【AI理论】关于知识蒸馏,这三篇论文详解不可错过

一. Neuron Selectivity Transfer

本文将teacher-student的knowledge transfer过程看作两者对应feature distribution matching,使用domian adaptation 常用方法MMD(最大平均差异)进行优化。(知识蒸馏本是一种同任务迁移学习)
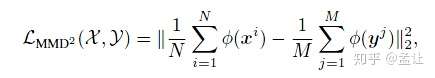
相关概念
I. Maximum Mean Discrepancy
简而言之,将两个分布映射到一个可度量距离的空间计算距离。计算距离的方法是,计算分布上每一个点映射到另一空间的距离然后求和。具体而言就是将两个分布映射到再生核希尔伯特空间(可以利用核技巧简化无穷维度内积计算),在这个RKHS中两个分布的距离用两个分布的核函数各点距离之和计算。
II. Kernel Trick 简而言之,存在低维到高维的映射;求解形式中只有映射的内积项,没有关于映射的奇数次项,所以可以使用Kernel Trick(以上只是充分条件)来简化高维映射的内积计算。使得高维变换+高维内积简化为低维内积计算。 核技巧与MMD结合:
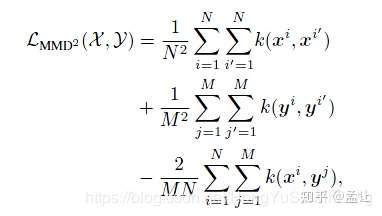
Motivations

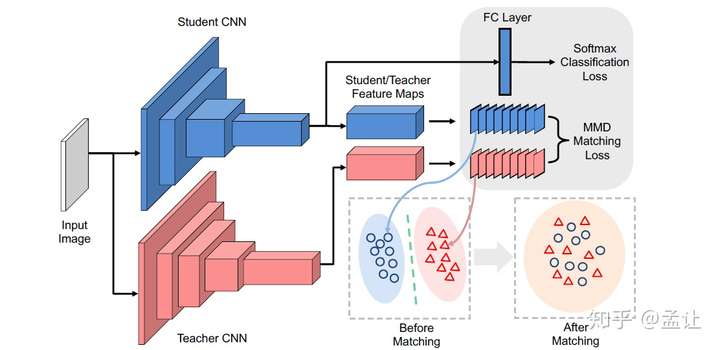
按照深度学习分布式特征的特点,每个神经元按照任务从输入提取某(几)种特定的特征,这是神经元的选择性。反过来说如果一个神经元被某些样本或者图像某些区域激活(上图的猴脸和字符),那么这些区域/样本就是有共同语义特征的。所以本文的方法是使用MMD来使得student网络的神经元选择性特征分布(Neuron Selectivity Feature Distributions)mimic对应teacher的的这种分布。
下图是teacher-student框架:
方法
特征图的一个通道表示了一个神经元的选择性知识,神经元选择性传递(Neuron Selectivity Transfer)的损失函数是:
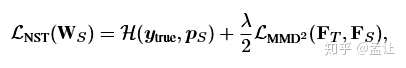
等号右边第一项是交叉熵,第二项是加入核技巧的平方最大平均差异损失,MMD LOSS如下:
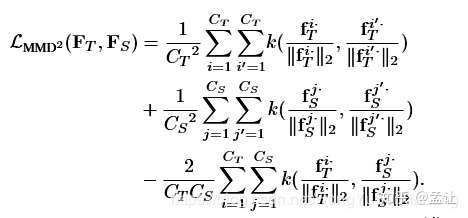
式中每个通道进行了L2正则化,之前研究表明是涨点很关键的一点。 关于不同核函数的选取是重头戏了,因为之前的工作Attention Transfer的损失函数可以理解为一种带线性核函数的MMD。带某个多项式核函数的MMD是在传递Gram矩阵。
1.带线性核函数的MMD
线性核
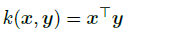
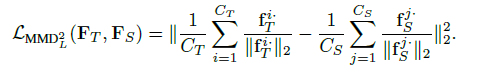
对比Attention Transfer loss:
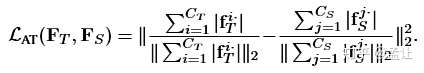
发现AT LOSS除了在正则化方式上的差别以外,是一种NTS的特例。
2.带多项式核的MMD
多项式核
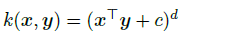
在d=2,c=0的时候有:
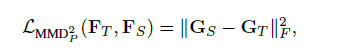
其中G为Gram矩阵,各元素为
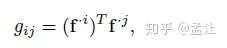
该gram矩阵表示嵌入空间的空间相似度(前提是需要通道正则化)。
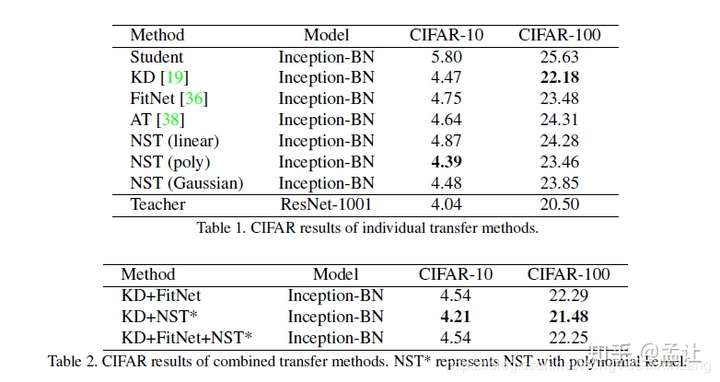
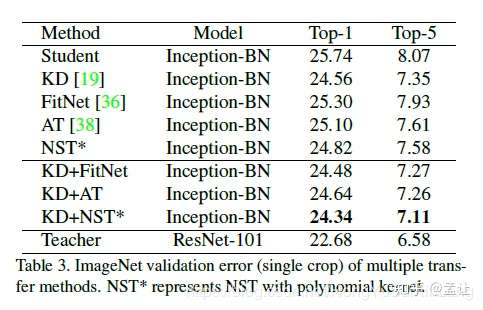
实验
teacher:ResNet1001
student:Inception-BN
不同核函数的NTS以及不同知识蒸馏方法对比如下:
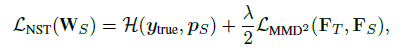
二. Knowledge Distillation with Conditional Adversarial Networks

对于一般KD的teacher-student框架来讲,除了需要有一个pre-trained的student网络以及一个suboptimal的student网络之外,技术的关键还在于需要传递的知识形式以及传递所需的衡量标准--KD损失函数。最原始的KD损失是soft label的KL散度,之后大多数是抽取中间层特征以某种形式进行传递。 损失函数对于深度学习的重要性不言而喻。自然而言就想到了很厉害的一种可学习损失函数——GAN。 teacher-student框架,是studen对teacher的模仿的过程。那么,即使任务是分类,判别任务,也可以将student网络看作一个生成器,产生对于输入的logits。这个logits 使用soft label的方法来模仿student。这时候加入一个判别器,作用是甄别logits出自teacher还是student。这种生成-对抗的推拉之下,使得student很好的学到了来自teacher的知识,完成知识蒸馏。
方法
1. 一般的知识蒸馏
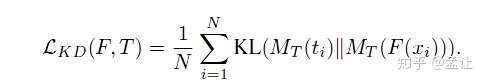
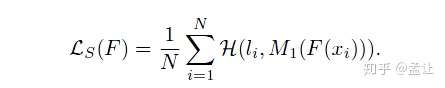
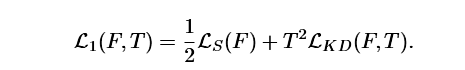
F( )是student,t是teacher,MT是soft label方法。
2. CGAN teacher-student整体框架
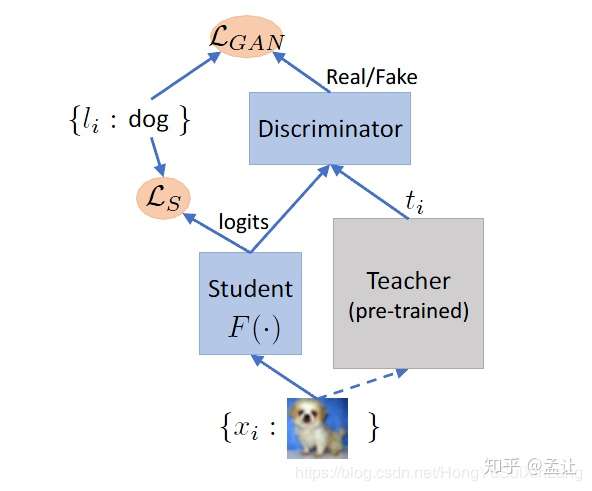
3. Discriminator
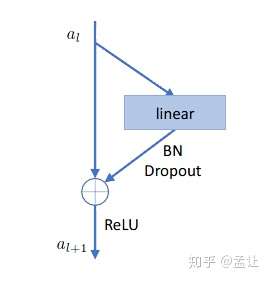
使用残差结构的MLP作为Discriminator,训练Disc的损失函数是二值交叉熵
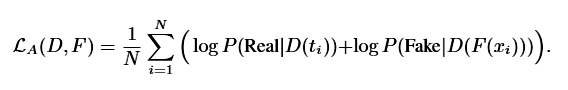
当然也可以使用宣称收敛最易的LSGAN:
disc_loss = (tf.reduce_mean((disc_t - 1)**2) + tf.reduce_mean((disc_s - 0)**2))/2. gen_loss = tf.reduce_mean((disc_s - 1)**2)
但是不好意思,训练依然比较难。
按照Auxiliary Classifier GANs的思路,在判别器中也施加类别信息作条件,判别器的输出是一个C+2维的向量。C是类别数目。
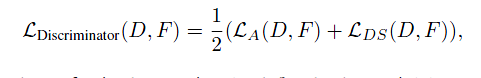
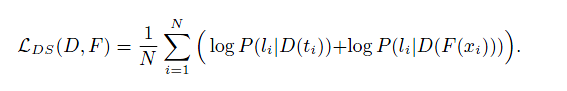
然后假设:类别条件和logits出自teacher or student是独立的,训练得出C+2维度的概率输出。
4. Generator
Auxiliary Classifier提供了类别信息,为了获得实例级别的知识作条件,使用L1loss来对其teacher-student的logits.所以总loss:
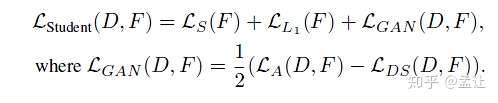
5. 训练过程
先固定student,用Discriminator Loss优化D;然后用Student Loss来优化Student。
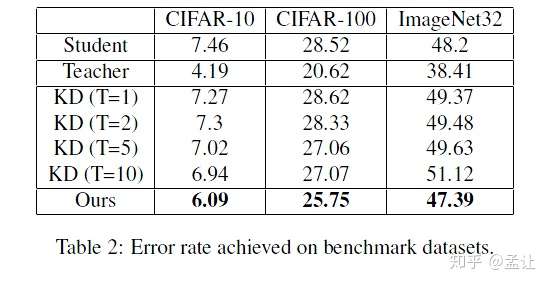
实验
teacher:WRN-40-10
student: WRN-10-4(CIFAR)/WRN-22-4(Imagenet32)
三. Mutual Learning & Born Again NN
两篇不以模型压缩为目的应用知识蒸馏的文章

Deep Mutual Learning VS Knowledge Distillation
Deep Mutual Learning(DML)与用于模型压缩的一般知识蒸馏不同的地方在于知识蒸馏是将预训练好的、不进行反向传播的“静态”teacher网络的知识单项传递给需要反向传播的"动态"student网络。DML是在训练过程中,一众需要反向传播的待训student网络协同学习,互相传递知识。所以区别就在是否teacher、student网络都需要反向传播。
方法
DML框架如下
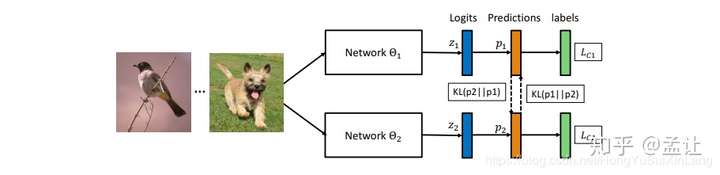
每个互相学习的网络都有一个标准的分类Loss和互学习Loss,其中互学习Loss是一个KL散度。 具体而言,两个网络的softmax输出为p1,p2.则互学习的意义在于,对于Net1(Net2亦然),对了提高其泛化能力,使用Net2的p2作为一种后验概率,然后最小化p1,p2的KL散度。从p1到p2的KL距离如下
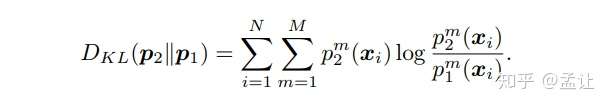
所以,Net1的损失函数是交叉熵加上p1到p2的KL散度:
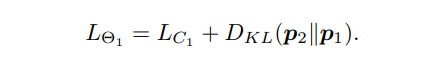
Net2的是p2到p1的距离:
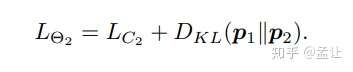
如果是多个网络,比如K>2个网络互相学习,则每个student网络的Loss:
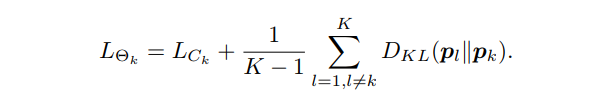
还有一种方法就是对于每个student,使其模仿其他student网络softmax输出之平均。不过该方法会因为多个网络softmaxgailv取平均导致gt class分量很大,不够soft,有违文章提到的提供后验熵的初衷。
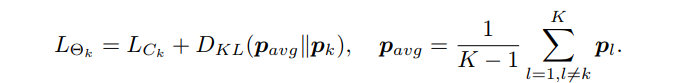
文章给出的优化过程是异步的。即先对不同网络进行不同的初始化,然后各网络同时前传得到softmax概率,继而每个网络在分类+互学习loss作用下逐个反传。
实验
实验所有模型如下:

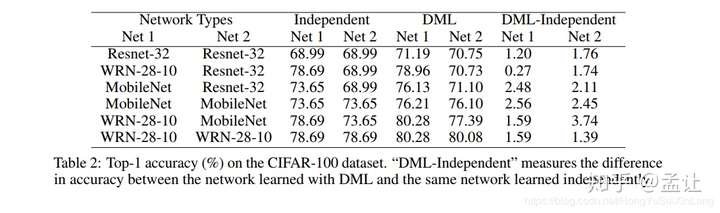
在CIFAR100数据集结果
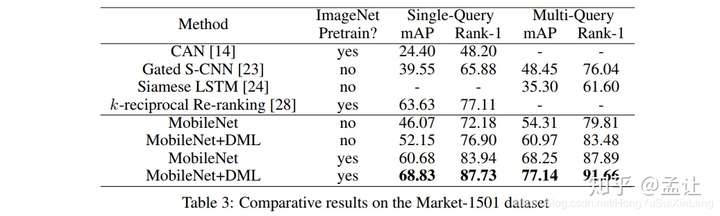
在Market-1501 Re-id结果
和单向传递知识的知识蒸馏相比
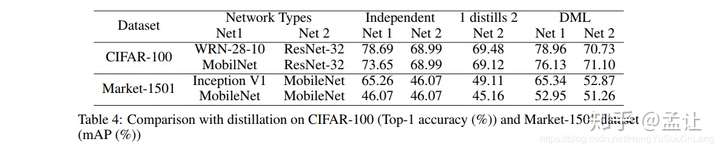
最后实验还发现互相学习的网络多一些可以涨点
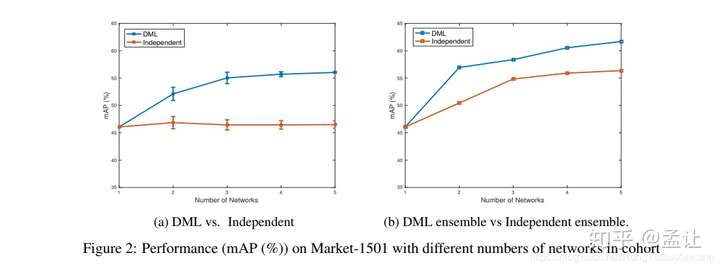
理论解释
每个网络都有交叉熵在训练,接受one-hot类别监督信息从而收敛到最小值点minina(训练损失为0)。但是各网络这种情况下的minima是不够稳定的。由于每个student网络初始化不一样,预测的类别向量第一分量是标准答案了,但是第二分量各不相同,还是和蒸馏一样,这种第二分量作为后验熵互相提供了丰富的信息,使得网络找到了较为宽广的、就是很鲁棒的最小值点,结果就是泛化能力提升。
再生网络

方法
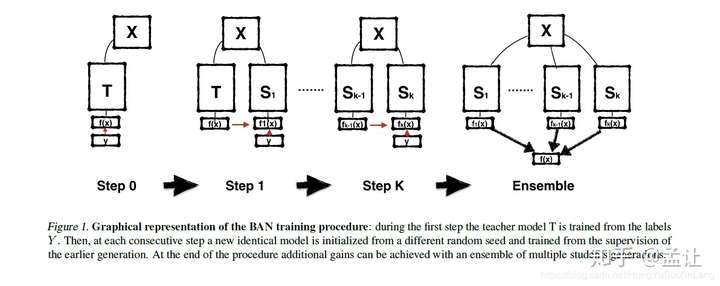
如上图,直接将teacher网络的prediction当作student网络的target,得到第一代student网络的prediction,然后传递给后一代,历经几代之后,将各代student网络的prediction ensemble.形成一个sequence of teaching selves。 对于分类任务,X是输入,Y是输出的predictions,我们的网咯就是在拟合这样一个映射f(x):X->Y。学习参数的过程就是使用比如SGD来优化一个损失函数,通常是交叉熵。
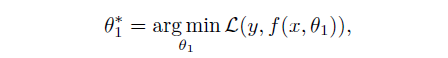
BANs就是替换这个交叉熵为:
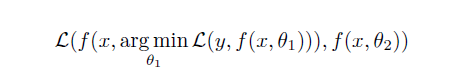
文章中还讨论了logits中非最大值分量的作用,使用teacher网络logit加权和非最大值分量打乱两种方法做了实验。

- 点赞
- 收藏
- 关注作者
评论(0)