GaussDB(DWS)之数据库对象设计

GaussDB(DWS)之数据库对象设计
1、根据应用逻辑设计数据库
根据业务逻辑,抽象出表定义,表其实就是描述了实体的各个属性;根据业务逻辑,判断表在数据库中的存储方式;优化表定义和查询语句;
2、行存储和列存储的特点
能够根据数据特征自适应的选择压缩算法,平均压缩比7:1;根据预置的时间策略对数据自动压缩;
压缩数据可通过数据库接口继续访问,压缩过程对应用透明;压缩数据可直接访问,对业务透明,无需导入导出,极大缩短历史数据访问的准备时间;
- 优点:数据库性能瓶颈经常集中在磁盘I/O,数据压缩后,读取数据时,相对于压缩解压,减少I/O能够更好地提高性能;

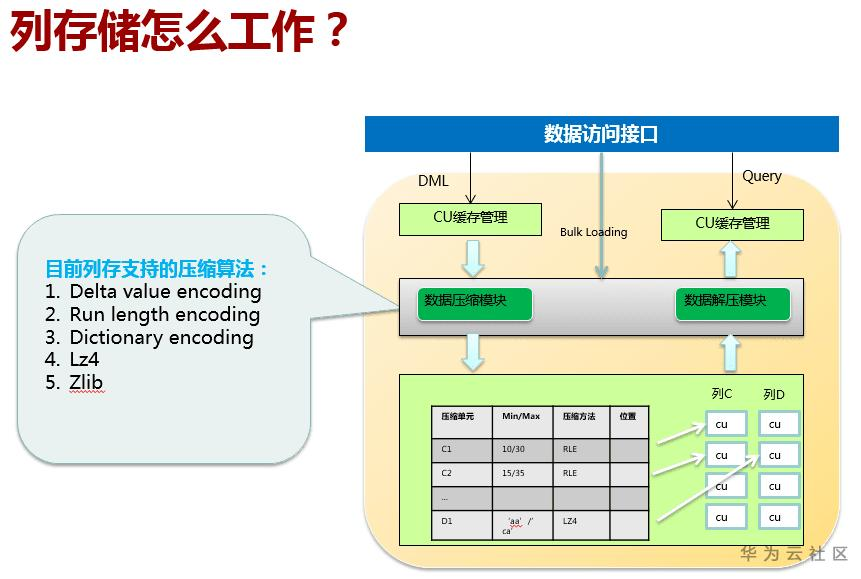

3、选择行存还是列存
- 列存适合的场景:统计分析类查询(group,join多的场景);即兴查询(查询条件列不确定,行存无法确定索引);
- 行存适合的场景:点查询(返回记录少,基于索引的简单查询);增删改比较多的场景;
4、数据分布方式
复制Replication方式;散列Hash方式
- 复制(Replication)方式 - 将表中的所有数据复制到集群中每一个DN实例上,主要适用于记录集较小的表(10W行记录以下);
- 散列(Hash)方式 - 将表中指定字段进行hash运算后,生成对应的hash值,根据DN实例与哈希值的映射关系获得该元组的目标存储位置,适用于数据量较大的表;

5、数据分布策略
分布存储和并发查询是MPP架构数据库的主要优势所在,将一个大数据量表中的数据,按合适分布策略分散存储在多个DN实例内,可极大提升数据库性能;
6、分布列的选择
- 尽量选择distinct值比较多的列,保证数据均匀分布,分布均匀是为了避免木桶效应,让各个主机对等执行;
- 尽量选择Join列或group 列做分布列,尽量选择Join列或group列是为了避免DN之间数据流动, 提高性能;
- 尽量不要选择filter列作为分布列;
- 不同DataNode的数据量相差5%以上即可视为倾斜,如果相差10%以上就必须要调整分布列;
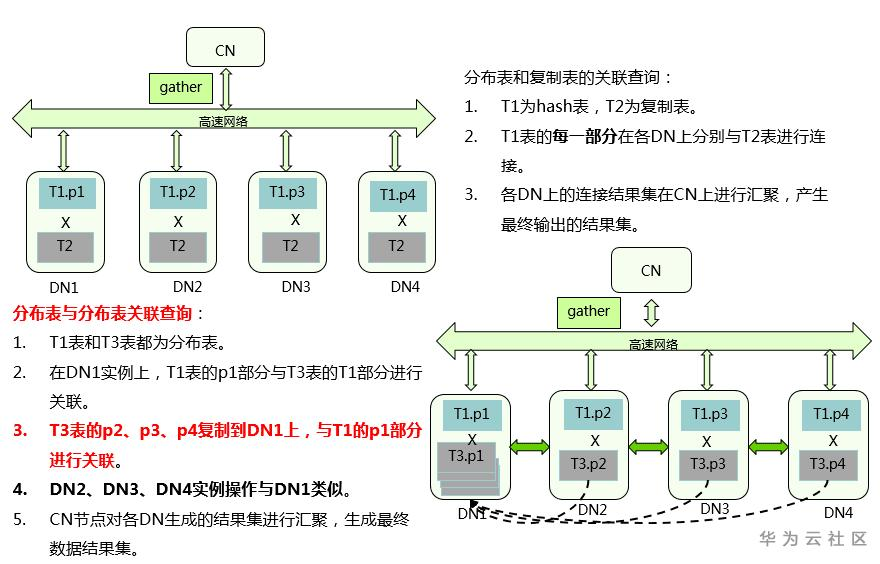
7、分布表和复制表的关联查询
T1为hash表,T2为复制表:T1表的每一部分在各DN上分别与T2表进行连接 -> 各DN上的连接结果集在Coordinator上进行汇聚,产生最终输出的结果集;
8、分布表与分布表关联查询
T1表和T3表都为分布表:在DN1实例上,T1表的part1部分与T3表的T1部分进行关联 -> T3表的part2、part3、part4复制到DN1上,与T1的part1部分进行关联 -> DN2、DN3、DN4实例操作与DN1类似 -> Coordinator节点对各DN生成的结果集进行汇聚,生成最终数据结果集;
9、分区剪枝
分区表是将大表的数据分成称为分区的许多小的子集;
- 好处:基于时间的查询分区枝剪可以大大提高查询性能;数据容易管理;
- 建议:业务表一般按照时间或地区做Range分区

10、索引介绍
索引是对数据库表中一列或多列的值进行排序的一种结构;使用索引可快速访问数据库表中的特定信息;
分类:行存表索引/列存表索引
- 行存表索引 - B-Tree索引:适合数据重复度低的数据字段, 例如 身份证号码 等字段;
*B-Tree索引 - 优点:有B-tree索引,就像翻书目录一样,可以通过索引直接定位到要查询的数据(减少了I/O操作);另外查询性能与表中数据量无关;
*注意:不适合键值重复率较高的字段上创建B-Tree索引;
- 列存表索引 - PCK索引(Partial Cluster Key 局部聚集):一种针对列存的约束条件;一般在建表时创建,在数据导入时,根据约束,在列存存储单元(CU)内对数据做聚集;
*Psort索引:一种列存局部索引,对列存存储单元(CU)内的数据,创建局部索引(MIN/MAX index稀疏索引),提高查询效率;
*PCK索引 - 注意:先创建后使用,之前入库的数据不会自动根据索引聚集;



11、如何选择索引
行存选择索引注意事项:
- 查询条件列上创建B-tree index, 也可以创建组合索引, distinct值比较少的列不适合建立index;
- 行存不适合建立太多B-tree index, 然后做数据导入,这样的导入性能非常差; 一般这种情况需要禁用该表的索引,待数据导入后重建index;
列存选择索引注意事项
- 查询条件出现最多的列,例如filter条件或者join列上建立partial cluster key(约束);
- 条件列上可以建立psort index, 也可以创建组合索引;

- 点赞
- 收藏
- 关注作者
评论(0)