"华为云杯"2019人工智能创新应用大赛优胜奖方案分享-郭老师的弟子团队

关于本次大赛的经验分享,主要可以分为以下几个方面
一、数据分析
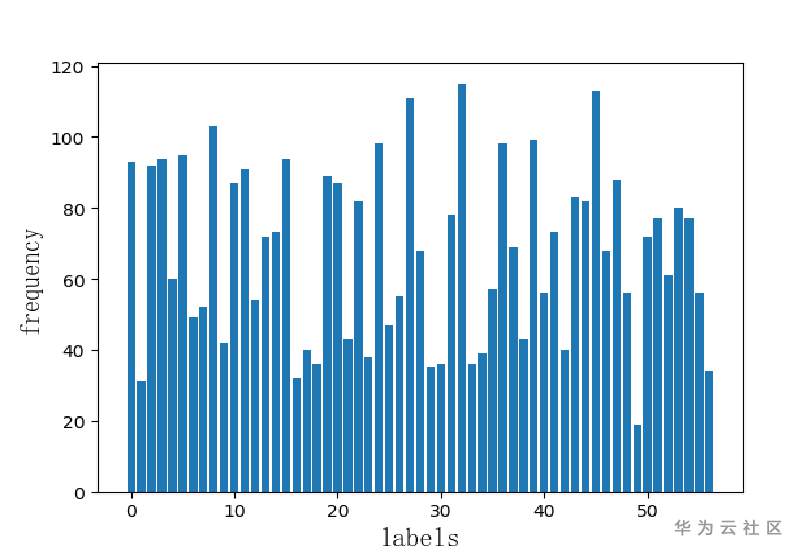
数据共57个类别,3848张图片,类别间存在数据不均衡问题。
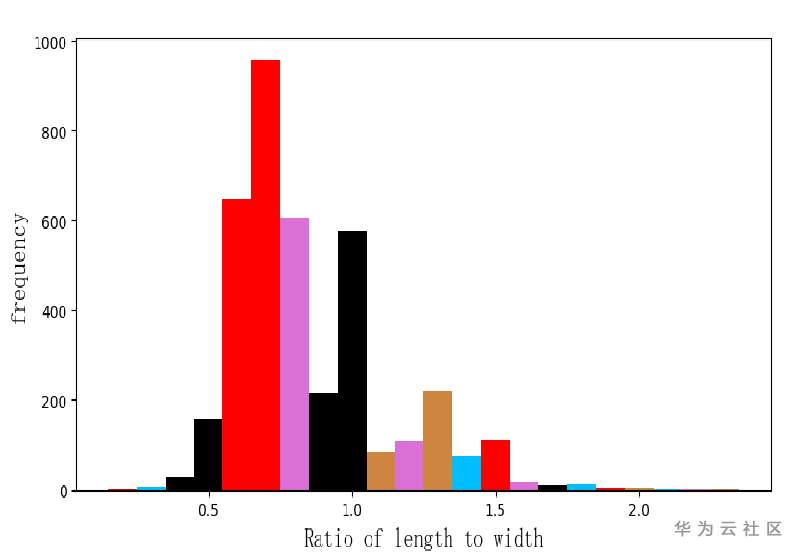
存在一些长宽比过度偏离1的数据,针对这些图片进行相应目标区域的裁剪。
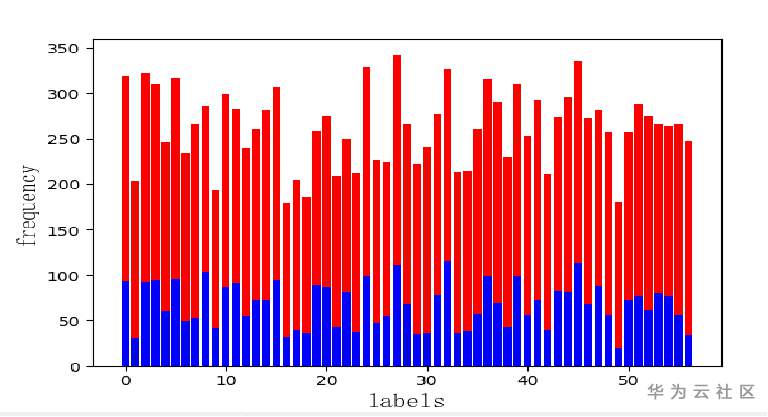
个别类别间存在细粒度问题,例如红色的皮影和剪纸,小炒泡馍和葫芦头泡馍,针对这些困难类别着重做了数据扩充。

数据扩充:
数据来源:通过爬虫从谷歌,百度上爬取数据。
扩充的准则:对官方数据集训练一个模型,利用该模型选出爬取数据中置信度较高的数据,
对每个类别进行有差异的扩充,不断迭代更新数据集。
二、数据增强
1、HorizontalFlip 水平翻转
2、ColorJitter 亮度,饱和度,对比度变化
3、RandomResizeCrop 随机裁剪缩放
4、RandomErasing 随机遮挡
5、Cutmix 剪切粘贴patch块
6、Sharpen 随机图像锐化

三、模型选择
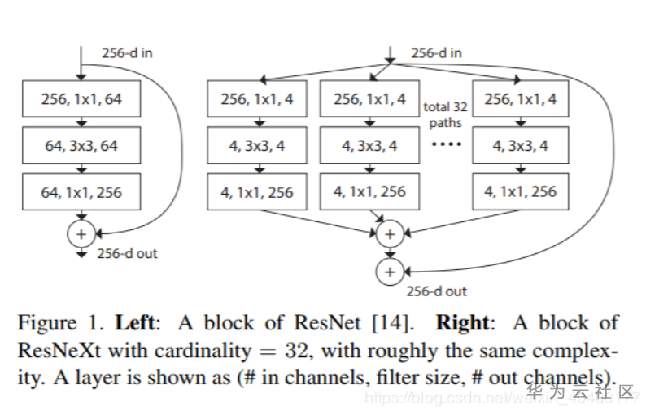
模型选用的是resnext101 32×4d
尝试了添加空间注意力,全连接替换成KNN,Arcface等方法,但均未提高精度。
四、超参数设置
预训练参数:Imagenet-1k
损失函数:CrossEntropyLoss + Label Smoothing
优化器:SGD
学习率:初始0.01,每5个epoch lr*0.7
迭代次数:30~40 epoch
图像大小:训练RandomResizeCrop(384)
测试Resize(540)+CenterCrop(512)
因为数据增强采用了RandomResizeCrop ,相当于对图像进行拉伸,所以训练采用小尺寸,测试采用大尺寸。
五、应用
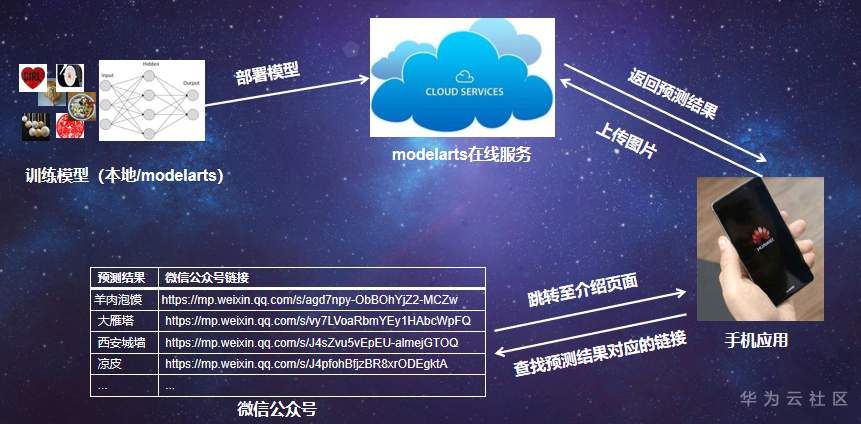
我们采用的是微信小程序,把模型部署在云端,调用云端gpu,实现快速预测,解决了移动端算力不足的问题,并且如果修改模型,
只需要在云端修改,即可实现移动端和云端的同步,方便管理。
六、总结
1、数据很大程度地决定了最后的精度,所以对爬虫数据的选择很重要, 应该多针对错误样本对数据集进行扩充和调整。
2、在实验中大幅度提升精度的方法有RandomResizeCrop,Random Erasing,合适的训练尺寸,提高测试分辨率。
3、训练时应该设置随机种子,保证结果可复现,并且在尽量控制变量的基础上逐步添加trick,记录好实验结果。

- 点赞
- 收藏
- 关注作者
评论(0)