不知道女神斯嘉丽约翰逊演过哪些电影?知识图谱告诉你(华为云知识图谱服务-信息抽取模型实践)

每个男人心中都有一个女神。比如,NBA现役球星杜兰特就曾公开宣布自己喜欢斯嘉丽·约翰逊,2011年的金球奖颁奖礼,当美国好莱坞女星斯嘉丽·约翰逊走在红地毯上的时候,杜兰特忍不住地发了条Twitter:“斯嘉丽,我想喝你的洗澡水。” But,即便杜兰特如此痴迷斯嘉丽,他也记不住斯嘉丽的所有作品和作品信息。
此次实践使用华为云-知识图谱服务,训练一个电影领域的自定义信息抽取模型,并进一步输入自然语言文本,从中抽取三元组,构建一个电影知识图谱。轻松查询斯嘉丽主演过哪些电影,以及曾和哪些导演合作。
建议先熟悉华为云知识图谱服务文档,了解使用流程和相关概念:https://support.huaweicloud.cn/productdesc-kg/kg_02_0001.html
图谱构建流程:

华为云知识图谱目前还在公测当中,使用免费,直接申请公测即可。获得公测资格后,会有短信通知。
tips:准确填写个人信息,清楚描述自身业务场景,可以更快获得公测资格~
1. 准备数据
首先需要准备一批短文本数据,可以按一定比例划分为训练数据(标注进而训练模型)和图谱数据(最终构建图谱的数据)。由于数据安全的原因,视频中的示例数据不能跟大家分享、展示。数据示例:
张三的生日是1990年1月1日,身高175cm,出生于北京。
李四,著名导演,毕业于电影学院,代表作有《电影1》、《电影2》。
... ...
将数据上传到OBS(华为云对象存储服务)后,就可以开始标注数据了。
FAQ:
(1) 什么是数据集输入位置和数据集输出位置?
答:选择的是OBS文件夹。
数据集输入位置:待标注的数据存放在OBS的目录。
数据集输出位置:标注完成的数据存放到OBS的目录。
(2) 如何填写实体标签和关系标签?它和图谱本体有什么关系?
答:实体标签和关系标签是指定我们这批数据里面有哪些类型的实体和关系,比如我们只有新增了“电影”这个实体标签后,在标注时才能将待标注数据的某一段文字标注成“电影”。实际上是在设置我们抽取出的三元组的schema。
这里填写的标签,和图谱本体是独立的两个东西。它只是约束我们从这批数据中抽取出的三元组有哪些类型,之后这些三元组还需要经过“知识映射”阶段的配置,与本体进行“映射”,才能生成图谱。
(3) 需要标注多少条数据?
答:训练一个基本可用的模型,大约需要2000条左右的短句数据作为训练数据。训练一个效果较好的模型,建议提供2万条以上的短句数据作为训练数据。可以启用modelarts平台团队标注的功能,对一批数据进行团队标注。
2. 模型训练
标注好数据后,就可以开始训练模型。
FAQ:
(1)训练模型时为什么选文件夹而不是文件?
答:一个文件夹中可能有多个文件,这些文件都可以被当做训练数据。所以选择某个文件夹,则其中存放的符合格式的文件都会被当做训练数据使用。
(2)训练模型时的训练集、测试集如何划分的?
答:默认会随机划分80%的数据作为训练集,20%的数据作为测试集。
3. 创建图谱
训练好模型后,开始创建图谱。
FAQ:
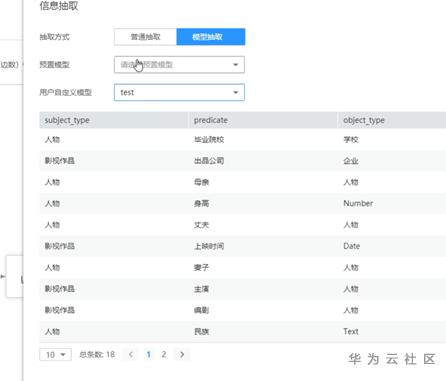
(1)信息抽取使用模型抽取时,知识映射该怎么配?怎么和信息抽取的内容结合起来?
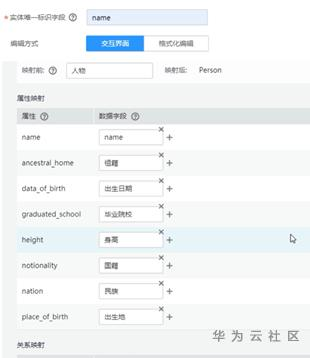
答:信息抽取阶段选择模型抽取时,其下方会展示抽取出的三元组的schema。这个schema其实就是我们在步骤1(标注数据)时填写的数据标签。我们在配置“知识映射”时,主要是将“信息抽取”阶段的predicate填入对应栏目。比如将“身高”填入到“Person”这类实体的“height”属性。则在生成图谱中某个“Person”类实体时,信息抽取阶段中:“身高”对应的object_type“Number”这个字段就会成为该实体的“height”属性。此次示例的视频有剪辑,跳过了配置的完整过程,直接展示的配置填写完后的结果。
4. 结果展示
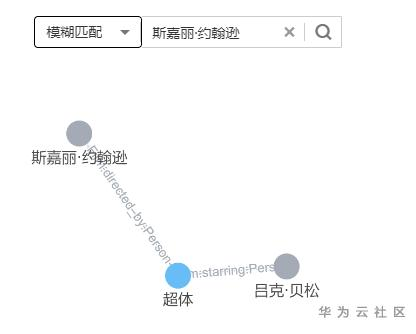
运行一段时间后,图谱就构建好了。在图谱中搜索斯嘉丽,可以看到她曾主演电影《超体》,该电影的导演是吕克贝松。
往期相关博文:
华为云知识图谱服务--结构化数据实践(上):https://bbs.huaweicloud.cn/blogs/167526
华为云知识图谱服务--结构化数据实践(下):https://bbs.huaweicloud.cn/blogs/167528

- 点赞
- 收藏
- 关注作者
评论(0)