而fork是开源Redis的一个重要依赖,希望通过本文的分享,能够帮助大家在使用开源Redis的时候,充分认识fork的影响,从而选择更优的方案。
问题现象
某客户业务接入GaussDB(for Redis)压测发现,每5分钟系统出现一次规律性的时延抖动:
- 正常情况消息时延在1-3ms,抖动时刻时延达到300ms左右。
- 通常是压测一段时间后开始出现抖动;抖动一旦出现后就非常规律的保持在每5分钟1次;每次抖动的持续时长在10ms以内。
下图是从系统慢日志中捕获到的发生抖动的消息样例(对敏感信息进行了遮掩):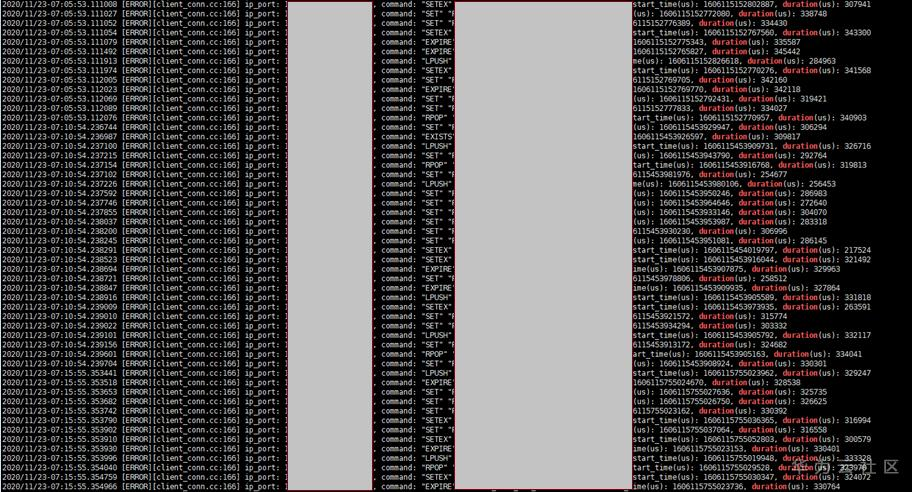
问题分析
1)排查抖动源:
- 由于故障的时间分布非常规律,首先排除定时任务的影响,主要包括:
- agent:和管控对接的周期性统计信息上报任务
- 内核:执行引擎(Redis协议解析)和存储引擎(rocksdb)的周期性操作(包括rocskdb统计,wal清理等)
屏蔽上述2类定时任务后,抖动依然存在。
- 排除法未果后,决定回到正向定位的路上来。通过对数据访问路径增加分段耗时统计,最终发现抖动时刻内存操作(包括allocate、memcpy等)的耗时显著变长;基本上长出来的时延,都是阻塞在了内存操作上。
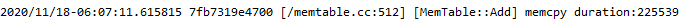
(截图为相关日志,单位是微秒)
- 既然定位到是系统级操作的抖动,那么下一步的思路就是捕获抖动时刻系统是否有异常。我们采取的方法是,通过脚本定时抓取top信息,分析系统变化。运气比较好,脚本部署后一下就抓到了一个关键信息:每次在抖动的时刻,系统中会出现一个frm-timer进程;该进程为GaussDB(for Redis)进程的子进程,且为瞬时进程,持续1-2s后退出。
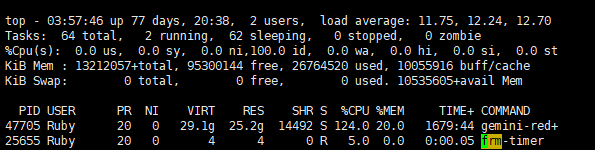
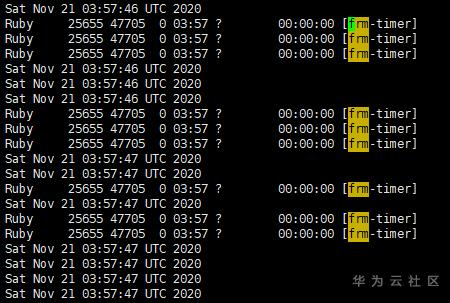
- 为了确认该进程的影响,我们又抓取了perf信息,发现在该进程出现时刻,Kmalloc, memset_sse,memcopy_sse等内核系统调用增多。从上述信息推断,frm-timer进程应该是被fork出来的,抖动源基本可锁定在fork frm-timer这个动作上。
2)确定引发抖动的代码:
- 分析frm-timer的来历是下一步的关键。因为这个标识符不在我们的代码中,所以就需要拉通给我们提供类库的兄弟部门联合分析了。经过大家联合排查,确认frm-timer是日志库liblog中的一个定时器处理线程。如果这个线程fork了一个匿名的子进程,就会复用父进程的线程名,表现为Redis进程创建出1个名为frm-timer的子进程的现象。
- 由于frm-timer负责处理liblog中所有模块的定时器任务,究竟是哪个模块触发了上述fork?这里我们采取了一个比较巧妙的方法,我们在定时器处理逻辑中增加了一段代码:如果处理耗时超过30ms,则调用std:: abort()退出,以生成core栈。
- 通过分析core栈,并结合代码排查,最终确认引发抖动的代码如下:
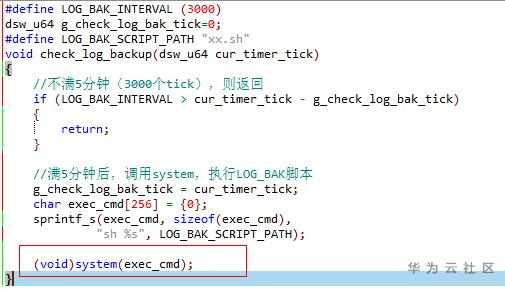
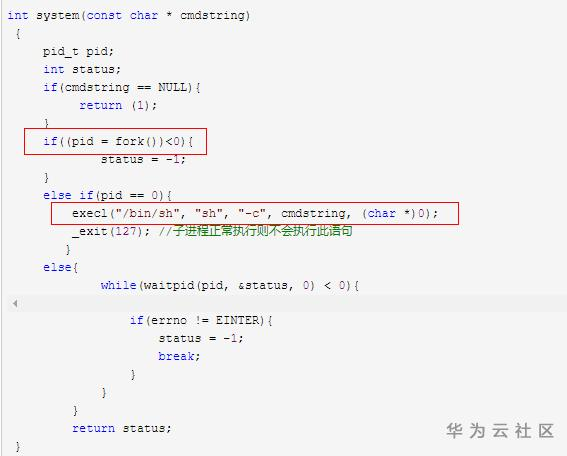
上述代码是用来周期性归档日志的,它每5分钟会执行1次 system系统调用来运行相关脚本,完成归档日志的操作。而Linux system系统调用的源码如下,实际上是一个先fork子进程,再调用execl的过程。
- 分析至此,我们还需要回答最后一个问题:究竟是fork导致的抖动,还是脚本内容导致的抖动?为此,我们设计了一组测试用例:
- 用例1:将脚本内容改为最简单的echo操作
- 用例2:在Redis进程里模拟1个类似frm-timer的线程,通过命令触发该线程执行fork操作
- 用例3:在Redis进程里模拟1个类似frm-timer的线程,通过命令触发该线程执行先fork,再excel的操作
- 用例4:在Redis进程里模拟1个类似frm-timer的线程,通过命令触发该线程执行system的操作
- 用例5:在Redis进程里模拟1个类似frm-timer的线程,通过命令触发该线程执行先vfork,再excel的操作
最终的验证结果:
- 用例1:有抖动。
- 用例2:有抖动。
- 用例3:有抖动。
- 用例4:有抖动。
- 用例5:无抖动。
用例1结果表明抖动和脚本内容无关;用例2、3、4的结果表明调用system引发抖动的根因是因为其中执行了fork操作;用例5的结果进一步佐证了抖动的根因就是因为fork操作。最终的故障原因示意图如下:
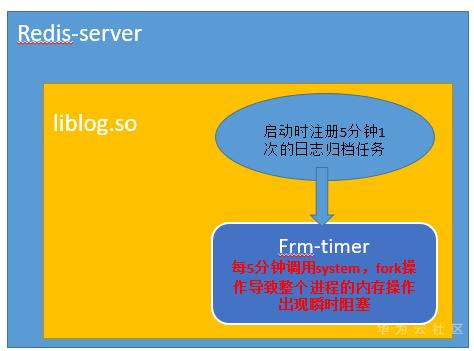
3)进一步探究fork的影响:
- 众所周知,fork是Linux(严格说是POSIX接口)创建子进程的系统调用,历史上看,主流观点大多对其赞誉有加;但近年间随着技术演进,也陆续出现了反对的声音:有人认为fork是上个时代遗留的产物,在现代操作系统中已经过时,有很多害处。激进的观点甚至认为它应该被彻底弃用。(参见附录1,2)
- fork当前被诟病的主要问题之一是它的性能。大家对fork通常的理解是其采用copy-on-wirte写时复制策略,因此对其的性能影响不甚敏感。但实际上,虽然fork时可共享的数据内容不需要复制,但其相关的内核数据结构(包括页目录、页表、vm_area_struc等)的复制开销也是不容忽视的。附录1、2中的文章对fork开销有详细介绍,我们这回遇到的问题也是一个鲜活的案例:对于Redis这样的时延敏感型应用,1次fork就可能导致消息时延出现100倍的抖动,这对于应用来说无疑是不可接受的。
4)原生Redis的fork问题:
4.1 原生Redis同样被fork问题困扰(参见附录3,4,5),具体包括如下场景:
1)数据备份
备份时需要生成RDB文件,因此Redis需要触发一次fork。
2)主从同步
全量复制场景(包括初次复制或其他堆积严重的情况),主节点需要产生RDB文件来加速同步,同样需要触发fork。
3)AOF重写
当AOF文件较大,需要合并重写时,也会产生一次fork。
4.2 上述fork问题对原生Redis的影响如下:
1)业务抖动
原生Redis采用单线程架构,如果在电商大促、热点事件等业务高峰时发生上述fork,会导致Redis阻塞,进而对业务造成雪崩的影响。
2)内存利用率只有50%
Fork时子进程需要拷贝父进程的内存空间,虽然是COW,但也要预留足够空间以防不测,因此内存利用率只有50%,也使得成本高了一倍。
3)容量规模影响
为减小fork的影响,生产环境上原生Redis单个进程的最大内存量,通常控制在5G以内,导致原生Redis实例的容量大大受限,无法支撑海量数据。
解决方法
- 修改日志库liblog中的周期性归档逻辑,不再fork子进程。
- 系统排查并整改GaussDB(for Redis)代码(包括使用的类库代码)中的fork调用。
- 最终排查结果,实际只有本次的这个问题点涉及fork。当前修改后即可确保GaussDB(for Redis)的时延保持稳定,不再受fork性能影响。
注:GaussDB(for Redis)由华为云基于存算分离架构自主开发,因此不存在原生Redis的fork调用的场景。
总结
本文通过分析GaussDB(for Redis)的一次由fork引发的时延抖动问题,探究了fork这个系统调用的性能影响。最新的GaussDB(for Redis)版本已解决了这个抖动问题,并清零了内部的fork使用,与原生Redis相比,彻底解决了fork的性能隐患。希望通过这个问题的分析,能够带给大家一些启发,方便大家更好的选型。
附:
3.[开源Redis的一些坑]
本文作者:华为云数据库GaussDB(for Redis)团队
杭州/西安/深圳简历投递:yuwenlong4@huawei.com
GaussDB(for Redis)产品主页:
https://www.huaweicloud.cn/product/gaussdbforredis.html
更多技术文章,关注GaussDB(for Redis)官方博客:
https://bbs.huaweicloud.cn/community/usersnew/id_1614151726110813

- 点赞
- 收藏
- 关注作者
评论(0)