从零开始实施推荐系统的落地部署——29.推荐系统案例(十九)获取股票数据源

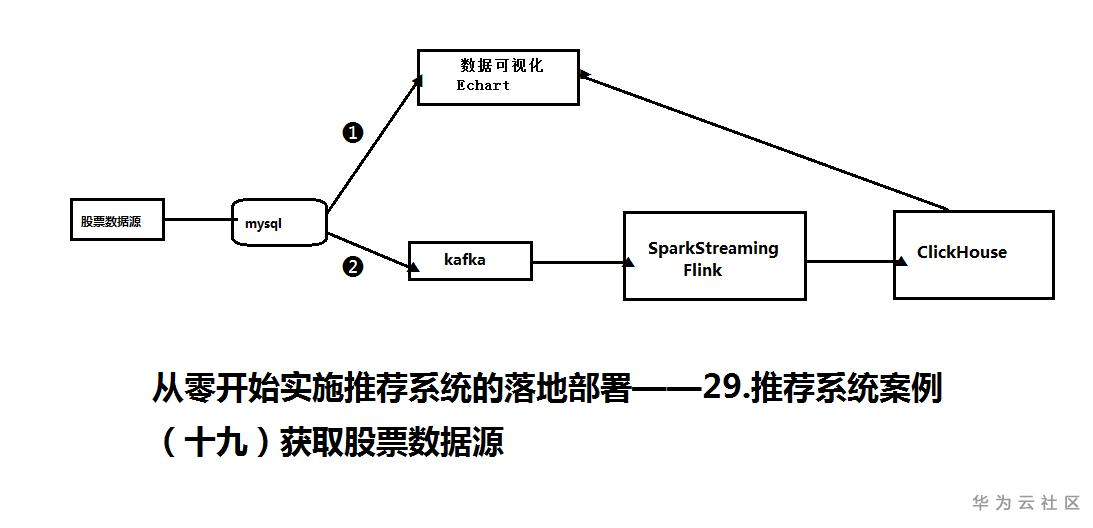
根据上图显示,大数据实时流处理应该是以2线路的流程,还有经过sparkstreaming或Flink处理后应该是先到hive的数据仓库后再到clickhouse,但是考虑到本人的电脑硬件资源有限,就不经过hive的数据仓库,直接到clickhouse。在通过clickhouse调用数据使用Echarts完成数据可视化。但是流程2如果处理不好,容易造成混乱,不好排错,所以我先使用流程1,直接通过mysql调用数据使用Echarts完成数据可视化,完成后在拓展到流程2。
之前有找过都是关于java或scala方面的大数据编程相关资料,但是我想尽量使用python来做这个案例,恰好看到TuShare,它是一个免费、开源的python财经数据接口包,已将各类数据整理为dataframe类型供我们使用。特点是数据覆盖范围广,接口调用简单,响应快速。
1. 使用前提是:lxml也是必须的,正常情况下安装了Anaconda后无须单独安装,我安装的是miniconda2,必须执行:pip install lxml,再开始安装pip install tushare,进入jupyter notebook,查看是否安装成功。
import tushare
print(tushare.__version__)
2. 查询实时行情
一次性获取当前交易所有股票的行情数据(如果是节假日,即为上一交易日,结果显示速度取决于网速)
import tushare as ts
df=ts.get_today_all()
df.head(10)
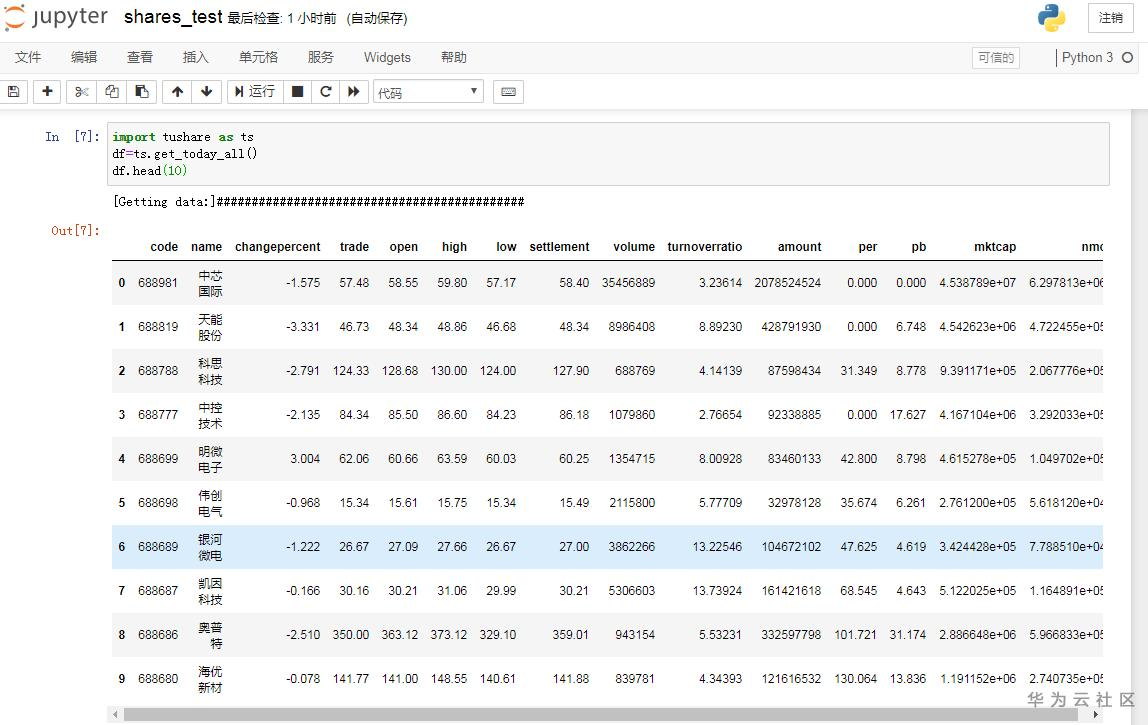
字段说明:
code:代码,name:名称,changepercent:涨跌幅,trade:现价,open:开盘价,high:最高价,low:最低价,settlement:昨日收盘价,volume:成交量,turnoverratio:换手率,amount:成交金额,per:市盈率,pb:市净率,mktcap:总市值,nmc:流通市值
3. 实时分笔
获取实时分笔数据,可以实时取得股票当前报价和成交信息
import tushare as ts
da=ts.get_realtime_quotes(df['code'].tail(10))
da
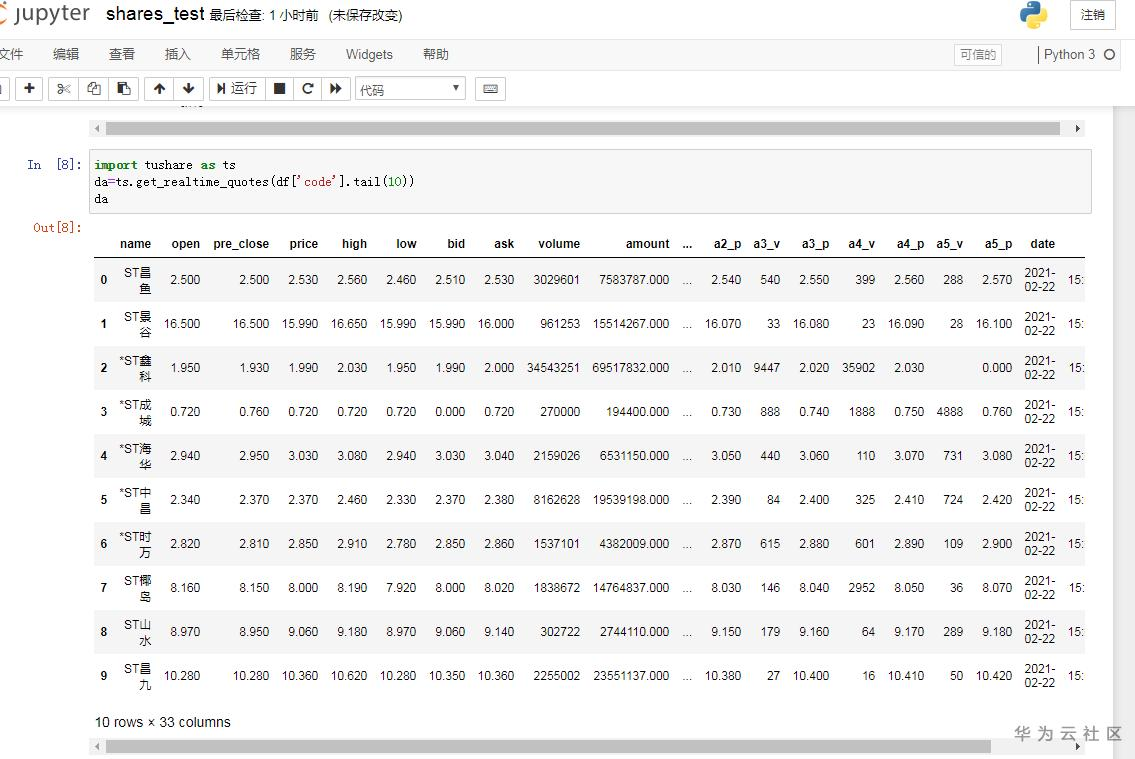
字段太多,选取几个有用字段即可。
db=da[['code','name','pre_close','price','high','low','bid','ask','volume','amount','time']]
db
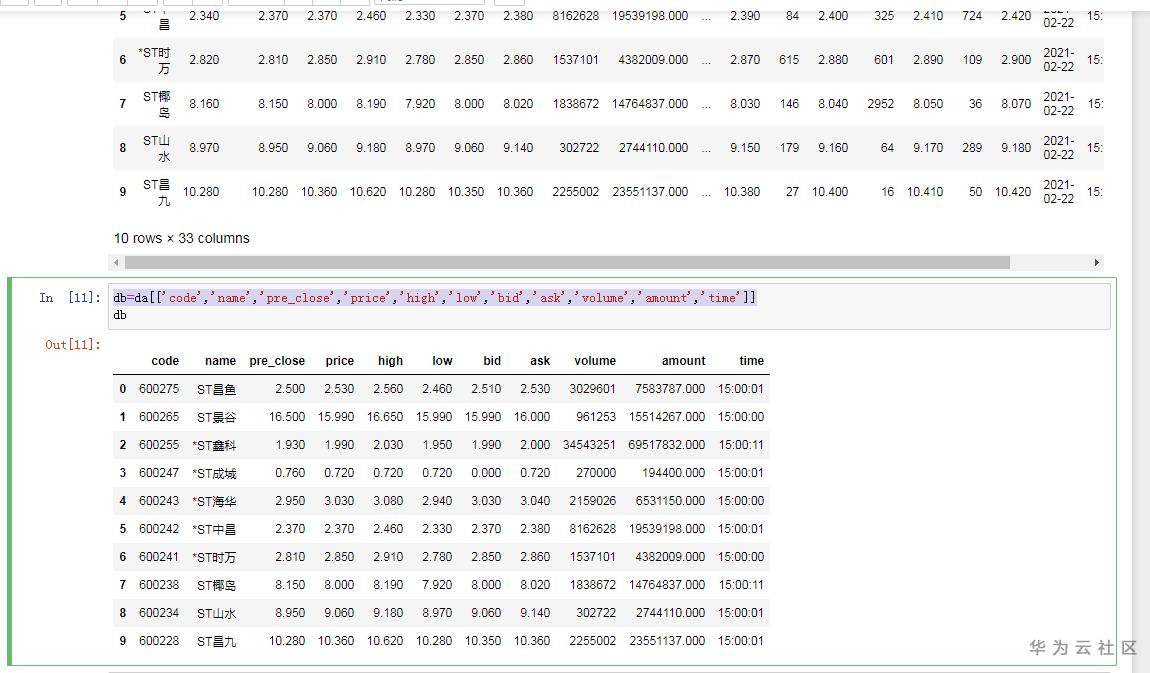
字段说明:
code:代码,name:名称,pre_close:昨日收盘价,price:当前价格,high:今日最高价,low:今日最低价,bid:竞买价(即“买一”报价),ask:竞卖价(即“卖一”报价),volume:成交量 maybe you need do volume/100,amount,成交金额(元 CNY),time:时间。
4. stock_basic:描述:获取基础信息数据,包括股票代码、名称、上市日期、退市日期等。
pro = ts.pro_api()
data=pro.stock_basic(exchange='',list_status='L',fields='ts_code,symbol,name,area,industry ')
注意:ts.pro_api()括号里面填的是注册后的获得的take
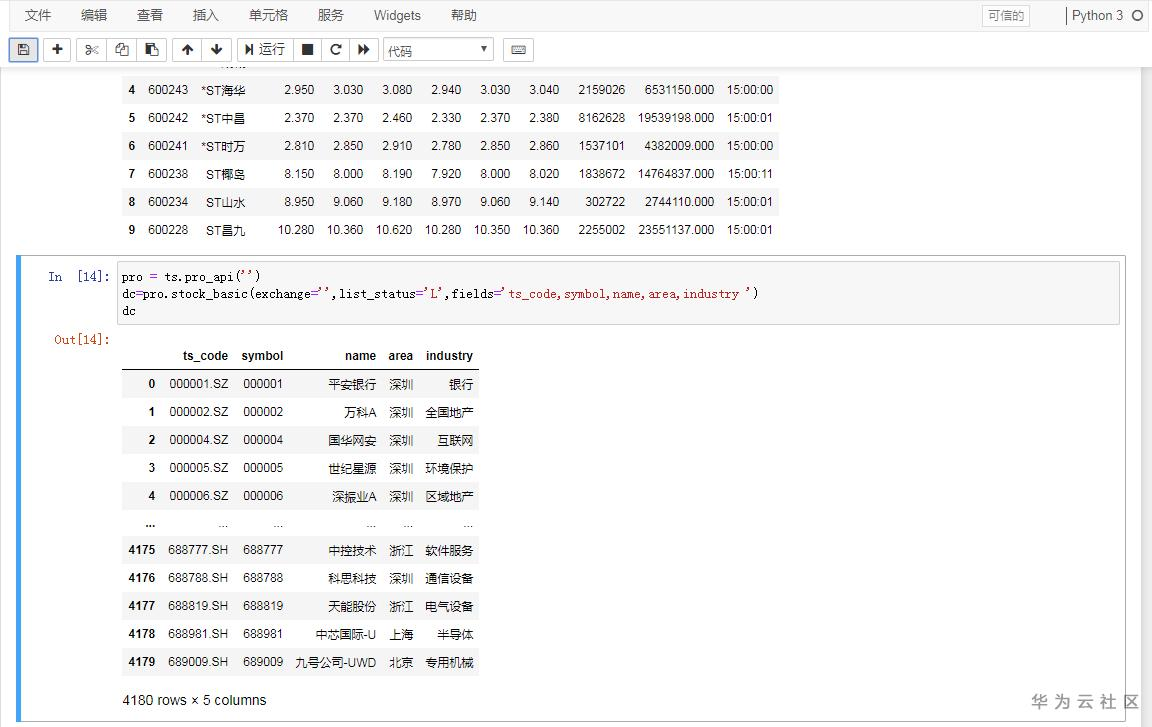
字段说明:
list_status:上市状态(L上市 D退市 P暂停上市),ts_code:TS代码,symbol:股票代码,name:股票名称,area:所在地域,industry:所属行业。
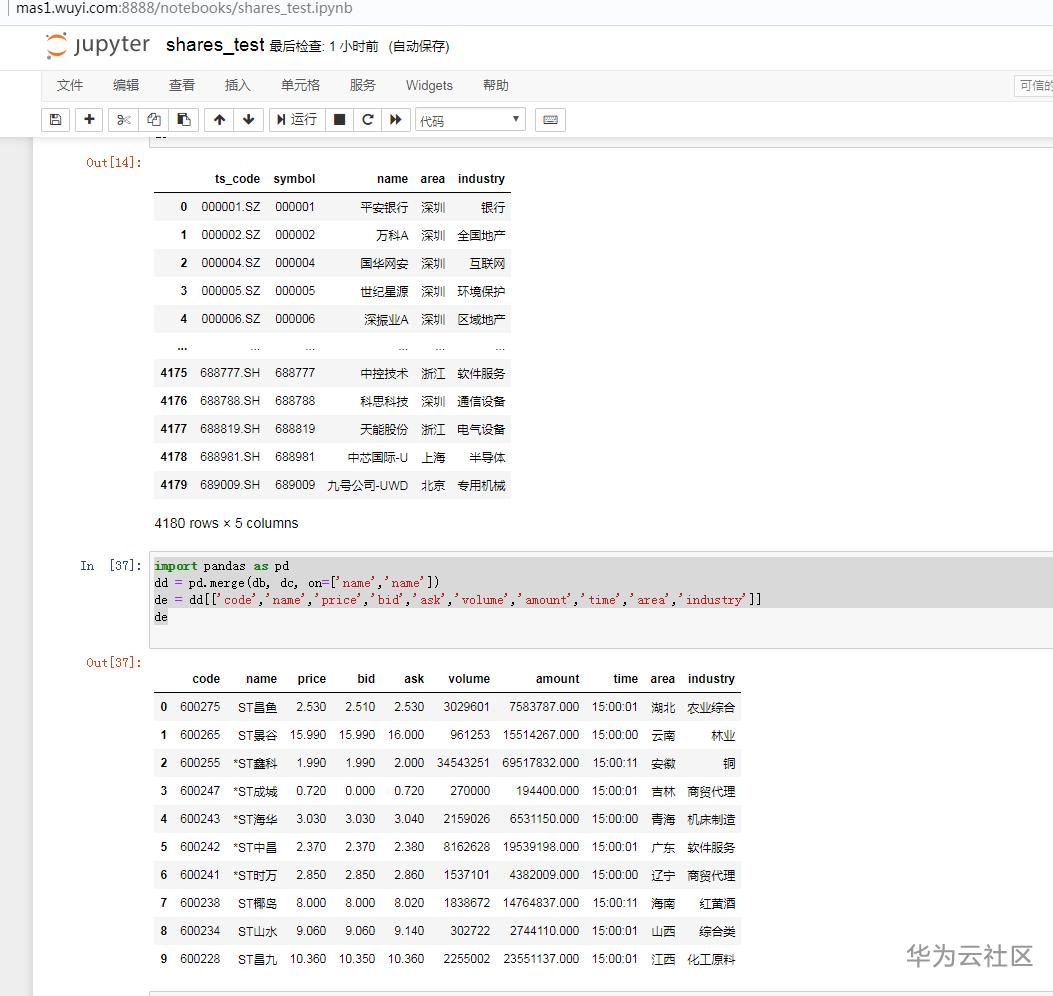
5. 合并数据获取所在地和行业:
dd = db.join(dc, on=['code', 'symbol'], how='inner')
de = dd [['code','name','price','bid','ask','volume','amount','time','area','industry']]
de
出现ValueError: len(left_on) must equal the number of levels in the index of "right"的异常。如图所示:
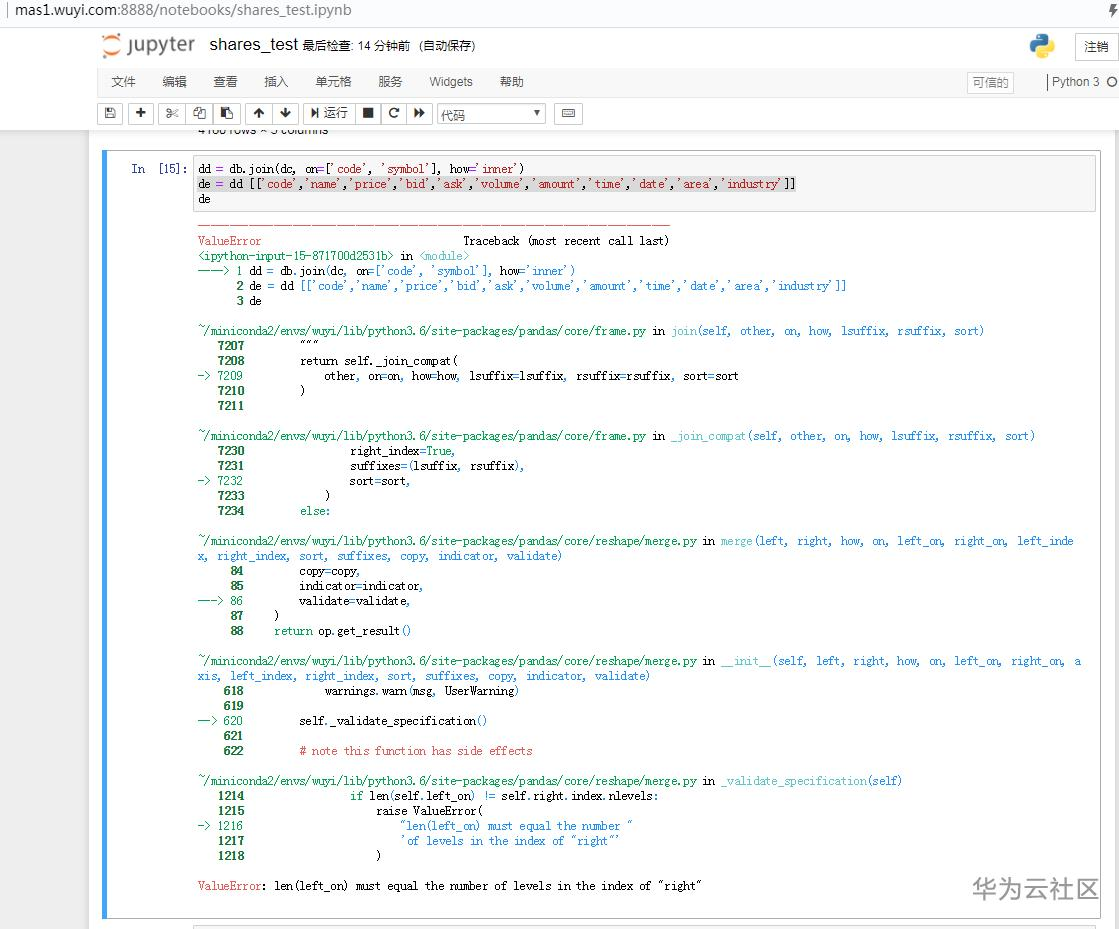
解决办法:
import pandas as pd
dd = pd.merge(db,dc, ['code', 'symbol'], how='inner')
de = dd [['code','name','price','bid','ask','volume','amount','time' ,'area','industry']]
de
执行后出现下面的情况
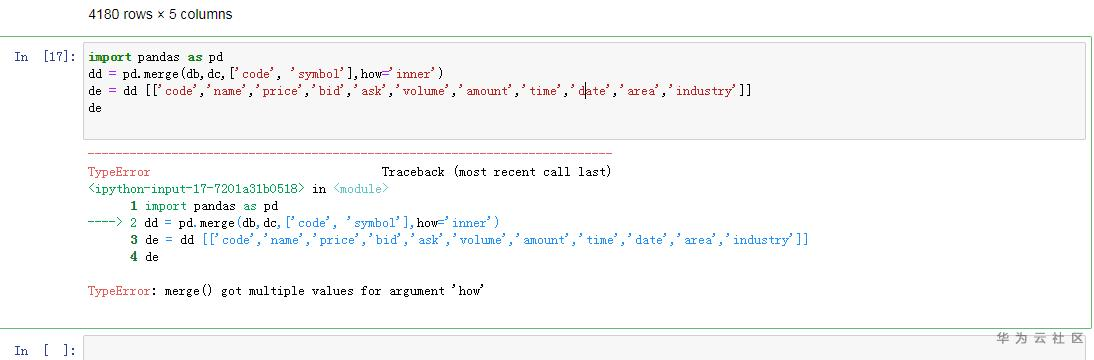
把dd = pd.merge(db,dc, ['code', 'symbol'], how='inner')的how=’inter’和前面的(,)一起去掉,执行后提示
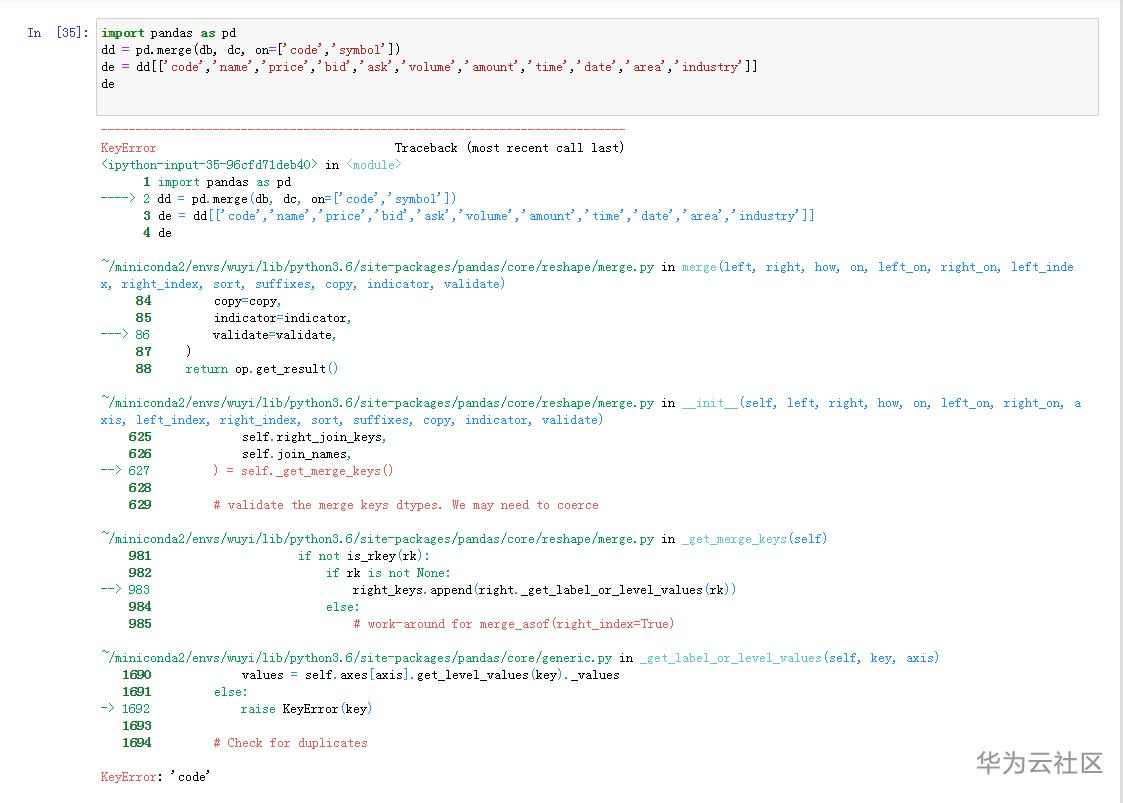
经排查,发现db和dc的表里面有name,而且跟code和symbol一一对应,修改为dd = pd.merge(db, dc, on=['name','name'])即可。

- 点赞
- 收藏
- 关注作者
评论(0)