行人社交距离风险提示Demo | 基于ModelArts AI Gallery与HiLens Kit联合开发

前情提要
听到行人社交距离风险提示是不是觉得有点不太明白,简单来说,就是通过某一角度的视觉信息,判断行人的社交距离情况,让我们直接看视频来领会吧。
这是在华为HiLens Kit上部署推理保存的视频,通过计算行人间社交距离给出“High Risk” 或“Low Risk”的提示,下面来具体介绍一下。
社交距离检测介绍
本Demo使用YOLOv3_Resnet18模型来检测的视频流中的行人,获取行人坐标(即图中蓝色方框),然后计算所有检测到的人之间的相互“距离”。这里要注意的是和现实生活中使用的长度单位来衡量距离不一样的是,在计算机视觉世界中使用的是“像素”,一种简单的方法是根据行人坐标来计算检测到的两个人的质心,也就是根据检测到的目标框的中心之间相隔的像素值作为计算视觉世界中的“距离”来衡量视频中的人之间的距离是否超过安全距离。
Demo主要分为两部分:行人检测和社交距离计算,大体流程如下:
1. 使用YOLOv3_Resnet18算法检测输入视频或视频流中的所有行人,得到行人坐标,并根据此计算位置信息和质心位置;
2. 根据第1步的信息,计算所有检测到的行人的人质心之间的相互距离;
3. 根据上一步计算得到的社交距离,对比预先设置的安全距离,从而计算每个人之间的距离对,检测两个人之间的距离是否小于N个像素,小于则处于安全距离,反之则不处于安全距离。
这里使用的是YOLOv3_Resnet18算法来进行行人检测,事实上,可替换为任何一种目标检测算法,只要输出行人坐标符合本Demo要求顺序即可,比如性能更为优良的YOLOv4,甚至YOLOv5等等,值得一提的是在PC端的实现是基于最新的、训练和推理性能最佳的YOLOv5-s模型实现的,如果需要可以参考本文最下面参考部分的[1] 或[2]([1]比[2]更加详细具体,容易上手,推荐使用)。但YOLOv5是基于PyTorch实现的,不方便转换为HiLens需要的om模型使用,庆幸的是可以通过PyTorch——>onnx——>om来使用,这一点我正在尝试,也期待有优秀的同学加入进来。
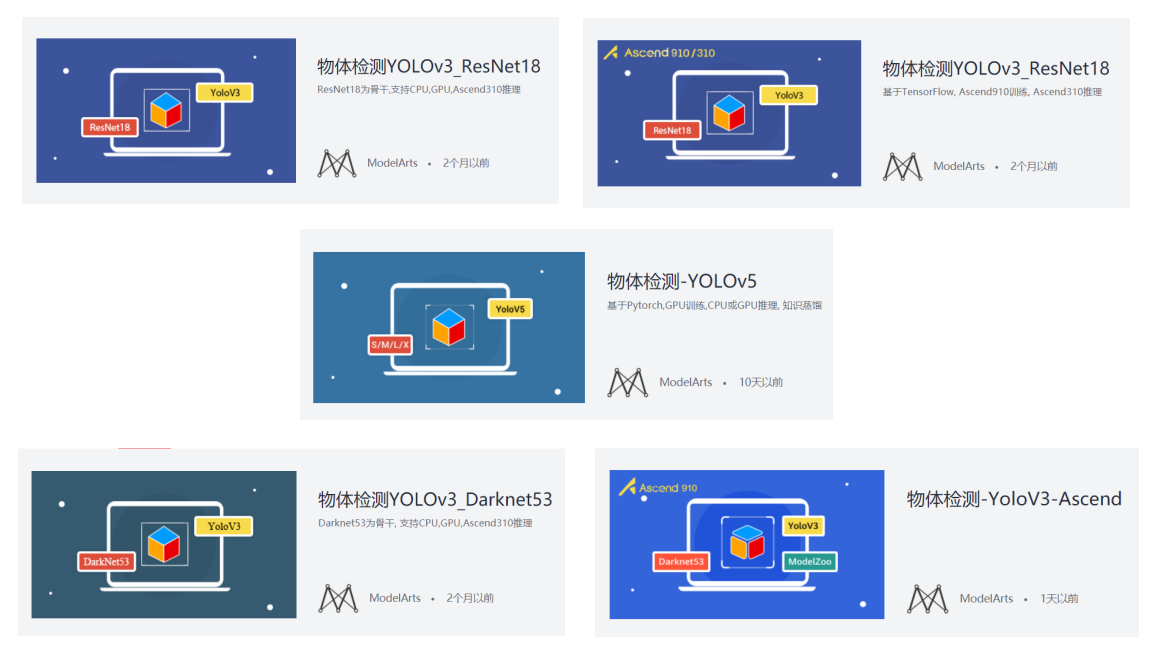
上述的YOLOv3_Resnet18、原版YOLOv3_Darknet53以及最新的YOLOv5算法都可以在ModelArts AI Gallery找到哦,不仅提供了预训练模型,同时也很方便使用,小白也能起送上手,奉上链接:
YOLOv3_Resnet18 GPU版本 TensorFlow:https://marketplace.huaweicloud.cn/markets/aihub/modelhub/detail/?id=948196c8-3e7a-4729-850b-069101d6e95c
YOLOv3_Resnet18 Ascend 910版本 TensorFlow:https://marketplace.huaweicloud.cn/markets/aihub/modelhub/detail/?id=7087008a-7eec-4977-8b66-3a7703e9fd22
YOLOv3_Darknet53 GPU版本 TensorFlow:https://marketplace.huaweicloud.cn/markets/aihub/modelhub/detail/?id=2d52a07e-ccbd-420f-8999-2ea7b4bdd691
YOLOv3 Ascend 910版本 TensorFlow:https://marketplace.huaweicloud.cn/markets/aihub/modelhub/detail/?id=ff4d1e46-256e-4a76-b355-65bdf52f9a82
YOLOv5 GPU PyTorch:https://marketplace.huaweicloud.cn/markets/aihub/modelhub/detail/?id=d89bf587-ed85-476a-a579-5eb3915e2753
怎么样,是不是非常丰富,选择多多呀?可以试手一下哦,会发现使用起来也是很简单的,注意ModelArts和OBS花费哦。
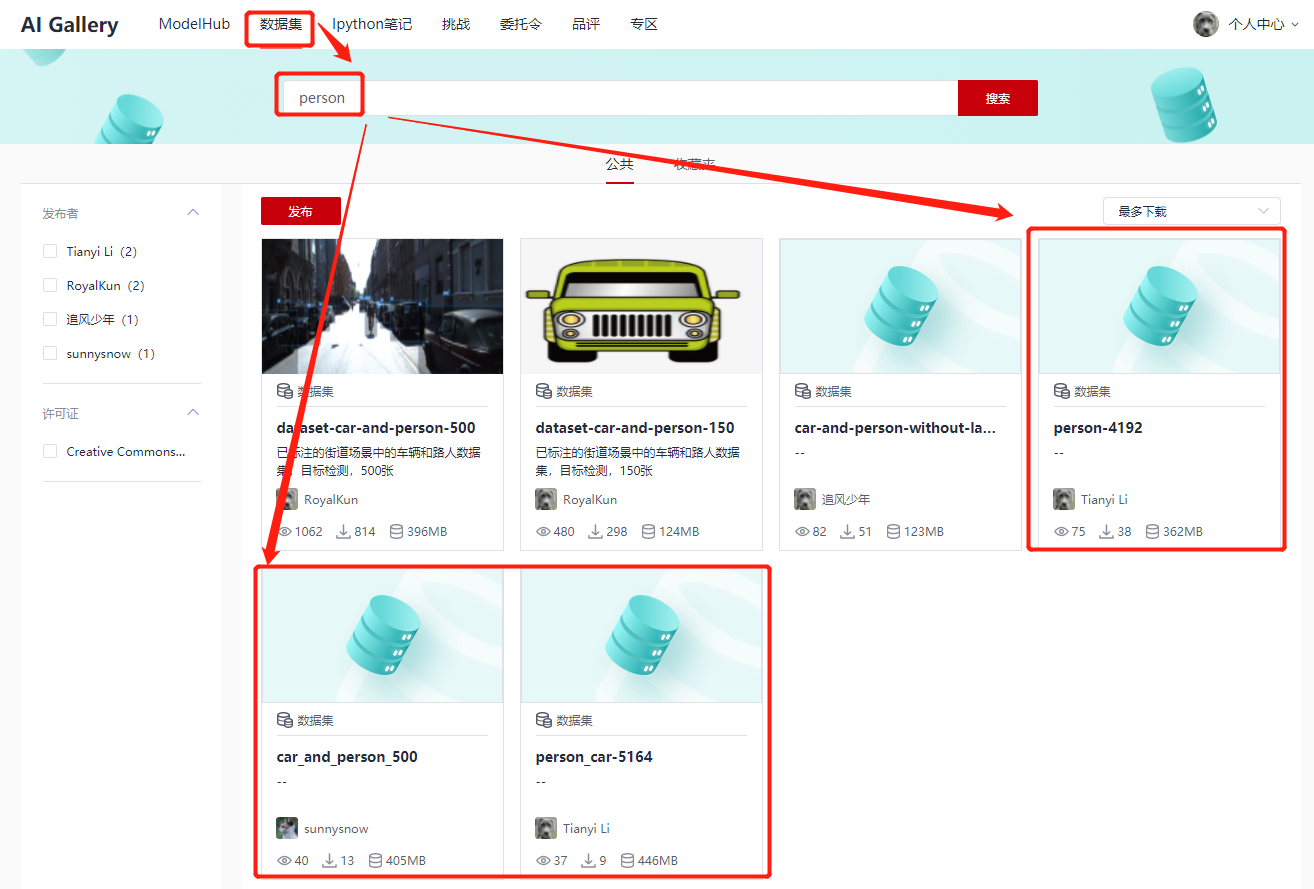
本Demo选择的是第一个——YOLOv3_Resnet18 GPU版本 TensorFlow,因为本Demo只需要对行人进行检测,所以选择了模型结构简单,训练和推理速度快的YOLOv3_Resnet18,节省训练时间,也就是节省训练成本呀。在训练方面,使用了来自开源行人数据集整理的数据集,因为只有person这一个标签,相比于COCO数据集80个标签,训练和部署推理更加具有优势,这里奉上 AI Gallery的数据集链接,没想到吧, AI Gallery不仅有算法,还有数据集,满足你的一切需要,有没有哆啦A梦的口袋的感觉(我承认我有一点夸张)
Person-4192数据集链接:https://marketplace.huaweicloud.cn/markets/aihub/datasets/detail/?content_id=3d67fd03-2e16-4c70-908f-feb8f50334b9
如果你还想训练包含其他类别的情况,比如Person and Car,可参照如下。当然,一般来说,数据集越大,鲁棒性越好,这里的数据集较小,可以自行使用更大的数据集。
实操介绍
主要麻烦的部分是行人检测模型的训练,如果为了方便,可以使用基于COCO的预训练模型,在GitHub有很多。这里希望是从数据集准备开始,到订阅算法,完成训练,到HiLens Studio调试,并最终部署,体验下基于ModelArts和HiLens Kit的完整开发流程,因为以前介绍过,这里就不在赘述,详情可参考我的博文——开发教程 | 基于ModelArts与HiLens端云协同开发行人检测与跟踪方案,博文介绍的较为详细,如果有问题,可以联系我。值得注意的是这篇博文是介绍行人跟踪以及行人计数的,如果有兴趣的话,可以结合这篇博文与本博文,实现更加完善行人检测、跟踪以及社交距离检测的方案,相信在社交距离检测的基础上加入跟踪和多种人数统计方案会更加切合实用,性能更加强大。
对了,我把技能发布到技能市场了,名字是Social-Distancing-using-YOLOv3-HDMI,审核通过后,大家就能够订阅使用了,技能市场汇集了官方和第三方开发的技能,能够高效便捷地将自己开发的技能分享给他人使用,而且从分享到他人订阅以及部署到HiLens使用,完全基于网络实现,非常方便,极大促进了技能的共享。
开发体验
整体基于ModelArts和HiLens Stuio 1.5.0开发,参考开源代码实现,很惭愧的是大部分内容都是人家的,自主创新性很少。不过整体开发还是很顺利的,从得到模型到在HiLens Studio调试完成来说,不到一个下午就能搞定了,这是极致效率的体现,这得益于在线IDE HiLens Studio的使用,作为一款线上IDE,提供了开发,调试的完整功能,甚至可以在线运行调试,直接得到程序运行的可视化结果展示。同时提供了丰富的模板,基于模板开发,大大提高开发效率。
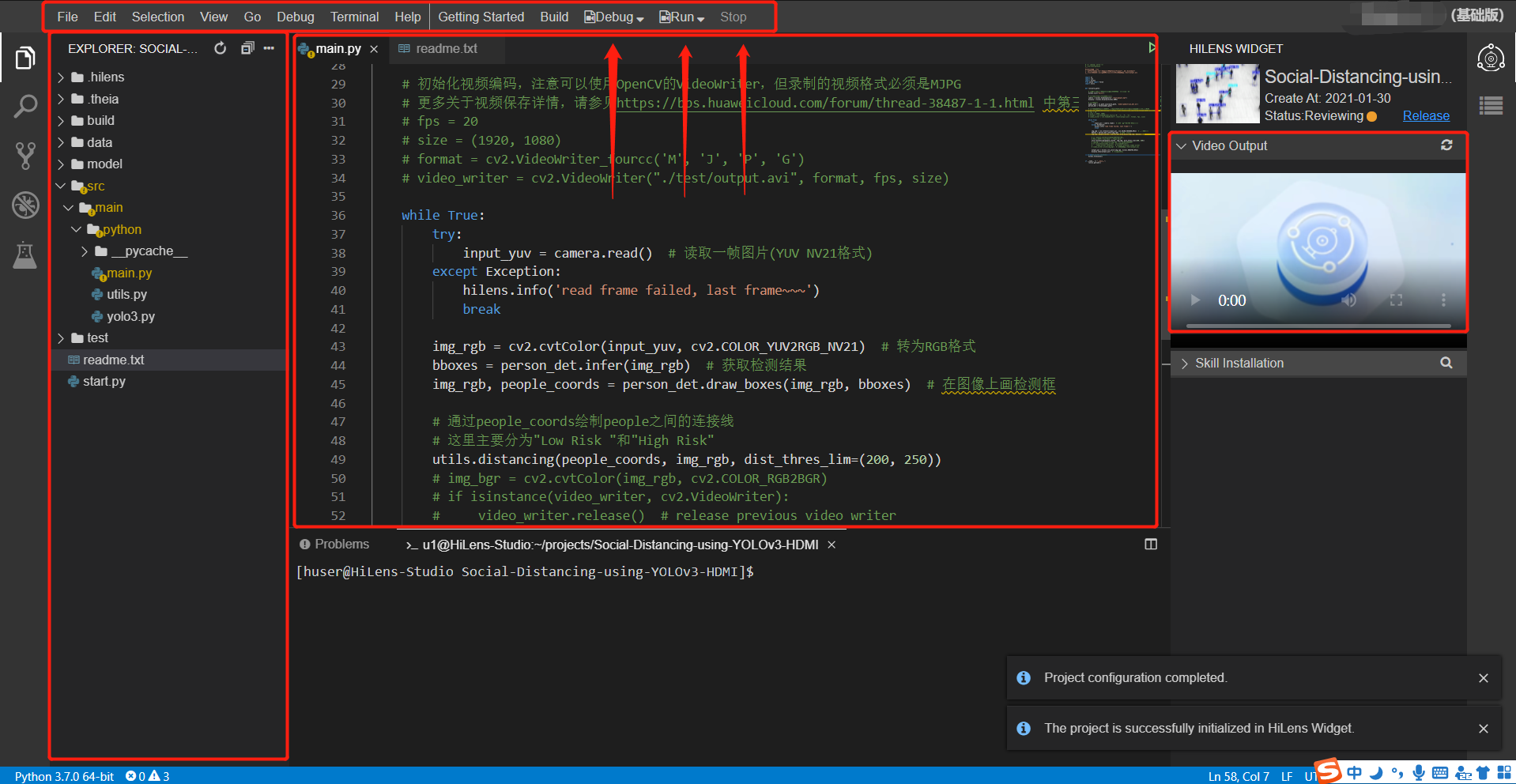
总的来说,仿佛在线有了一个自己的HiLens Kit一样,只要连接到网络,开发HiLens Stduio就能开发了,调试成功后还可以一键安装到自己的HiLens Kit上,让开发变成一件很爽的事情,而且HiLens Studio也在不断完善中,与我第一次使用最初版本相比,稳定性和性能都有了很大的提升,比如下图中红色剪头所指部分,就是后来添加的,方便开发者调试,相信研发人员也是付出了不少心血和努力,非常感谢。
ModelArts也在飞快成长,开发环境除了最初的NoteBook,也有了界面和功能更加完善的Jupyter Lab,最新测试的在线切换硬件配置,可以进行CPU和GPU,以及不同配置CPU和GPU的在线切换功能,这一点一滴地改变方便可开发者的使用,拉近了开发者与ModelArts的距离,相信ModelArts在未来会更加茁壮地成长。
注意的是,我是用的是HiLens Studio基础版,多人共用,所以有时候可能因为资源紧张,导致占用,从而运行出错,这时候可以通过创建官方案例模板运行来判断是否资源占用,一般来说,如果官方模板也运行报错,可能就是资源占用,可以考虑使用付费版,但需要额外费用哦。
下图是HiLens Studio的开发界面,有没有一种熟悉的感觉,和VS Code有些类似,这对熟悉VS Code的同学是一个福音哦。
YOLO浅谈
YOLO系列是经典的目标检测网络,在性能和速度上取得了较好的平衡,应用广泛。虽然原作者只做到了YOLOv3,但在爱好者的努力下,后续发展了YOLOv4, 已经发展到了最新的YOLOv5(暂时称为YOLOv5),注意YOLOv5的作者并没有发表论文,因此只能从代码的角度理解。
YOLOv4在YOLOv3的基础上在网络结构和预处理等很多方面进行了很多的创新,融合了当时得到验证的很多trick,性能得到了很大的提升。比如输入端采用mosaic数据增强,Backbone上采用了CSPDarknet53、Mish激活函数、Dropblock等方式,Neck中采用了SPP、FPN+PAN的结构,输出端则采用CIOU_Loss、DIOU_nms操作。
这里给出YOLO V4的网络结构图(图片来自网络):

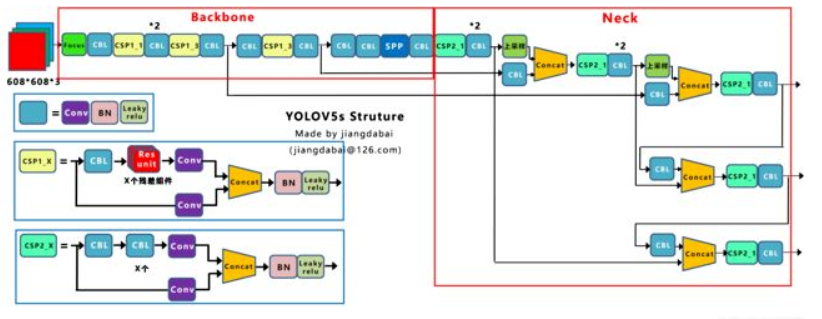
YOLOv5共有s,m,l,x四个模型,相同的数据集上,YOLOv5-s模型训练和推理性能最佳,YOLOv5-x模型mAP指标最佳。其结构其实和YOLOv4的结构还是有一定的相似之处的,但也有一些不同,这里给出YOLOv5-s的网络结构图:
下面简单介绍YOLOv5的部分改进,更多详情可参考[3]和[4]
1. 自适应Anchors计算
在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但YOLOv5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
2. CSP结构
相比于YOLOv4中只有主干网络使用了CSP结构,YOLOv5中设计了两种CSP结构,以YOLOv5-s网络为例,以CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
相关代码如下:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, k // 2, groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.LeakyReLU(0.1, inplace=True) if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(c2, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))结语
基于ModelArts和HiLens(在线IDE HiLens Studio和硬件HiLens Kit )可以高效地从零开始完成一个项目的落地应用全流程,二者的无缝衔接大大提高了效率,但是真正的落地应用需要根据具体应用行业和场景实际分析,对症下药,并非如此简单,本Demo也是仅供学习使用,性能不做保证。不过相信随着ModelArts和HiLens的不断完善和发展,一切都会越来越好,汇集更多开发者,共建良好生态。
参考
[1] https://github.com/ChargedMonk/Social-Distancing-using-YOLOv5
[2] https://github.com/Akbonline/Social-Distancing-using-YOLOv5
[3] https://github.com/ultralytics/yoloV5
[4] https://mp.weixin.qq.com/s/LE4XbU67jLWW2TQJcdXJKA

- 点赞
- 收藏
- 关注作者
评论(0)