如何快速爬取新浪新闻并保存到本地

【摘要】 这篇文章能够快速教你爬取新浪新闻。希望这篇文章对您有所帮助!如果您有想学习的知识或建议,可以给作者留言~
如何快速爬取新浪新闻并保存到本地
一、爬取场景1、网页加载模式2、网页结构
二、API遍历方法爬取新闻1、找到API2、分析关键API参数3、根据API参数设计爬虫逻辑4、测试使用
三、代码实现1、尝试获取动态网页2、观察URL3、程序3.1、导入...
这篇文章能够快速教你爬取新浪新闻。希望这篇文章对您有所帮助!如果您有想学习的知识或建议,可以给作者留言~
如何快速爬取新浪新闻并保存到本地
- 此为一个系列,并将持续更新:
专栏链接:快速入门之爬虫
一、爬取场景
1、网页加载模式
- 动态网页
动态网页不同于传统的静态网页,如果想用传统的方式爬取,会出错的。

- 静态网页

上图为传统的静态网页。
2、网页结构
列表页-详情页
API遍历
二、API遍历方法爬取新闻
1、找到API
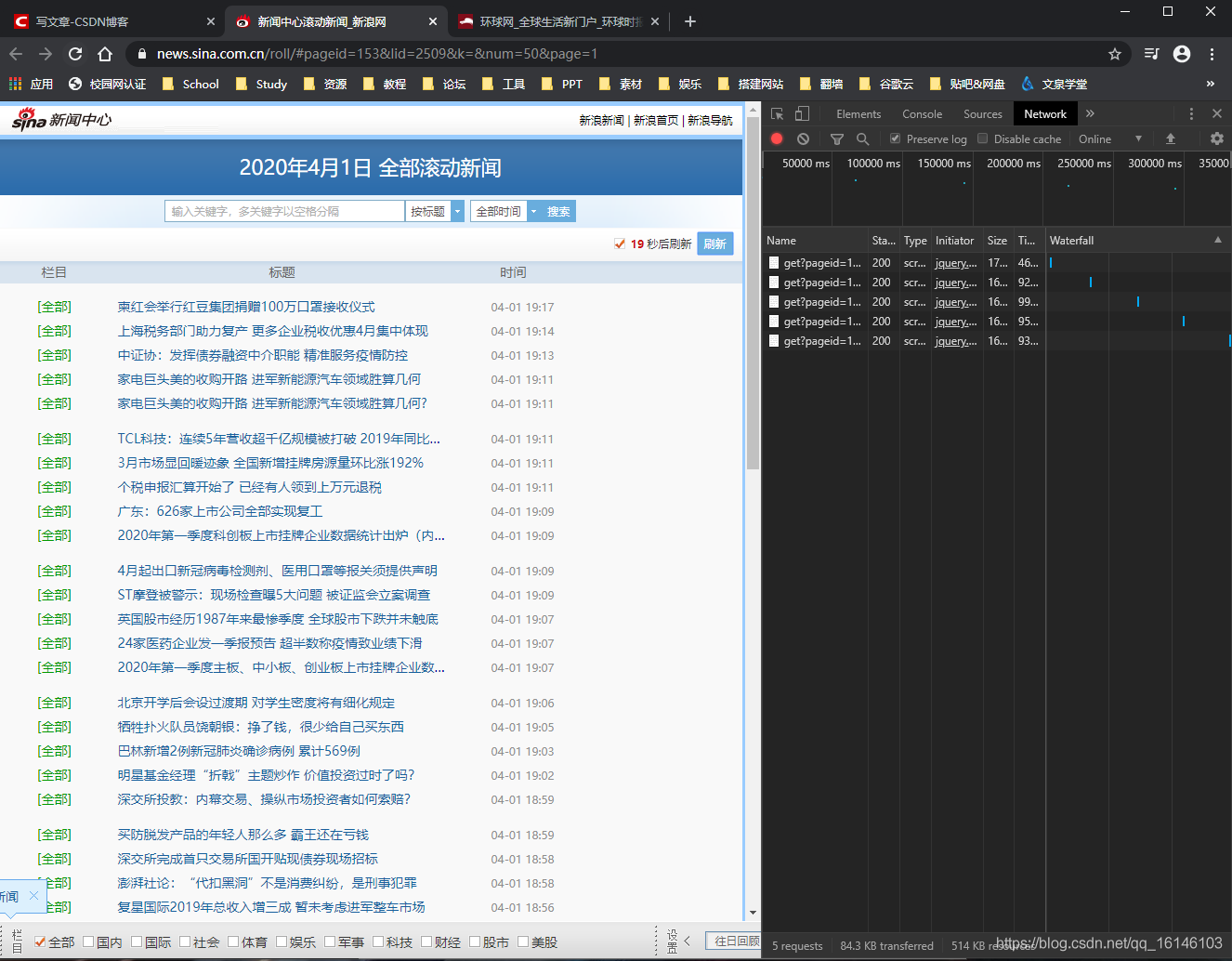
- 使用开发人员工具-network模块找到API
- API:https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691&callback=jQuery1112011987950839178185_1585738993071&_=1585738993083
2、分析关键API参数
- Pageid:应该是新浪API列表列表的分配参数
- Num:每页的新闻数。可以通过修改这个参数
- Page:新闻列表的翻页数。可以通过修改这个参数来遍历
3、根据API参数设计爬虫逻辑
- 先使用APII遍历新闻URL
- 然后根据新闻URL获取详细页,抽取我们想要的数据
4、测试使用
三、代码实现
1、尝试获取动态网页
import requests
print(requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691&callback=jQuery1112011987950839178185_1585738993071&_=1585738993083").content.decode("utf-8"))
- 1
- 2
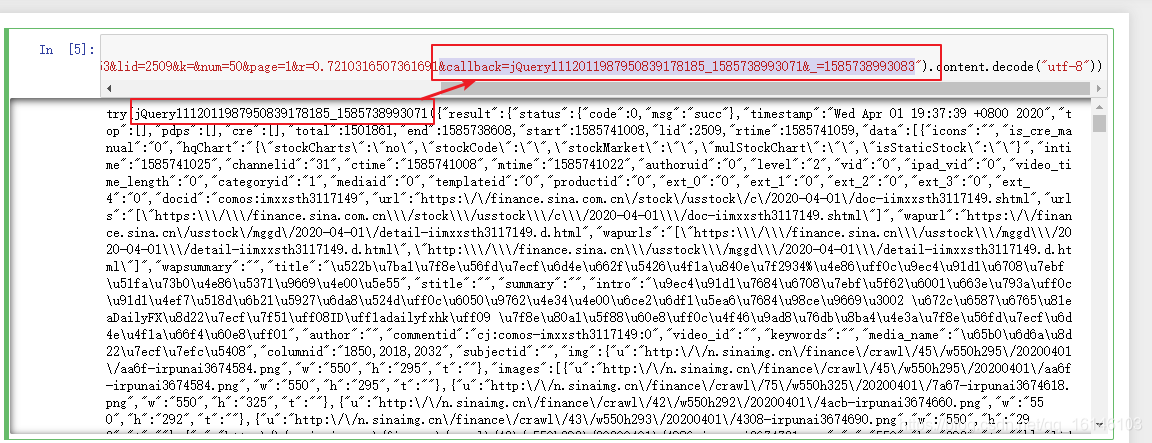
首先我们看到URL链接和得到的结果有重叠的地方,我们可以尝试精简下URL链接,同时由于格式本身为”utf-8“我们可以把格式换成”unicode_escape“

这样我们就能得到想要的模块。
我么可以用json.loads()获取字符串
import requests
import json
print(json.loads(requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691").content))
- 1
- 2
- 3

2、观察URL
https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691
- 1
在这时我们可能会用到时间戳这样一个在线工具:
地址:https://tool.lu/timestamp/

上图红框处,通过进行测试发现:
num控制页面的整体内容
page显示的是分页的内容
我们先进行如下图的测试
得到结果如下:
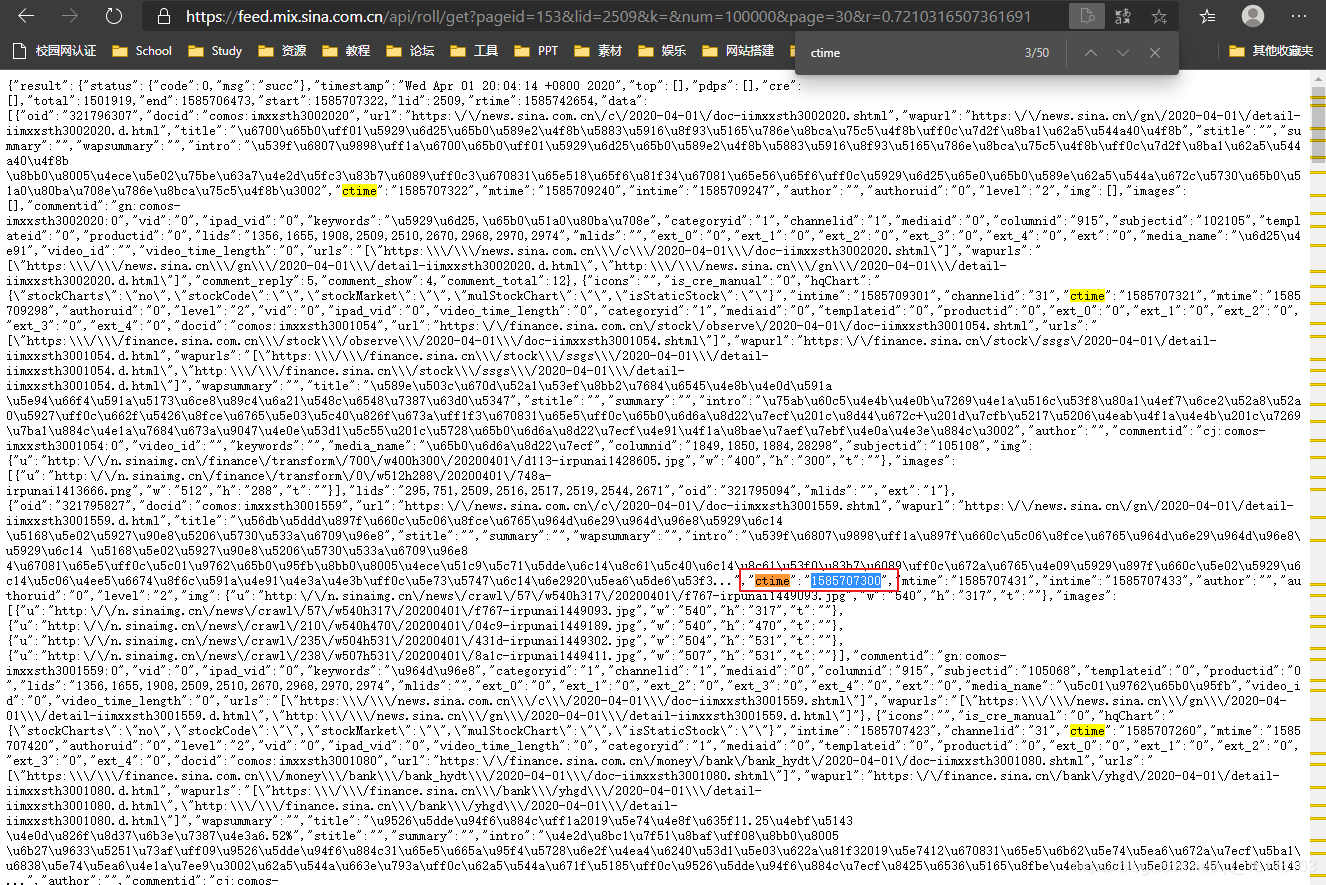
这时我们查找ctime的数值并通过时间戳转换处时间:

下面代码为重点
3、程序
3.1、导入所需要的包
#导入所需要的包
import codecs #用来存储爬取到的信息
from pybloom_live import ScalableBloomFilter # 用于URL去重的
import requests #用于发起请求,获取网页信息
import json #处理json格式的数据
from bs4 import BeautifulSoup as bs #用于数据抽取
from lxml import etree #用于数据抽取
import re #正则语言类库
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.2、编写抽取模块
1、使用BeautifulSoup,编写抽取模块 编写一个函数,函数功能是通过传入的URL参数,利用BeautifulSoup获取详情页面中的新闻标题、内容、来源、时间等信息。
#定义一个函数,函数功能是通过传入的URL参数,获取详情页面中的新闻标题、内容、来源、时间等信息。
#函数名称:getdetailpagebybs ;所需参数:URL
def getdetailpagebybs(url): detail = {} #创建一个字典,存放URL、title、newstime等信息 detail["url"] = url #将URL时间存入detail字典中的相应键值中 page=requests.get(url).content #使用requests.get方法获取网页代码,由于bs4可以自动解码URL的编码,所以此处不需要decode html=bs(page, "lxml") #使用lxml解析器 title=html.find(class_="main-title") #获取新闻网页中的title信息,此处网页中只有一个“class=main-title”,所以使用find即可 print(title.text) #展示新闻标题 detail["title"] = title.text #将新闻标题以文本形式存入detail字典中的相应键值中 artibody=html.find(class_="article") #使用find方法,获取新闻网页中的article信息 #print(artibody.text) detail["artibody"]=artibody.text#。。。。。。。 date_source = html.find(class_="date-source") #使用find方法,获取新闻网页中的date-source信息 #由于不同的新闻详情页之间使用了不同的标签元素,直接抽取可能会报错,所以此处使用判断语句来进行区分爬取 if date_source.a: #判断date-source节点中是否包含有'a'元素 #print(date_source.span.text) detail["newstime"]=date_source.span.text #抽取'span'标签中时间信息 #print(date_source.a.text) detail["newsfrom"] =date_source.a.text #抽取'a'标签中新闻来源信息 else: #print(date_source("span")[0].text) detail["newstime"] =date_source("span")[0].text #抽取'span'标签中包含的时间信息 #print(date_source("span")[1].text) detail["newsfrom"] =date_source("span")[1].text#抽取'span'标签中包含的新闻来源信息 #也可以使用正则表达式来抽取信息 #print(date_source.prettify()) r=re.compile("(\d{4}年\d{2}月\d{2}日 \d{2}:\d{2})") #编写时间信息的正则表达式 re_newstime=r.findall(date_source.text) #使用findall方法,按照编写的正则语句,从date_source节点中所包含的时间信息 detail["re_newstime"] =re_newstime.text #将新闻时间存入detail字典中的相应键值中 return detail #函数返回值为存放抽取信息的字典
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2、使用lxml,编写抽取模块 编写一个函数,使用lxml进行抽取的模块,使用xpath方法,来抽取详情页面中的新闻标题、内容、来源、时间等信息。
#定义一个函数,函数功能是通过传入的URL参数,获取详情页面中的新闻标题、内容、来源、时间等信息。
#函数名称:getdetailpagebylxml ;所需参数:URL
def getdetailpagebylxml(url): detail={} #创建一个字典,存放URL、title、newstime等信息 detail["url"]=url #将URL存入字典中的相应键值中 page = requests.get(url).content.decode("utf-8") #获取网页源代码,并使用utf-8编码 #由于网页的结构可能会随网站更新等原因发生变化,使用xpath方法抽取信息时,从网页复制元素的xpath可能已无法直接使用 #如本例中从网页中复制的date-source元素的xpath为“//*[@id="top_bar"]/div/div[2]”,按照直接复制的xpath将无法正常获取元素信息 #需要人为的修改调整,调整为"//div[@class=\"date-source\"后可以正常获取元素信息了 html = etree.HTML(page) title = html.xpath("/html/head/title/text()")[0] #使用xpath方法抽取title信息 detail["title"]=title #将标题存入字典中的相应键值中 print(title) artibody = html.xpath("//div[@class=\"article\"]/p//text()") #使用xpath方法抽取article信息 detail["artibody"]=''.join(artibody) # artibody是原本一个list对象,使用join方法将其连接起来 date_source = html.xpath("//div[@class=\"date-source\"]//text()") detail["newstime"]=date_source[1] detail["newsfrom"]=date_source[3] #也可以使用正则表达式来抽取信息,解析同2.1的函数中正则模块 #print(date_source.prettify()) r=re.compile("(\d{4}年\d{2}月\d{2}日 \d{2}:\d{2})") re_newstime=r.findall(date_source.text) detail["re_newstime"] =re_newstime.text return detail
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3.3、编写存储模块
编写一个函数,使用codecs包,将抽取后的信息存入到指定位置的文件中
#函数名称:savenews; 所需参数:data(要保存的数据),new(存入的文件名称)
def savenews(data,new): fp = codecs.open('.\\sinaNews\\'+new+'.txt', 'a+', 'utf-8') fp.write(json.dumps(data, ensure_ascii=False)) fp.close()
- 1
- 2
- 3
- 4
- 5
3.4、编写爬虫主题
利用以上编写好的两个模块,运行爬虫
1、设置全局变量
#初始化全局的变量
#使用ScalableBloomFilter模块,对获取的URL进行去重处理
urlbloomfilter=ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
page = 1 #设置爬虫初始爬取的页码
error_url=set() #创建集合,用于存放出错的URL链接
- 1
- 2
- 3
- 4
- 5
2、获取URL
- 获取URL 由于本案例中的新浪新闻网页
是动态网页,所以不能直接对此网页进行爬取。需要通过开发者工具,查看该网页的NetWork,找到该网页的API接口URL,并以此作为初始URL进行爬取。通过拼接参数’page’来控制爬取页数。 - 使用循环控制爬虫,并调用之前编写好的抽取模块和存储模块,运行爬虫
1、使用BeautifulSoup抽取模块和存储模块
#使用BeautifulSoup抽取模块和存储模块
#设置爬取页面的上限,由于仅用于案例展示,所以此处只爬取前一页的新闻数据
while page <= 1: #以API为index开始获取url列表 data = requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page="+str(page)) #拼接URL,并获取索引页面信息 if data.status_code == 200: #当请求页面返回200(代表正确)时,获取网页数据 #将获取的数据json化 data_json = json.loads(data.content) news=data_json.get("result").get("data") #获取result节点下data节点中的数据,此数据为新闻详情页的信息 #从新闻详情页信息列表news中,使用for循环遍历每一个新闻详情页的信息 for new in news: # 查重,从new中提取URL,并利用ScalableBloomFilter查重 if new["url"] not in urlbloomfilter: urlbloomfilter.add(new["url"]) #将爬取过的URL放入urlbloomfilter中 try: #print(new) #抽取模块使用bs4 detail = getdetailpagebybs(new["url"]) #存储模块 保存到txt #savenews(detail,new['docid'][-7:])################################################################# except Exception as e: error_url.add(new["url"]) #将未能正常爬取的URL存入到集合error_url中 page+=1 #页码自加1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2、使用lxml抽取模块和存储模块
while page <= 1: #以API为index开始获取url列表 data = requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page="+str(page)) #拼接URL,并获取索引页面信息 if data.status_code == 200: #当请求页面返回200(代表正确)时,获取网页数据 #将获取的数据json化 data_json = json.loads(data.content) news=data_json.get("result").get("data") #获取result节点下data节点中的数据,此数据为新闻详情页的信息 #从新闻详情页信息列表news中,使用for循环遍历每一个新闻详情页的信息 for new in news: # 查重,从new中提取URL,并利用ScalableBloomFilter查重 if new["url"] not in urlbloomfilter: urlbloomfilter.add(new["url"]) #将爬取过的URL放入urlbloomfilter中 try: #print(new) #抽取模块使用lxml detail=getdetailpagebylxml(new["url"]) #存储模块 保存到txt #savenews(detail,new['docid'][-7:])####################################################### except Exception as e: error_url.add(new["url"]) #将未能正常爬取的URL存入到集合error_url中 page+=1 #页码自加1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
四、完整代码
import codecs #用来存储爬取到的信息
from pybloom_live import ScalableBloomFilter # 用于URL去重的
import requests #用于发起请求,获取网页信息
import json #处理json格式的数据
from bs4 import BeautifulSoup as bs #用于数据抽取
import re #正则语言类库
def getdetailpagebybs(url): detail = {} # 创建一个字典,存放URL、title、newstime等信息 detail["url"] = url # 将URL时间存入detail字典中的相应键值中 page = requests.get(url).content # 使用requests.get方法获取网页代码,由于bs4可以自动解码URL的编码,所以此处不需要decode html = bs(page, "lxml") # 使用lxml解析器 title = html.find(class_="main-title") # 获取新闻网页中的title信息,此处网页中只有一个“class=main-title”,所以使用find即可 print(title.text) # 展示新闻标题 detail["title"] = title.text # 将新闻标题以文本形式存入detail字典中的相应键值中 artibody = html.find(class_="article") # 使用find方法,获取新闻网页中的article信息 print(artibody.text) detail["artibody"] = artibody.text # 。。。。。。。 date_source = html.find(class_="date-source") # 使用find方法,获取新闻网页中的date-source信息 # 由于不同的新闻详情页之间使用了不同的标签元素,直接抽取可能会报错,所以此处使用判断语句来进行区分爬取 if date_source.a: # 判断date-source节点中是否包含有'a'元素 print(date_source.span.text) detail["newstime"] = date_source.span.text # 抽取'span'标签中时间信息 print(date_source.a.text) detail["newsfrom"] = date_source.a.text # 抽取'a'标签中新闻来源信息 else: print(date_source("span")[0].text) detail["newstime"] = date_source("span")[0].text # 抽取'span'标签中包含的时间信息 print(date_source("span")[1].text) detail["newsfrom"] = date_source("span")[1].text # 抽取'span'标签中包含的新闻来源信息 return detail # 函数返回值为存放抽取信息的字典
def savenews(data,new): fp = codecs.open('D:/sinaNews/'+new+'.txt', 'a+', 'utf-8') fp.write(json.dumps(data, ensure_ascii=False)) fp.close()
#使用ScalableBloomFilter模块,对获取的URL进行去重处理
urlbloomfilter=ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
page = 1 #设置爬虫初始爬取的页码
error_url=set() #创建集合,用于存放出错的URL链接
#使用BeautifulSoup抽取模块和存储模块
#设置爬取页面的上限,
while page <= 10: #以API为index开始获取url列表 data = requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page="+str(page)) #拼接URL,并获取索引页面信息 if data.status_code == 200: #当请求页面返回200(代表正确)时,获取网页数据 #将获取的数据json化 data_json = json.loads(data.content) news=data_json.get("result").get("data") #获取result节点下data节点中的数据,此数据为新闻详情页的信息 #从新闻详情页信息列表news中,使用for循环遍历每一个新闻详情页的信息 for new in news: # 查重,从new中提取URL,并利用ScalableBloomFilter查重 if new["url"] not in urlbloomfilter: urlbloomfilter.add(new["url"]) #将爬取过的URL放入urlbloomfilter中 try: print(new) #抽取模块使用bs4 detail = getdetailpagebybs(new["url"]) #存储模块 保存到txt savenews(detail,new['docid'][-7:])################################################################# except Exception as e: error_url.add(new["url"]) #将未能正常爬取的URL存入到集合error_url中 page+=1 #页码自加1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
结果如下:


各位路过的朋友,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论,指正错误,也欢迎有问题的小伙伴评论留言,私信。每个小伙伴的关注都是本人更新博客的动力!!!
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105253382

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)